

ChatGPT v4 outperforming v3.5 on cancer treatment recommendations in quality, clinical guideline, and expert opinion concordance
- PMID: 39148811
- PMCID: PMC11325467
- DOI: 10.1177/20552076241269538
ChatGPT v4 outperforming v3.5 on cancer treatment recommendations in quality, clinical guideline, and expert opinion concordance
Abstract
Objectives: To assess the quality and alignment of ChatGPT's cancer treatment recommendations (RECs) with National Comprehensive Cancer Network (NCCN) guidelines and expert opinions.
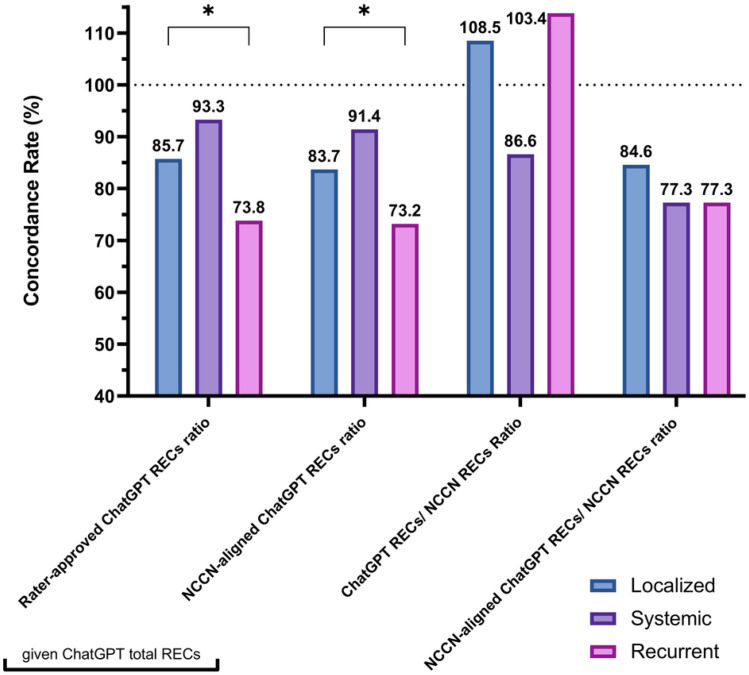
Methods: Three urologists performed quantitative and qualitative assessments in October 2023 analyzing responses from ChatGPT-4 and ChatGPT-3.5 to 108 prostate, kidney, and bladder cancer prompts using two zero-shot prompt templates. Performance evaluation involved calculating five ratios: expert-approved/expert-disagreed and NCCN-aligned RECs against total ChatGPT RECs plus coverage and adherence rates to NCCN. Experts rated the response's quality on a 1-5 scale considering correctness, comprehensiveness, specificity, and appropriateness.
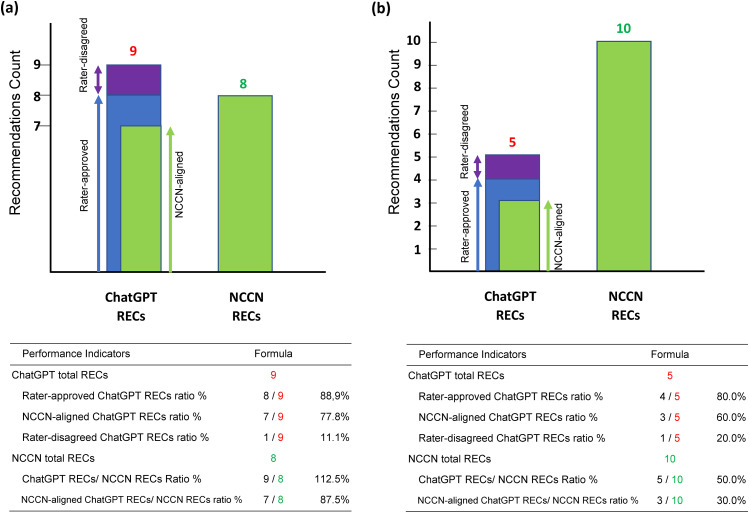
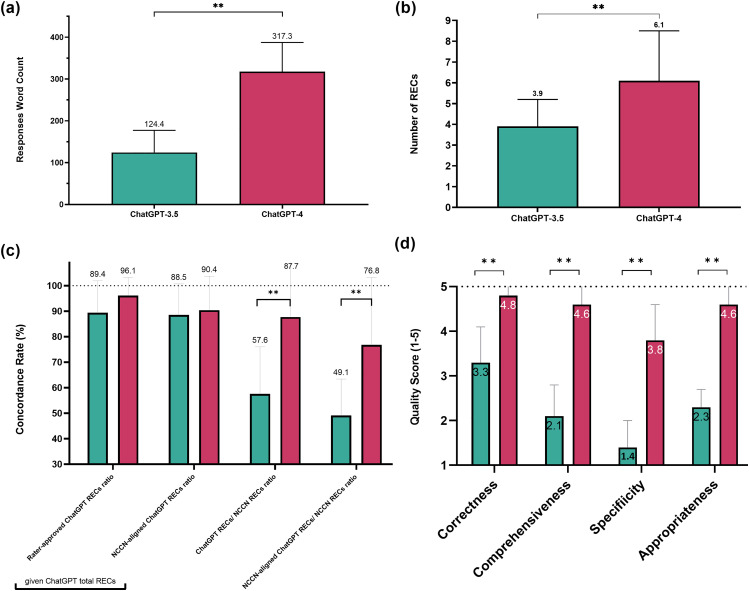
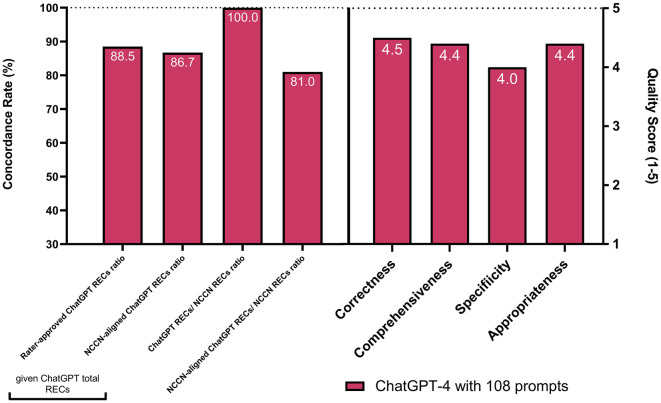
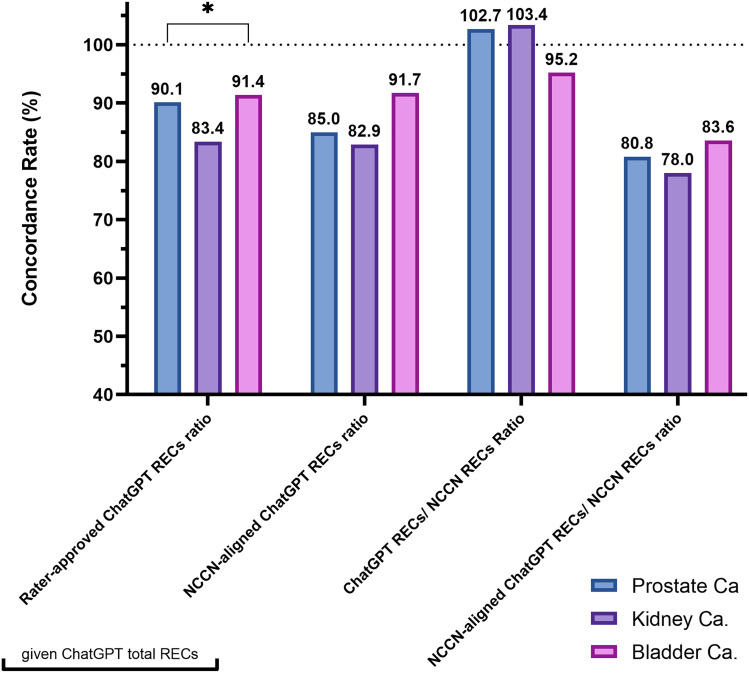
Results: ChatGPT-4 outperformed ChatGPT-3.5 in prostate cancer inquiries, with an average word count of 317.3 versus 124.4 (p < 0.001) and 6.1 versus 3.9 RECs (p < 0.001). Its rater-approved REC ratio (96.1% vs. 89.4%) and alignment with NCCN guidelines (76.8% vs. 49.1%, p = 0.001) were superior and scored significantly better on all quality dimensions. Across 108 prompts covering three cancers, ChatGPT-4 produced an average of 6.0 RECs per case, with an 88.5% approval rate from raters, 86.7% NCCN concordance, and only a 9.5% disagreement rate. It achieved high marks in correctness (4.5), comprehensiveness (4.4), specificity (4.0), and appropriateness (4.4). Subgroup analyses across cancer types, disease statuses, and different prompt templates were reported.
Conclusions: ChatGPT-4 demonstrated significant improvement in providing accurate and detailed treatment recommendations for urological cancers in line with clinical guidelines and expert opinion. However, it is vital to recognize that AI tools are not without flaws and should be utilized with caution. ChatGPT could supplement, but not replace, personalized advice from healthcare professionals.
Keywords: Artificial intelligence; ChatGPT; bladder; cancers; kidney; patient information; prostate.
© The Author(s) 2024.
Conflict of interest statement
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Figures
References
-
- Gordijn B, Have HT. ChatGPT: evolution or revolution? Med Health Care Philos 2023; 26: 1–2. - PubMed
-
- Tung JY, Lim DY, Sng GG. Potential safety concerns in use of the artificial intelligence chatbot ‘ChatGPT' for perioperative patient communication. BJU Int 2023; 132: 157–159. - PubMed
-
- Deebel NA, Terlecki R. ChatGPT performance on the American Urological Association (AUA) Self-Assessment Study Program and the potential influence of artificial intelligence (AI) in urologic training. Urology 2023; 177: 29–33. - PubMed
LinkOut - more resources
Full Text Sources
