

Robust AMD Stage Grading with Exclusively OCTA Modality Leveraging 3D Volume
- PMID: 39176054
- PMCID: PMC11340655
- DOI: 10.1109/ICCVW60793.2023.00255
Robust AMD Stage Grading with Exclusively OCTA Modality Leveraging 3D Volume
Abstract
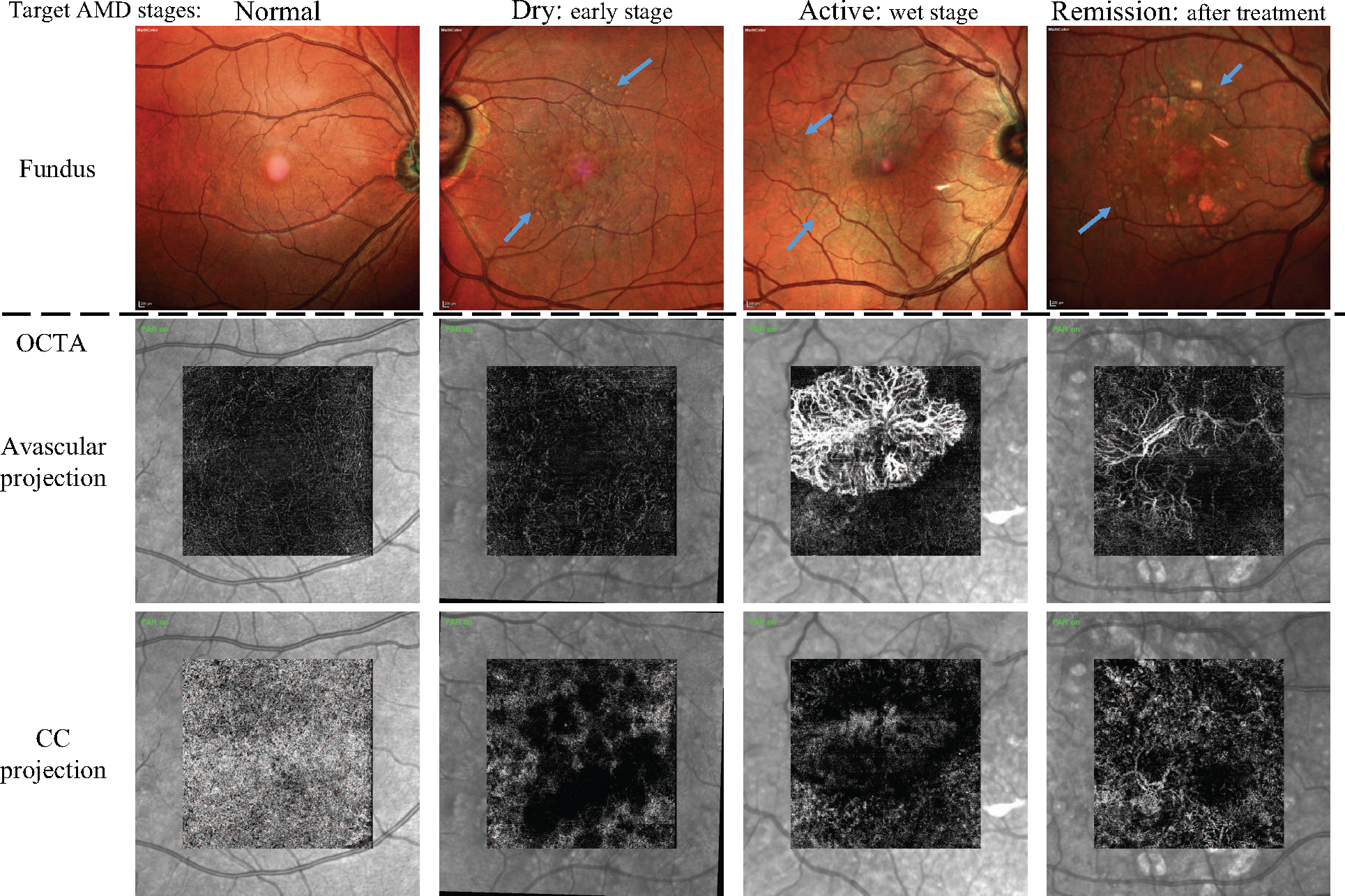
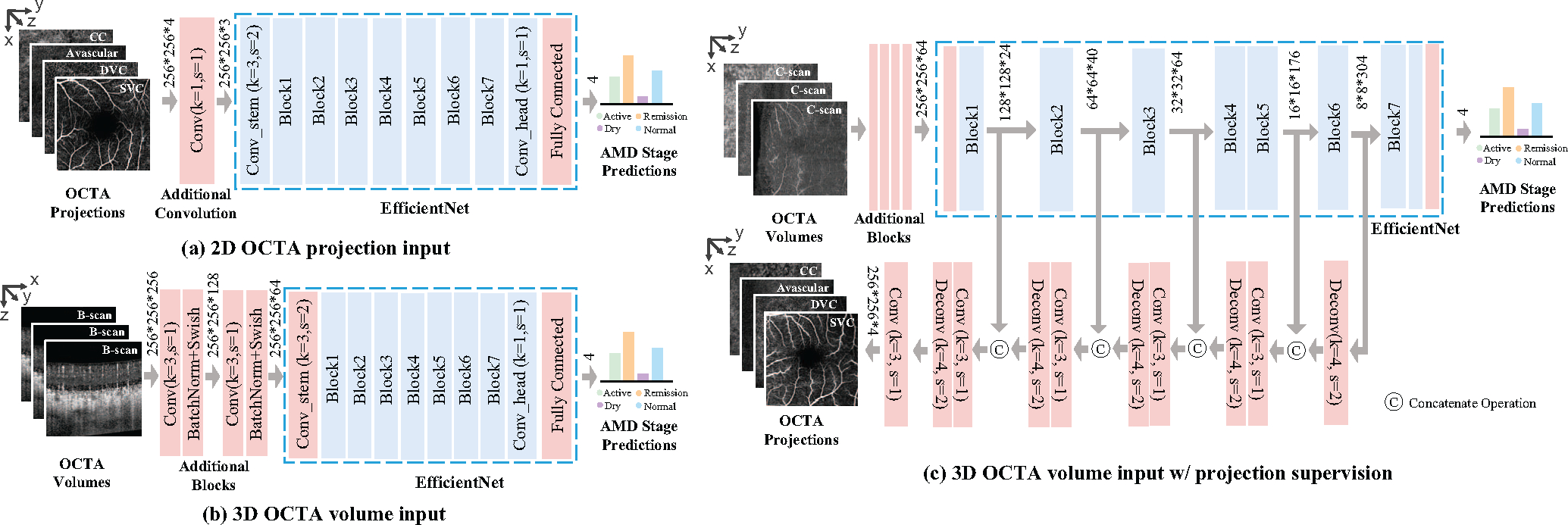
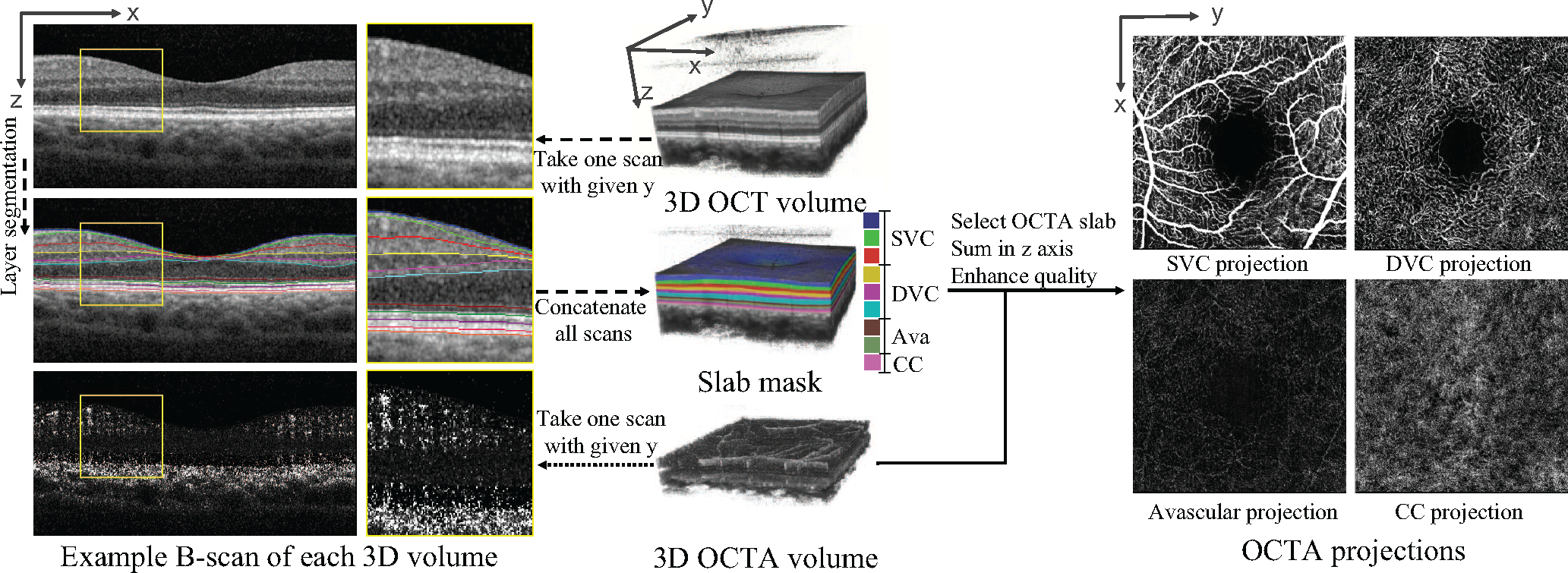
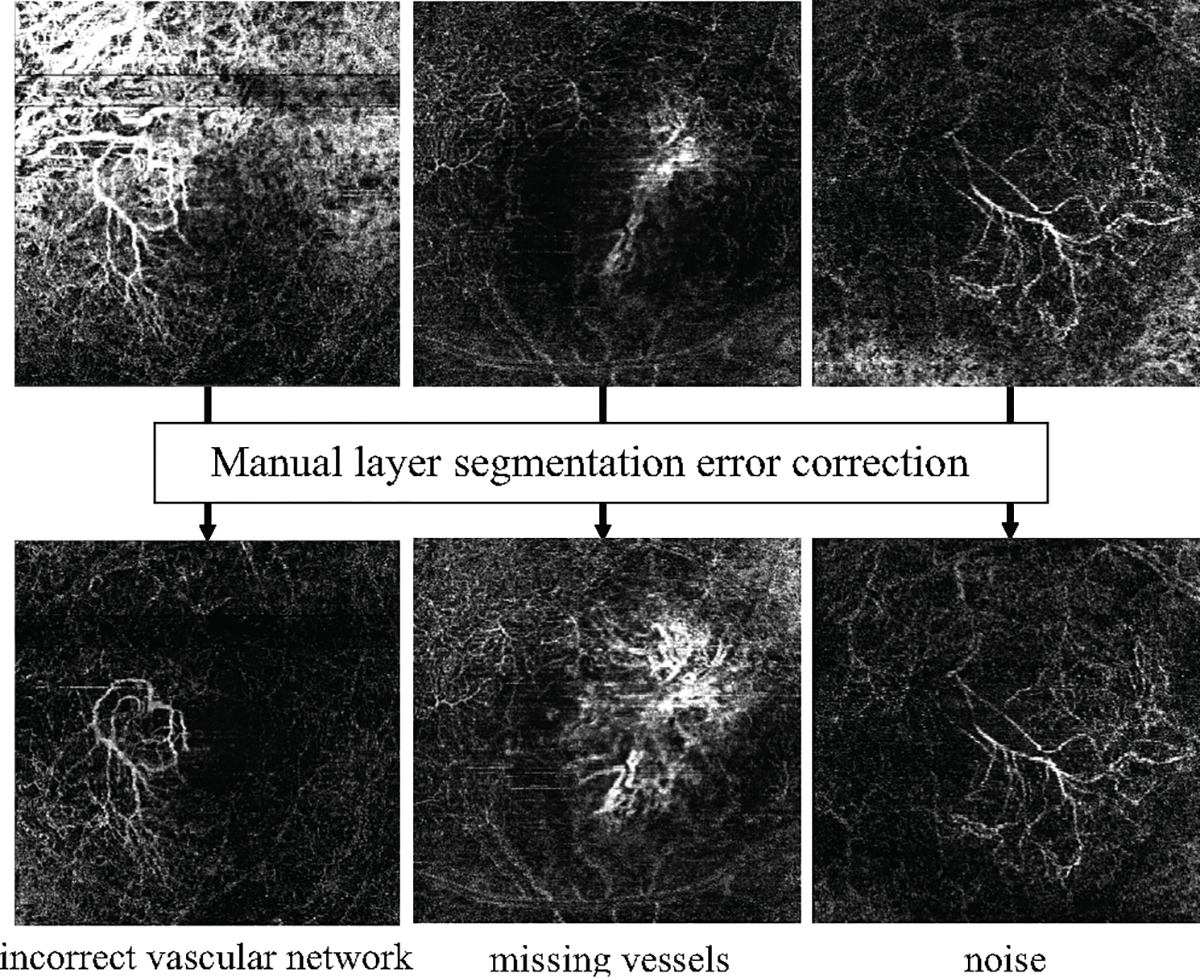
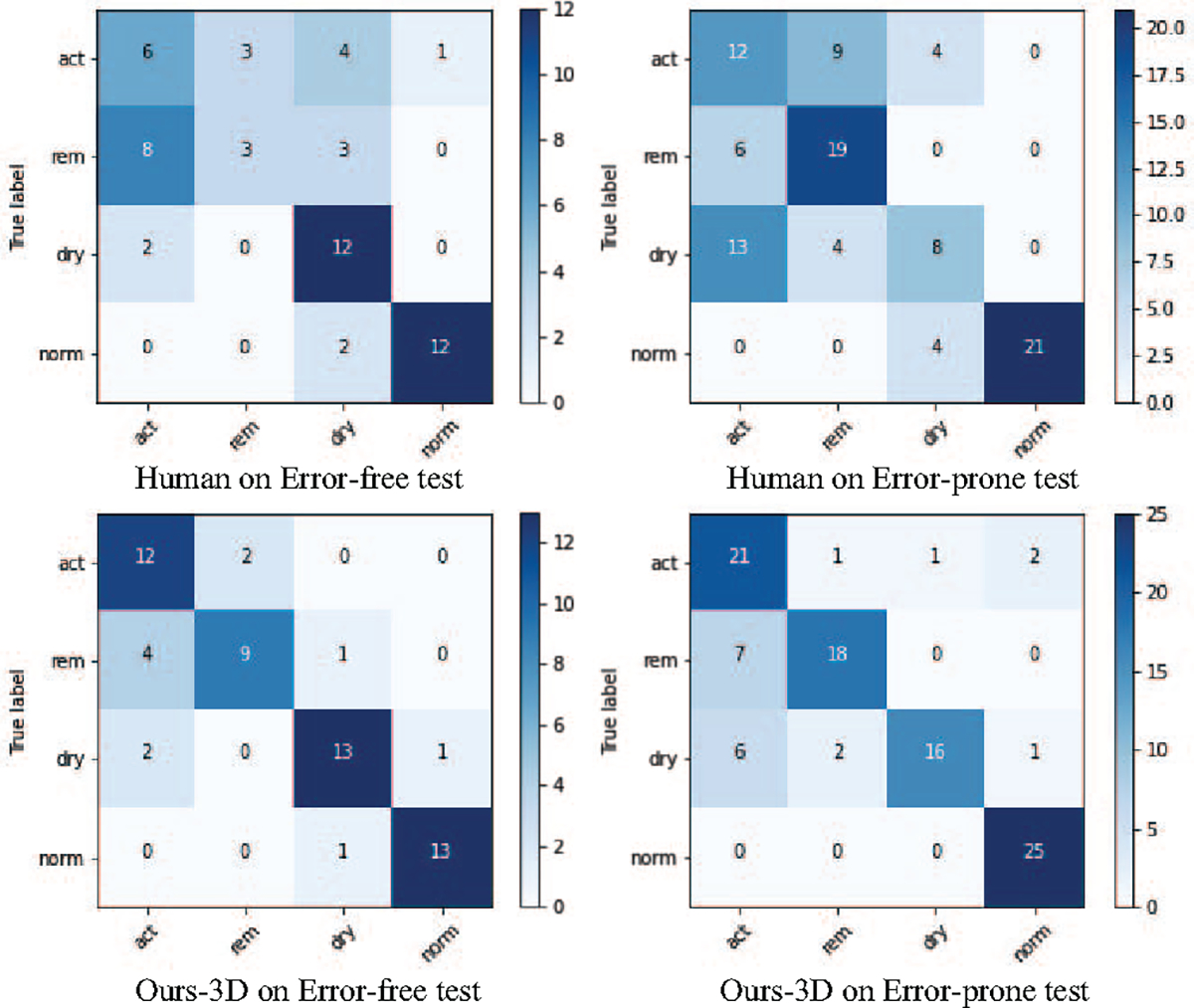
Age-related Macular Degeneration (AMD) is a degenerative eye disease that causes central vision loss. Optical Coherence Tomography Angiography (OCTA) is an emerging imaging modality that aids in the diagnosis of AMD by displaying the pathogenic vessels in the subretinal space. In this paper, we investigate the effectiveness of OCTA from the view of deep classifiers. To the best of our knowledge, this is the first study that solely uses OCTA for AMD stage grading. By developing a 2D classifier based on OCTA projections, we identify that segmentation errors in retinal layers significantly affect the accuracy of classification. To address this issue, we propose analyzing 3D OCTA volumes directly using a 2D convolutional neural network trained with additional projection supervision. Our experimental results show that we achieve over 80% accuracy on a four-stage grading task on both error-free and error-prone test sets, which is significantly higher than 60%, the accuracy of human experts. This demonstrates that OCTA provides sufficient information for AMD stage grading and the proposed 3D volume analyzer is more robust when dealing with OCTA data with segmentation errors.
