

A comparative analysis of mutual information methods for pairwise relationship detection in metagenomic data
- PMID: 39143554
- PMCID: PMC11323399
- DOI: 10.1186/s12859-024-05883-7
A comparative analysis of mutual information methods for pairwise relationship detection in metagenomic data
Abstract
Background: Construction of co-occurrence networks in metagenomic data often employs correlation to infer pairwise relationships between microbes. However, biological systems are complex and often display qualities non-linear in nature. Therefore, the reliance on correlation alone may overlook important relationships and fail to capture the full breadth of intricacies presented in underlying interaction networks. It is of interest to incorporate metrics that are not only robust in detecting linear relationships, but non-linear ones as well.
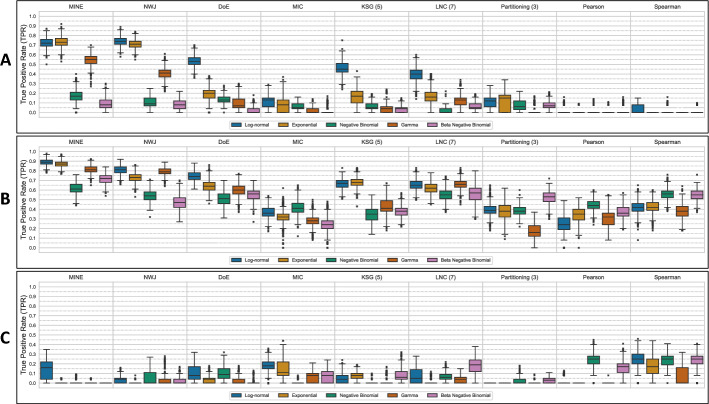
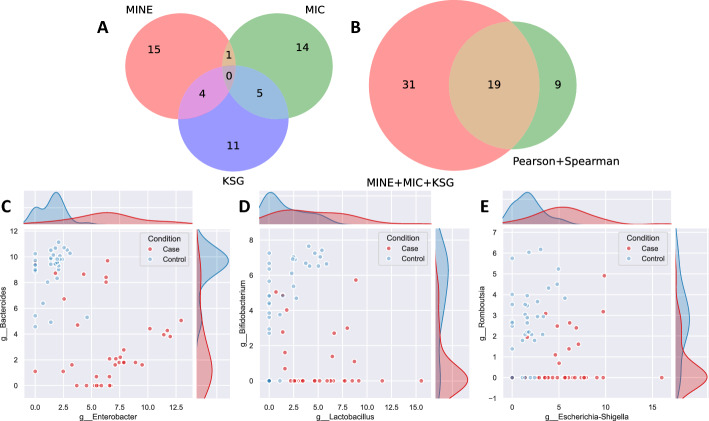
Results: In this paper, we explore the use of various mutual information (MI) estimation approaches for quantifying pairwise relationships in biological data and compare their performances against two traditional measures-Pearson's correlation coefficient, r, and Spearman's rank correlation coefficient, ρ. Metrics are tested on both simulated data designed to mimic pairwise relationships that may be found in ecological systems and real data from a previous study on C. diff infection. The results demonstrate that, in the case of asymmetric relationships, mutual information estimators can provide better detection ability than Pearson's or Spearman's correlation coefficients. Specifically, we find that these estimators have elevated performances in the detection of exploitative relationships, demonstrating the potential benefit of including them in future metagenomic studies.
Conclusions: Mutual information (MI) can uncover complex pairwise relationships in biological data that may be missed by traditional measures of association. The inclusion of such relationships when constructing co-occurrence networks can result in a more comprehensive analysis than the use of correlation alone.
Keywords: Asymmetrical relationships; Co-occurrence networks; Mutual information; Non-linear relationships.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures





References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
