

GPT-4 as an X data annotator: Unraveling its performance on a stance classification task
- PMID: 39146280
- PMCID: PMC11326574
- DOI: 10.1371/journal.pone.0307741
GPT-4 as an X data annotator: Unraveling its performance on a stance classification task
Abstract
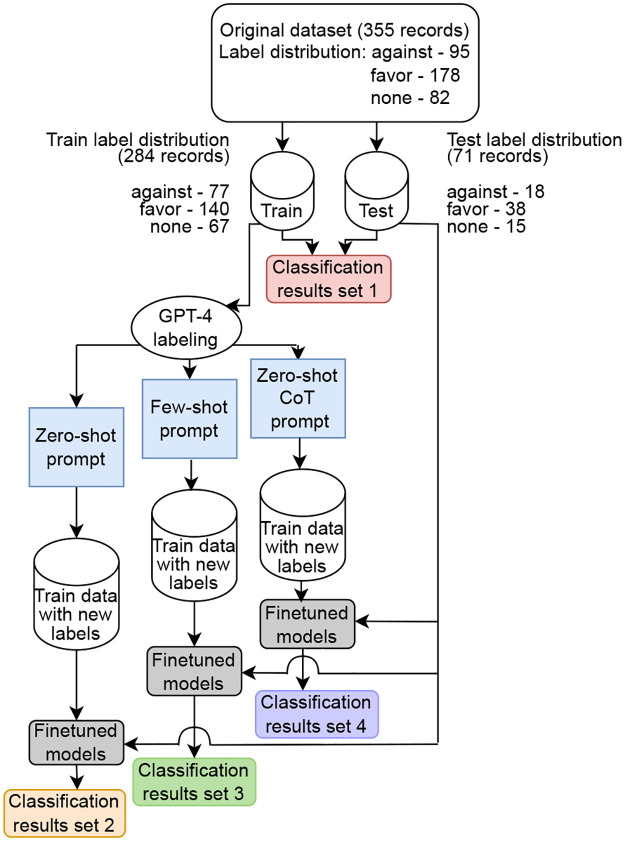
Data annotation in NLP is a costly and time-consuming task, traditionally handled by human experts who require extensive training to enhance the task-related background knowledge. Besides, labeling social media texts is particularly challenging due to their brevity, informality, creativity, and varying human perceptions regarding the sociocultural context of the world. With the emergence of GPT models and their proficiency in various NLP tasks, this study aims to establish a performance baseline for GPT-4 as a social media text annotator. To achieve this, we employ our own dataset of tweets, expertly labeled for stance detection with full inter-rater agreement among three annotators. We experiment with three techniques: Zero-shot, Few-shot, and Zero-shot with Chain-of-Thoughts to create prompts for the labeling task. We utilize four training sets constructed with different label sets, including human labels, to fine-tune transformer-based large language models and various combinations of traditional machine learning models with embeddings for stance classification. Finally, all fine-tuned models undergo evaluation using a common testing set with human-generated labels. We use the results from models trained on human labels as the benchmark to assess GPT-4's potential as an annotator across the three prompting techniques. Based on the experimental findings, GPT-4 achieves comparable results through the Few-shot and Zero-shot Chain-of-Thoughts prompting methods. However, none of these labeling techniques surpass the top three models fine-tuned on human labels. Moreover, we introduce the Zero-shot Chain-of-Thoughts as an effective strategy for aspect-based social media text labeling, which performs better than the standard Zero-shot and yields results similar to the high-performing yet expensive Few-shot approach.
Copyright: © 2024 Liyanage et al. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures








References
-
- Introduction to OpenAI models [Internet]. OpenAI; [cited 2023 Aug 10]. Available from: https://platform.openai.com/docs/introduction
-
- Cheng L, Li X, Bing L. Is GPT-4 a Good Data Analyst?. arXiv preprint arXiv:2305.15038. 2023 May 24.
-
- Chiang CH, Lee HY. Can Large Language Models Be an Alternative to Human Evaluations?. arXiv preprint arXiv:2305.01937. 2023 May 3.
-
- Wang J, Liang Y, Meng F, Shi H, Li Z, Xu J, et al. Is chatgpt a good nlg evaluator? a preliminary study. arXiv preprint arXiv:2303.04048. 2023 Mar 7.
-
- Feng Y, Vanam S, Cherukupally M, Zheng W, Qiu M, Chen H. Investigating Code Generation Performance of Chat-GPT with Crowdsourcing Social Data. InProceedings of the 47th IEEE Computer Software and Applications Conference 2023 (pp. 1–10).
MeSH terms
LinkOut - more resources
Full Text Sources
