

doi: 10.1038/s41746-024-01208-3.
Evaluating multimodal AI in medical diagnostics
Affiliations
- PMID: 39112822
- PMCID: PMC11306783
- DOI: 10.1038/s41746-024-01208-3
Item in Clipboard
Evaluating multimodal AI in medical diagnostics
NPJ Digit Med.
.
Abstract
This study evaluates multimodal AI models' accuracy and responsiveness in answering NEJM Image Challenge questions, juxtaposed with human collective intelligence, underscoring AI's potential and current limitations in clinical diagnostics. Anthropic's Claude 3 family demonstrated the highest accuracy among the evaluated AI models, surpassing the average human accuracy, while collective human decision-making outperformed all AI models. GPT-4 Vision Preview exhibited selectivity, responding more to easier questions with smaller images and longer questions.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
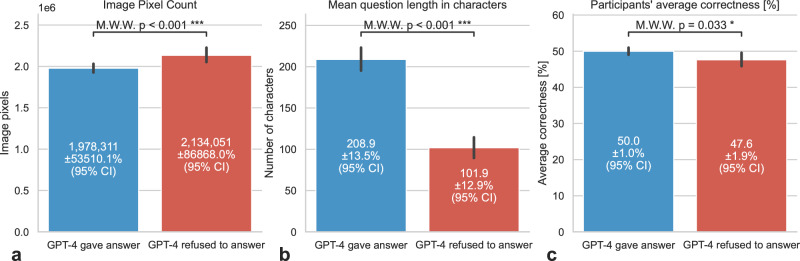
This bar plot illustrates the image mean pixel count (a), the mean question length measured in characters (b) and the participants’ average correctness (c) for questions with 95% confidence intervals where GPT-4V provided an answer compared to those where GPT-4V refused to answer. The data indicate that GPT-4V was more likely to give answers to easier questions, as evidenced by a higher average correctness among participants. Specifically, participants had an average correctness of 50.0% (±1.0% 95% CI) for questions answered by GPT-4V, compared to 47.6% (±1.9% 95% CI) for questions where GPT-4V did not provide an answer (p = 0.033). Moreover, the images in answered questions tend to have less pixels (p < 0.001) and the questions measured in number of characters are longer (p < 0.001). We have utilized the two-sided Mann-Whitney U-Test.

Comparison of a wide variety of multimodal models both, open-source models and proprietary models against the participants average and majority vote in the multiple-choice NEJM Image Challenge of 945 cases. The error bars depict 95% confidence intervals of the mean (a). The heatmap shows the pairwise comparisons of models and participants using the two-sided Mann-Whitney U-Test, with p-values adjusted for multiple comparisons using the Benjamini-Hochberg method. The mean difference in correct answers is annotated for significant comparisons, with p-values displayed underneath (b). Significance levels are indicated by color: dark green (p < 0.001), middle green (0.001 ≤ p < 0.01), light green (0.01 ≤ p < 0.05), and white (p ≥ 0.05). Except for GPT-4 1106 Vision Preview, that has only answered 76% of the questions (n = 718) and Gemini 1.0 Vision Pro answering all questions but one, all questions were answered by the participants and the other models. The questions that were not answered by GPT-4V and Gemini 1.0 Vision Pro were considered not correct.
References
-
- Eriksen, A. V., Möller, S. & Ryg, J. Use of GPT-4 to Diagnose Complex Clinical Cases. NEJM AI1, AIp2300031 (2023).10.1056/AIp2300031 - DOI
-
- Wu, C. et al. Can GPT-4V(ision) Serve Medical Applications? Case Studies on GPT-4V for Multimodal Medical Diagnosis. Preprint at http://arxiv.org/abs/2310.09909 (2023).
-
- Brin, D. et al. Assessing GPT-4 Multimodal Performance in Radiological Image Analysis. 2023.11.15.23298583 Preprint at 10.1101/2023.11.15.23298583 (2023).
LinkOut - more resources
Full Text Sources
