

Explainable drug repurposing via path based knowledge graph completion
- PMID: 39025897
- PMCID: PMC11258358
- DOI: 10.1038/s41598-024-67163-x
Explainable drug repurposing via path based knowledge graph completion
Abstract
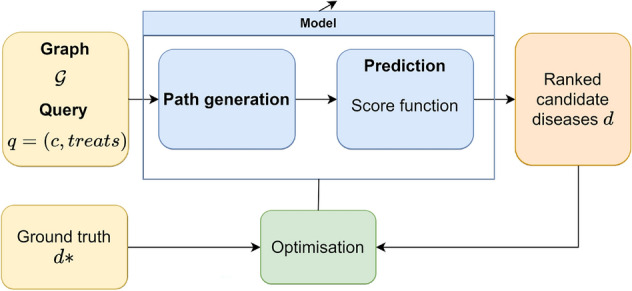
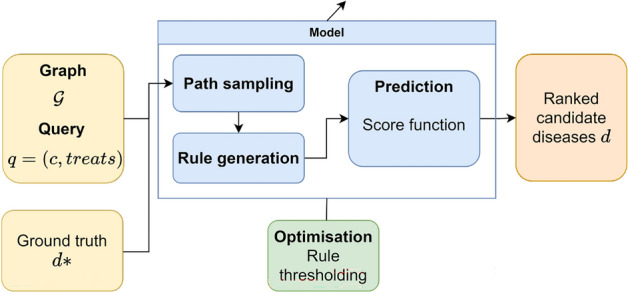
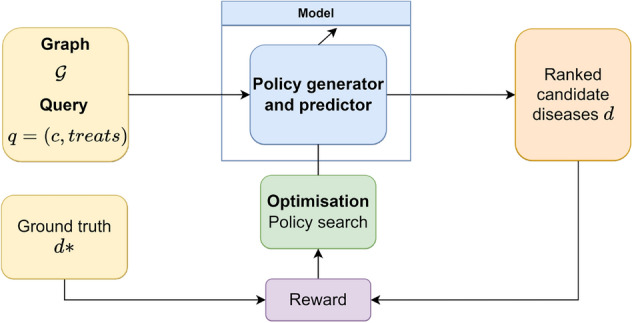
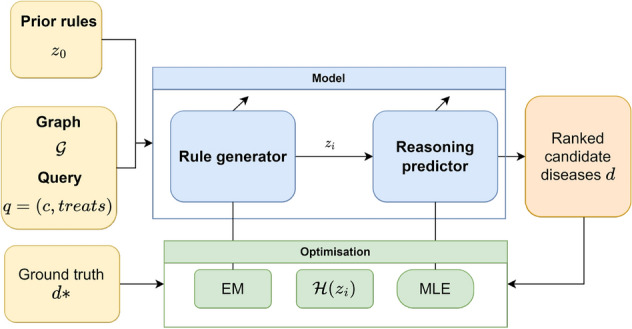
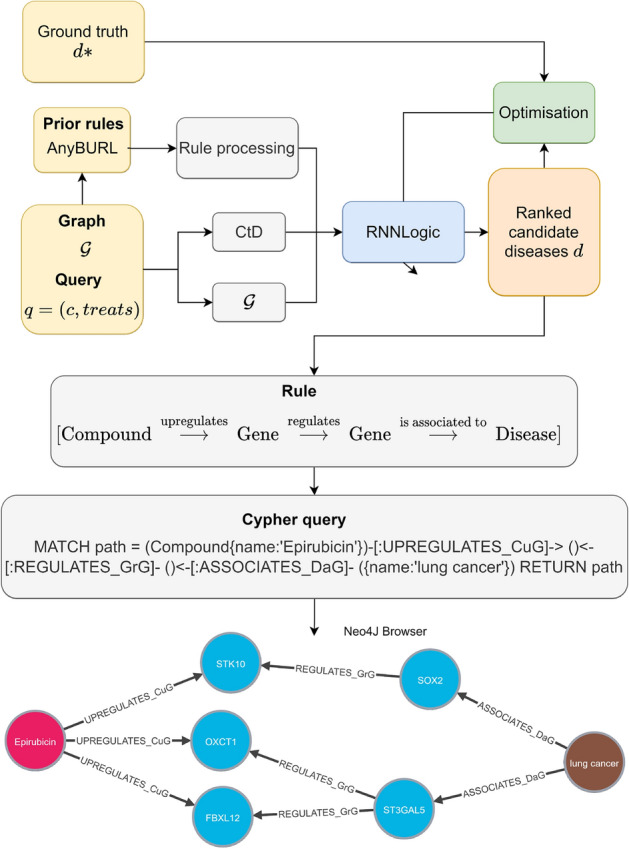
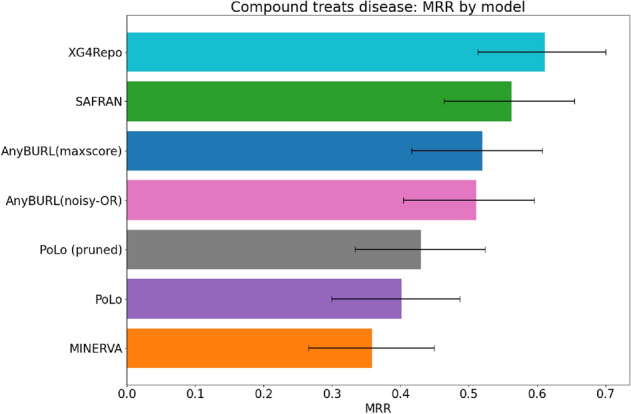
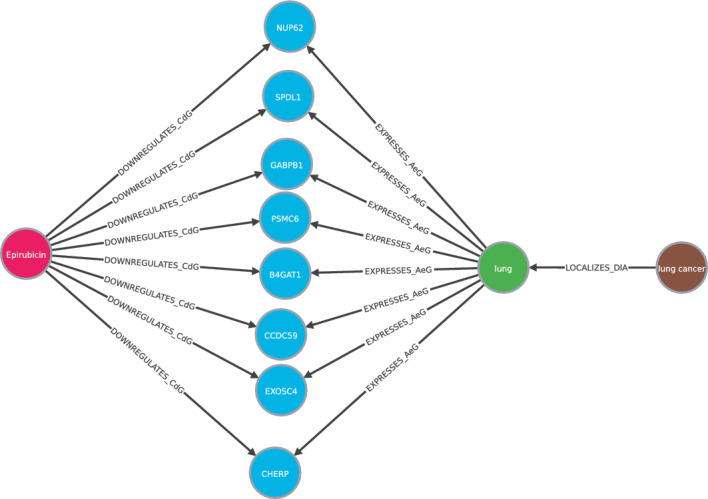
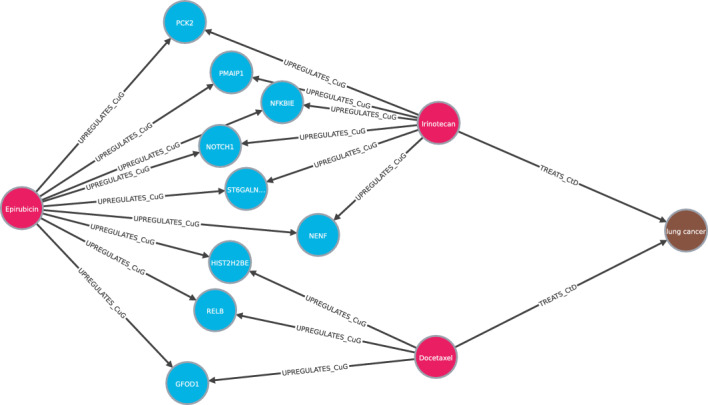
Drug repurposing aims to find new therapeutic applications for existing drugs in the pharmaceutical market, leading to significant savings in time and cost. The use of artificial intelligence and knowledge graphs to propose repurposing candidates facilitates the process, as large amounts of data can be processed. However, it is important to pay attention to the explainability needed to validate the predictions. We propose a general architecture to understand several explainable methods for graph completion based on knowledge graphs and design our own architecture for drug repurposing. We present XG4Repo (eXplainable Graphs for Repurposing), a framework that takes advantage of the connectivity of any biomedical knowledge graph to link compounds to the diseases they can treat. Our method allows methapaths of different types and lengths, which are automatically generated and optimised based on data. XG4Repo focuses on providing meaningful explanations to the predictions, which are based on paths from compounds to diseases. These paths include nodes such as genes, pathways, side effects, or anatomies, so they provide information about the targets and other characteristics of the biomedical mechanism that link compounds and diseases. Paths make predictions interpretable for experts who can validate them and use them in further research on drug repurposing. We also describe three use cases where we analyse new uses for Epirubicin, Paclitaxel, and Predinisone and present the paths that support the predictions.
Keywords: Drug repurposing; Heterogeneous knowledge graphs; Hetionet; Interpretability; Knowledge graph completion; Rule-based link prediction.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
Similar articles
-
Task-driven knowledge graph filtering improves prioritizing drugs for repurposing.BMC Bioinformatics. 2022 Mar 4;23(1):84. doi: 10.1186/s12859-022-04608-y. BMC Bioinformatics. 2022. PMID: 35246025 Free PMC article.
-
Knowledge Graphs for drug repurposing: a review of databases and methods.Brief Bioinform. 2024 Sep 23;25(6):bbae461. doi: 10.1093/bib/bbae461. Brief Bioinform. 2024. PMID: 39325460 Free PMC article. Review.
-
Drug Repurposing using consilience of Knowledge Graph Completion methods.bioRxiv [Preprint]. 2024 Aug 10:2023.05.12.540594. doi: 10.1101/2023.05.12.540594. bioRxiv. 2024. PMID: 39149283 Free PMC article. Preprint.
-
Deep learning identifies explainable reasoning paths of mechanism of action for drug repurposing from multilayer biological network.Brief Bioinform. 2022 Nov 19;23(6):bbac469. doi: 10.1093/bib/bbac469. Brief Bioinform. 2022. PMID: 36347526
-
Knowledge graphs and their applications in drug discovery.Expert Opin Drug Discov. 2021 Sep;16(9):1057-1069. doi: 10.1080/17460441.2021.1910673. Epub 2021 Apr 12. Expert Opin Drug Discov. 2021. PMID: 33843398 Review.
Cited by
-
Bind: large-scale biological interaction network discovery through knowledge graph-driven machine learning.J Transl Med. 2025 Jul 31;23(1):856. doi: 10.1186/s12967-025-06789-5. J Transl Med. 2025. PMID: 40745316 Free PMC article.
-
Universal multilayer network embedding reveals a causal link between GABA neurotransmitter and cancer.BMC Bioinformatics. 2025 Jun 2;26(1):149. doi: 10.1186/s12859-025-06158-5. BMC Bioinformatics. 2025. PMID: 40457205 Free PMC article.
References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
