

This is a preprint.
A study of animal action segmentation algorithms across supervised, unsupervised, and semi-supervised learning paradigms
- PMID: 39108294
- PMCID: PMC11302674
A study of animal action segmentation algorithms across supervised, unsupervised, and semi-supervised learning paradigms
Update in
-
A study of animal action segmentation algorithms across supervised, unsupervised, and semi-supervised learning paradigms.Neuron Behav Data Anal Theory. 2024;2024:10.51628/001c.127770. doi: 10.51628/001c.127770. Epub 2024 Dec 20. Neuron Behav Data Anal Theory. 2024. PMID: 40843338 Free PMC article.
Abstract
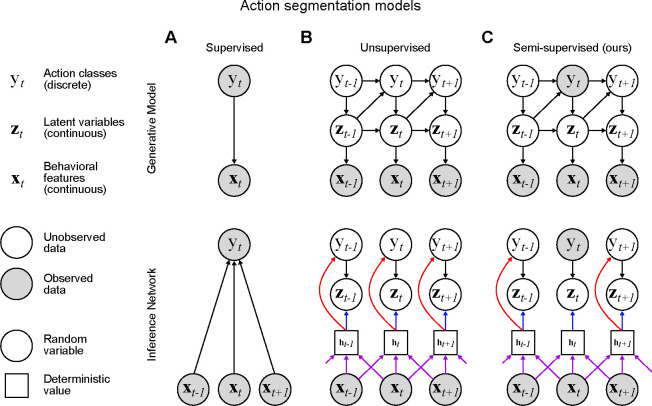
Action segmentation of behavioral videos is the process of labeling each frame as belonging to one or more discrete classes, and is a crucial component of many studies that investigate animal behavior. A wide range of algorithms exist to automatically parse discrete animal behavior, encompassing supervised, unsupervised, and semi-supervised learning paradigms. These algorithms - which include tree-based models, deep neural networks, and graphical models - differ widely in their structure and assumptions on the data. Using four datasets spanning multiple species - fly, mouse, and human - we systematically study how the outputs of these various algorithms align with manually annotated behaviors of interest. Along the way, we introduce a semi-supervised action segmentation model that bridges the gap between supervised deep neural networks and unsupervised graphical models. We find that fully supervised temporal convolutional networks with the addition of temporal information in the observations perform the best on our supervised metrics across all datasets.
Figures





References
-
- Ackerson G. A. and Fu K.-S. (1970) On state estimation in switching environments. IEEE Transactions on Automatic Control.
-
- Anderson D. J. and Perona P. (2014) Toward a science of computational ethology. Neuron, 84, 18–31. - PubMed
-
- Azabou M., Mendelson M., Ahad N., Sorokin M., Thakoor S., Urzay C. and Dyer E. (2024) Relax, it doesn’t matter how you get there: A new self-supervised approach for multi-timescale behavior analysis. Advances in Neural Information Processing Systems, 36.
-
- Batty E., Whiteway M., Saxena S., Biderman D., Abe T., Musall S., Gillis W., Markowitz J., Churchland A., Cunningham J. P. et al. (2019) Behavenet: nonlinear embedding and bayesian neural decoding of behavioral videos. Advances in Neural Information Processing Systems, 32.
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous