

This is a preprint.
Individualized Machine-learning-based Clinical Assessment Recommendation System
- PMID: 39108531
- PMCID: PMC11302612
- DOI: 10.1101/2024.07.24.24310941
Individualized Machine-learning-based Clinical Assessment Recommendation System
Update in
-
Individualized machine-learning-based clinical assessment recommendation system.PLOS Digit Health. 2025 Sep 25;4(9):e0001022. doi: 10.1371/journal.pdig.0001022. eCollection 2025 Sep. PLOS Digit Health. 2025. PMID: 40997045 Free PMC article.
Abstract
Background: Traditional clinical assessments often lack individualization, relying on standardized procedures that may not accommodate the diverse needs of patients, especially in early stages where personalized diagnosis could offer significant benefits. We aim to provide a machine-learning framework that addresses the individualized feature addition problem and enhances diagnostic accuracy for clinical assessments.
Methods: Individualized Clinical Assessment Recommendation System (iCARE) employs locally weighted logistic regression and Shapley Additive Explanations (SHAP) value analysis to tailor feature selection to individual patient characteristics. Evaluations were conducted on synthetic and real-world datasets, including early-stage diabetes risk prediction and heart failure clinical records from the UCI Machine Learning Repository. We compared the performance of iCARE with a Global approach using statistical analysis on accuracy and area under the ROC curve (AUC) to select the best additional features.
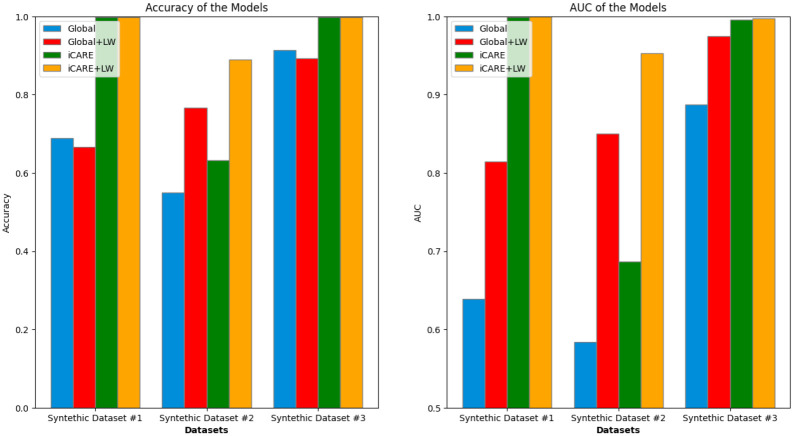
Findings: The iCARE framework enhances predictive accuracy and AUC metrics when additional features exhibit distinct predictive capabilities, as evidenced by synthetic datasets 1-3 and the early diabetes dataset. Specifically, in synthetic dataset 1, iCARE achieved an accuracy of 0·999 and an AUC of 1·000, outperforming the Global approach with an accuracy of 0·689 and an AUC of 0·639. In the early diabetes dataset, iCARE shows improvements of 1·5-3·5% in accuracy and AUC across different numbers of initial features. Conversely, in synthetic datasets 4-5 and the heart failure dataset, where features lack discernible predictive distinctions, iCARE shows no significant advantage over global approaches on accuracy and AUC metrics.
Interpretation: iCARE provides personalized feature recommendations that enhance diagnostic accuracy in scenarios where individualized approaches are critical, improving the precision and effectiveness of medical diagnoses.
Funding: This work was supported by startup funding from the Department of Psychology at the University of Kansas provided to A.A., and the R01MH125740 award from NIH partially supported J.M.G.'s work.
Figures











References
-
- N P, MB D, T P. BRCA1- and BRCA2-Associated Hereditary Breast and Ovarian Cancer. In: Adam MP, Feldman J, Mirzaa GM, et al. , eds. GeneReviews®. Seattle (WA): University of Washington, Seattle, 1993. http://www.ncbi.nlm.nih.gov/books/NBK1116/ (accessed July 13, 2024). - PubMed
Publication types
LinkOut - more resources
Full Text Sources