Figures
Similar articles
-
OCTA-based AMD Stage Grading Enhancement via Class-Conditioned Style Transfer.Annu Int Conf IEEE Eng Med Biol Soc. 2024 Jul;2024:1-5. doi: 10.1109/EMBC53108.2024.10782262. Annu Int Conf IEEE Eng Med Biol Soc. 2024. PMID: 40038967 Free PMC article.
-
OCTA-500: A retinal dataset for optical coherence tomography angiography study.Med Image Anal. 2024 Apr;93:103092. doi: 10.1016/j.media.2024.103092. Epub 2024 Jan 28. Med Image Anal. 2024. PMID: 38325155
-
Image Projection Network: 3D to 2D Image Segmentation in OCTA Images.IEEE Trans Med Imaging. 2020 Nov;39(11):3343-3354. doi: 10.1109/TMI.2020.2992244. Epub 2020 Oct 28. IEEE Trans Med Imaging. 2020. PMID: 32365023
-
Optical Coherence Tomography Angiography of the Choriocapillaris in Age-Related Macular Degeneration.J Clin Med. 2021 Feb 13;10(4):751. doi: 10.3390/jcm10040751. J Clin Med. 2021. PMID: 33668537 Free PMC article. Review.
-
Practical guidance for imaging biomarkers in exudative age-related macular degeneration.Surv Ophthalmol. 2023 Jul-Aug;68(4):615-627. doi: 10.1016/j.survophthal.2023.02.004. Epub 2023 Feb 26. Surv Ophthalmol. 2023. PMID: 36854371 Review.
Cited by
-
OCTA-based AMD Stage Grading Enhancement via Class-Conditioned Style Transfer.Annu Int Conf IEEE Eng Med Biol Soc. 2024 Jul;2024:1-5. doi: 10.1109/EMBC53108.2024.10782262. Annu Int Conf IEEE Eng Med Biol Soc. 2024. PMID: 40038967 Free PMC article.
-
Artificial intelligence for diagnosing exudative age-related macular degeneration.Cochrane Database Syst Rev. 2024 Oct 17;10(10):CD015522. doi: 10.1002/14651858.CD015522.pub2. Cochrane Database Syst Rev. 2024. PMID: 39417312
-
ARTIFICIAL INTELLIGENCE FOR OPTICAL COHERENCE TOMOGRAPHY ANGIOGRAPHY-BASED DISEASE ACTIVITY PREDICTION IN AGE-RELATED MACULAR DEGENERATION.Retina. 2024 Mar 1;44(3):465-474. doi: 10.1097/IAE.0000000000003977. Retina. 2024. PMID: 37988102 Free PMC article.
References
-
- Alqudah Ali Mohammad. AOCT-NET: A convolutional network automated classification of multiclass retinal diseases using spectral-domain optical coherence tomography images. Medical & biological engineering & computing, 58(1):41–53, 2020. - PubMed
-
- Alsaih Khaled, Yusoff Mohd Zuki, Tang Tong Boon, Faye Ibrahima, and Mériaudeau Fabrice. Deep learning architectures analysis for age-related macular degeneration segmentation on optical coherence tomography scans. Computer methods and programs in biomedicine, 195:105566, 2020. - PubMed
-
- Barz Bjorn and Denzler Joachim. Deep learning on small datasets without pre-training using cosine loss. In WACV, pages 1371–1380, 2020.
-
- Bourne Rupert RA, Jonas Jost B, Flaxman Seth R, Keeffe Jill, Leasher Janet, Naidoo Kovin, Parodi Maurizio B, Pesudovs Konrad, Price Holly, White Richard A, et al. Prevalence and causes of vision loss in high-income countries and in eastern and central europe: 1990–2010. British Journal of Ophthalmology, 98(5):629–638, 2014. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources