

This is a preprint.
Foundational model aided automatic high-throughput drug screening using self-controlled cohort study
- PMID: 39148849
- PMCID: PMC11326319
- DOI: 10.1101/2024.08.04.24311480
Foundational model aided automatic high-throughput drug screening using self-controlled cohort study
Abstract
Background: Developing medicine from scratch to governmental authorization and detecting adverse drug reactions (ADR) have barely been economical, expeditious, and risk-averse investments. The availability of large-scale observational healthcare databases and the popularity of large language models offer an unparalleled opportunity to enable automatic high-throughput drug screening for both repurposing and pharmacovigilance.
Objectives: To demonstrate a general workflow for automatic high-throughput drug screening with the following advantages: (i) the association of various exposure on diseases can be estimated; (ii) both repurposing and pharmacovigilance are integrated; (iii) accurate exposure length for each prescription is parsed from clinical texts; (iv) intrinsic relationship between drugs and diseases are removed jointly by bioinformatic mapping and large language model - ChatGPT; (v) causal-wise interpretations for incidence rate contrasts are provided.
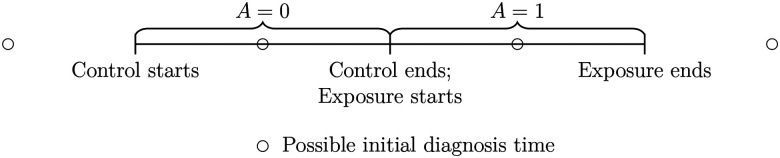
Methods: Using a self-controlled cohort study design where subjects serve as their own control group, we tested the intention-to-treat association between medications on the incidence of diseases. Exposure length for each prescription is determined by parsing common dosages in English free text into a structured format. Exposure period starts from initial prescription to treatment discontinuation. A same exposure length preceding initial treatment is the control period. Clinical outcomes and categories are identified using existing phenotyping algorithms. Incident rate ratios (IRR) are tested using uniformly most powerful (UMP) unbiased tests.
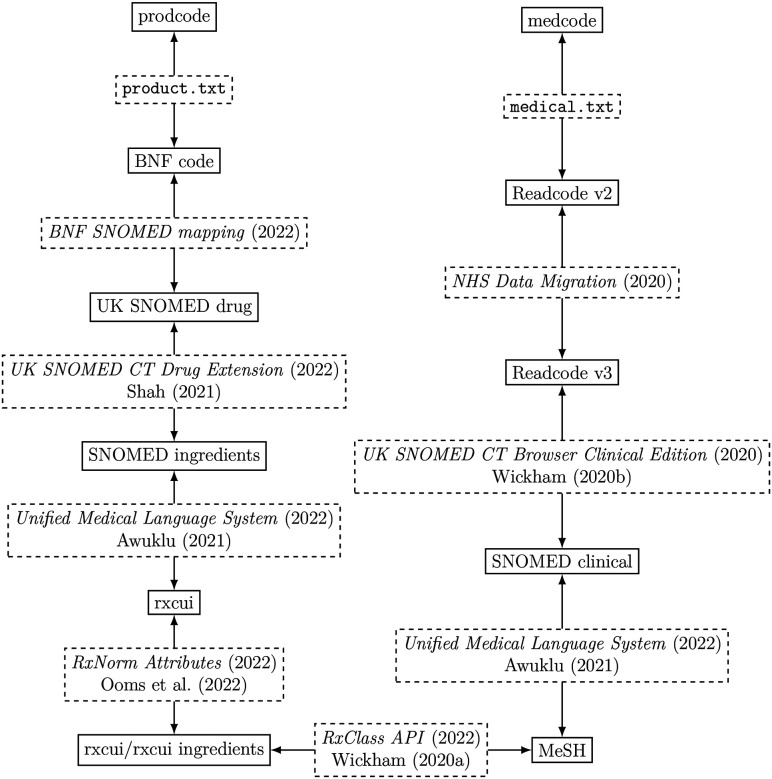
Results: We assessed 3,444 medications on 276 diseases on 6,613,198 patients from the Clinical Practice Research Datalink (CPRD), an UK primary care electronic health records (EHR) spanning from 1987 to 2018. Due to the built-in selection bias of self-controlled cohort studies, ingredients-disease pairs confounded by deterministic medical relationships are removed by existing map from RxNorm and nonexistent maps by calling ChatGPT. A total of 16,901 drug-disease pairs reveals significant risk reduction, which can be considered as candidates for repurposing, while a total of 11,089 pairs showed significant risk increase, where drug safety might be of a concern instead.
Conclusions: This work developed a data-driven, nonparametric, hypothesis generating, and automatic high-throughput workflow, which reveals the potential of natural language processing in pharmacoepidemiology. We demonstrate the paradigm to a large observational health dataset to help discover potential novel therapies and adverse drug effects. The framework of this study can be extended to other observational medical databases.
Keywords: drug repurposing; drug screening; incidence rate ratio; natural language processing; pharmacovigilance; self-controlled cohort study.
Figures
References
-
- Abadie A. (2005). Semiparametric difference-in-differences estimators. The review of economic studies, 72(1),1–19.
-
- Alfattni G., Peek N., Nenadic G., and Caskey F. (2022). Integrating text analytics and statistical modelling to analyse kidney transplant immune suppression medication in registry data. International Journal of Population Data Science, 1(1).
-
- Awuklu Y. (2021). getUMLS: Query the UMLS metathesaurus [Manual]. Retrieved from https://github.com/yvoawk/getUMLS/releases/tag/v0.1.0 (R package version 0.1.0)
-
- Bao Y., Kuang Z., Peissig P., Page D., and Willett R. (2017). Hawkes process modeling of adverse drug reactions with longitudinal observational data. In Machine learning for healthcare conference (Vol. 68, pp. 177–190).
-
- Bate A., Lindquist M., Edwards I. R., Olsson S., Orre R., Lansner A., and De Freitas R. M. (1998). A Bayesian neural network method for adverse drug reaction signal generation. European journal of clinical pharmacology, 54, 315–321. - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials