

A vision-language foundation model for the generation of realistic chest X-ray images
- PMID: 39187663
- PMCID: PMC11861387
- DOI: 10.1038/s41551-024-01246-y
A vision-language foundation model for the generation of realistic chest X-ray images
Abstract
The paucity of high-quality medical imaging datasets could be mitigated by machine learning models that generate compositionally diverse images that faithfully represent medical concepts and pathologies. However, large vision-language models are trained on natural images, and the diversity distribution of the generated images substantially differs from that of medical images. Moreover, medical language involves specific and semantically rich vocabulary. Here we describe a domain-adaptation strategy for large vision-language models that overcomes distributional shifts. Specifically, by leveraging publicly available datasets of chest X-ray images and the corresponding radiology reports, we adapted a latent diffusion model pre-trained on pairs of natural images and text descriptors to generate diverse and visually plausible synthetic chest X-ray images (as confirmed by board-certified radiologists) whose appearance can be controlled with free-form medical text prompts. The domain-adaptation strategy for the text-conditioned synthesis of medical images can be used to augment training datasets and is a viable alternative to the sharing of real medical images for model training and fine-tuning.
© 2024. The Author(s), under exclusive licence to Springer Nature Limited.
Conflict of interest statement
Competing interests: T.M.A. and S.P. are employees of Stability AI. C.P.L. reports activities not related to the present article: Board of directors and shareholder, Bunkerhill Health 3/31/2019, Option holder, Whiterabbit.ai 10/01/2017, Advisor and option holder, GalileoCDS 05/01/2019, Advisor and option holder, Sirona Medical 07/06/2020, Advisor and option holder, Adra 09/17/2020, Advisor and option holder, Kheiron 10/21/2021, Paid consultant, Sixth Street 02/07/2022, Paid consultant, Gilmartin Capital 07/18/2022. Recent grant and gift support paid to C.P.L.’s institution: BunkerHill Health, Carestream, CARPL, Clairity, GE Healthcare, Google Cloud, IBM, Kheiron, Lambda, Lunit, Microsoft, Nightingale Open Science, Philips, Siemens Healthineers, Stability.ai, Subtle Medical, VinBrain, Visiana, Whiterabbit.ai, Lowenstein Foundation, Gordon and Betty Moore Foundation. A.S.C. discloses consulting services to Patient Square Capital, Elucid Bioimaging, Skope MR, Culvert Engineering, Edge Analytics, Image Analysis Group and Chondrometrics GmbH; and is shareholder in LVIS Corp., Subtle Medical and Brain Key. The other authors declare no competing interests.
Figures


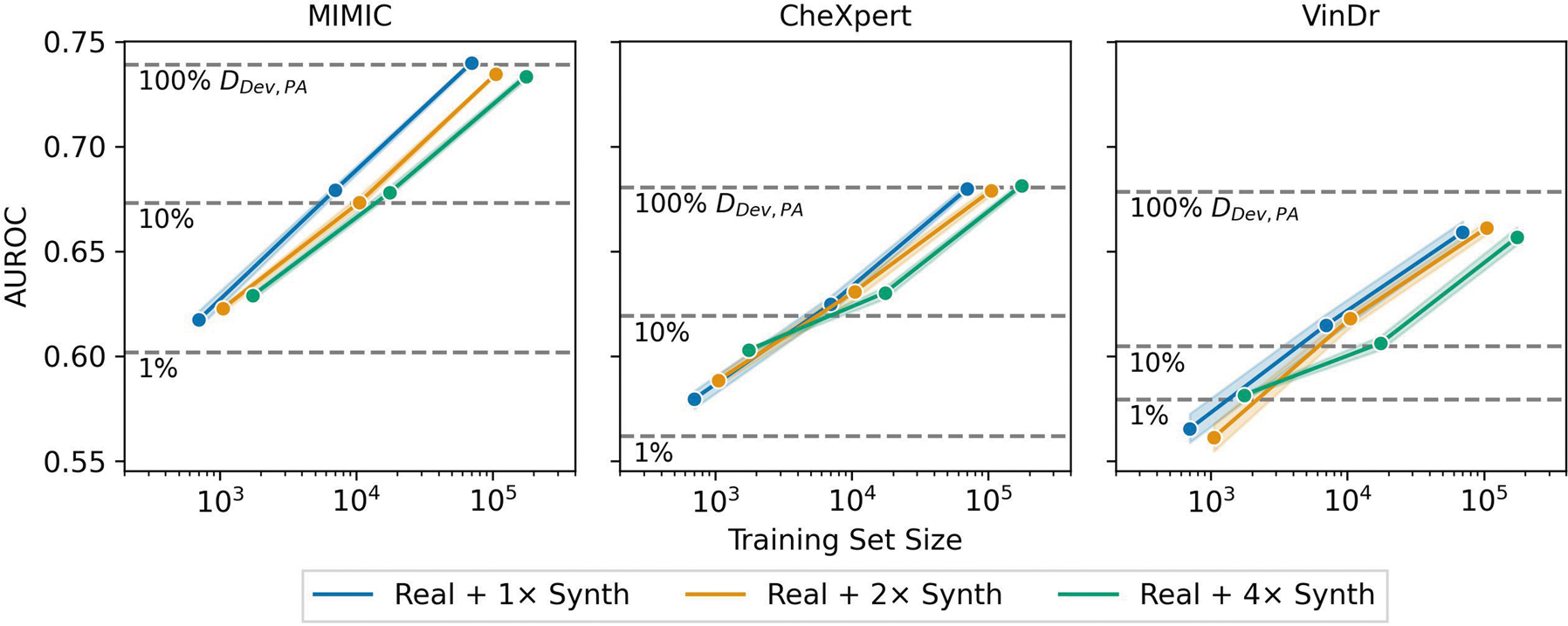





References
-
- Rombach R, Blattmann A, Lorenz D, Esser P & Ommer B High-resolution image synthesis with latent diffusion models. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 10674–10685 (IEEE, 2022).
-
- Ramesh A, Dhariwal P, Nichol A, Chu C & Chen M Hierarchical text-conditional image generation with CLIP latents. Preprint at https://arxiv.org/abs/2204.06125v1 (2022).
-
- Saharia C et al. Photorealistic text-to-image diffusion models with deep language understanding. Adv. Neural Inf. Process. Syst. 35, 36479–36494 (2022).
-
- Schuhmann C et al. LAION-5B: an open large-scale dataset for training next generation imagetext models. In Advances in Neural Information Processing Systems Vol. 35 (eds Koyejo S. et al.) 25278–25294 (Curran Associates, Inc., 2022)
-
- Bommasani R et al. On the opportunities and risks of foundation models. Preprint at https://arxiv.org/abs/2108.07258v3 (2022).
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
