

Exploring the Interplay of Dataset Size and Imbalance on CNN Performance in Healthcare: Using X-rays to Identify COVID-19 Patients
- PMID: 39202215
- PMCID: PMC11353409
- DOI: 10.3390/diagnostics14161727
Exploring the Interplay of Dataset Size and Imbalance on CNN Performance in Healthcare: Using X-rays to Identify COVID-19 Patients
Abstract
Introduction: Convolutional Neural Network (CNN) systems in healthcare are influenced by unbalanced datasets and varying sizes. This article delves into the impact of dataset size, class imbalance, and their interplay on CNN systems, focusing on the size of the training set versus imbalance-a unique perspective compared to the prevailing literature. Furthermore, it addresses scenarios with more than two classification groups, often overlooked but prevalent in practical settings.
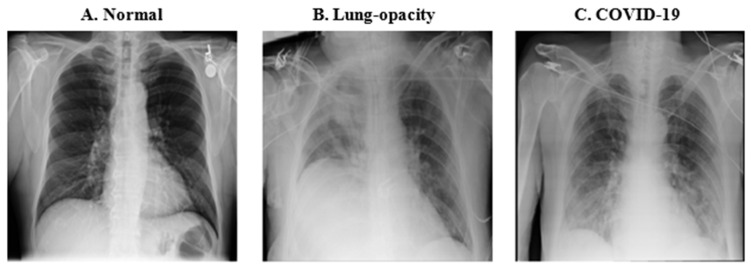
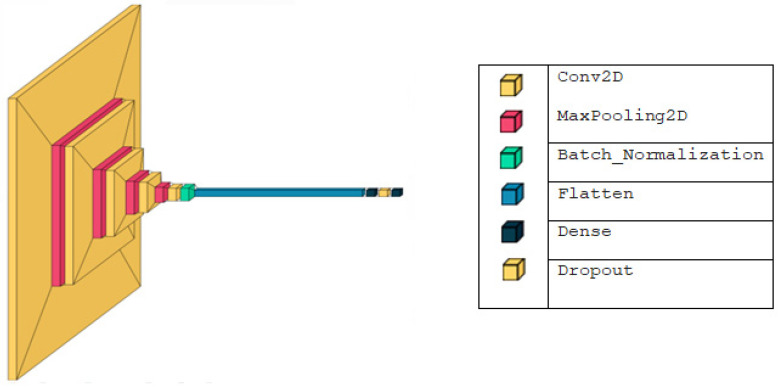
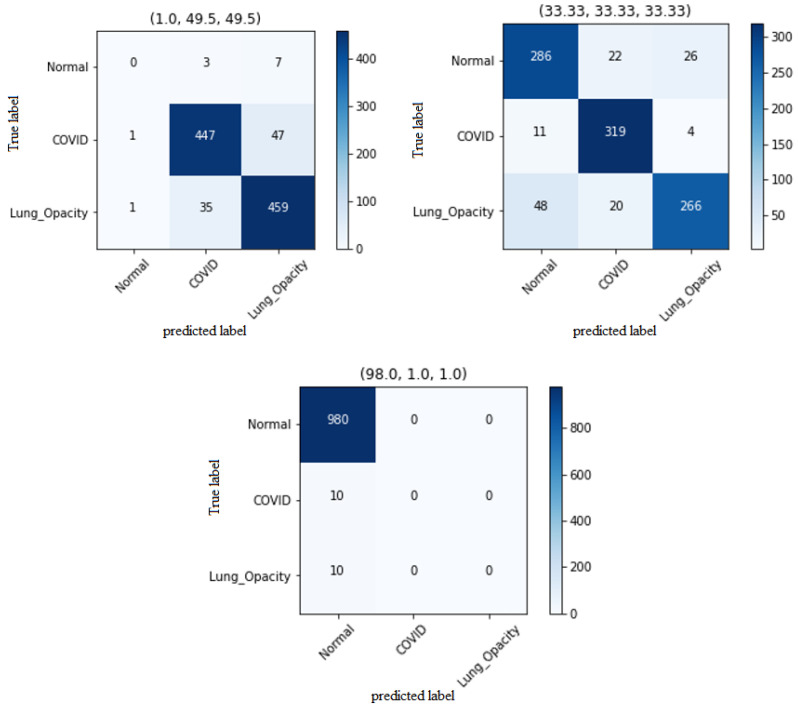
Methods: Initially, a CNN was developed to classify lung diseases using X-ray images, distinguishing between healthy individuals and COVID-19 patients. Later, the model was expanded to include pneumonia patients. To evaluate performance, numerous experiments were conducted with varied data sizes and imbalance ratios for both binary and ternary classifications, measuring various indices to validate the model's efficacy.
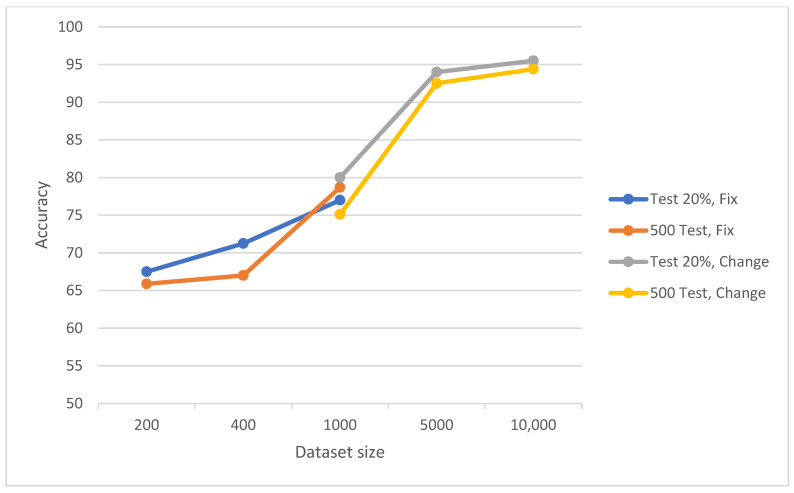
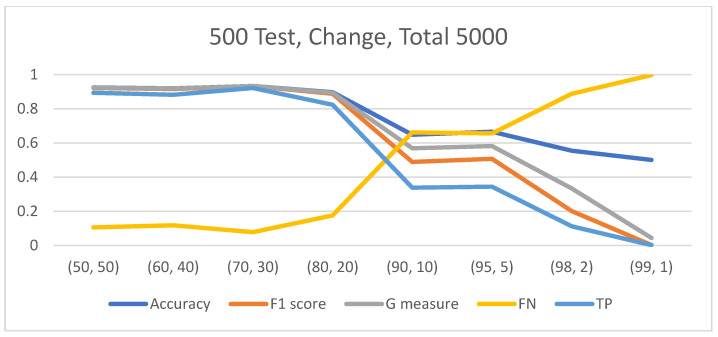
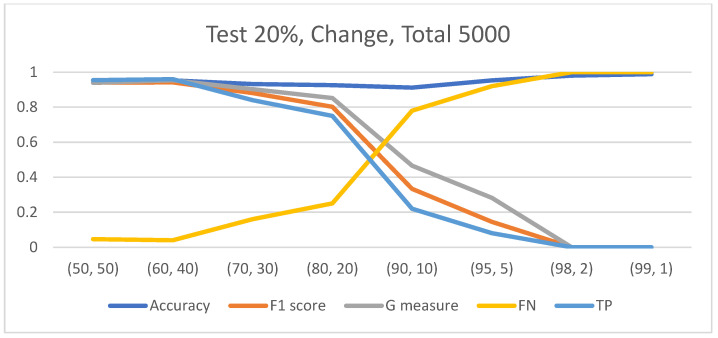
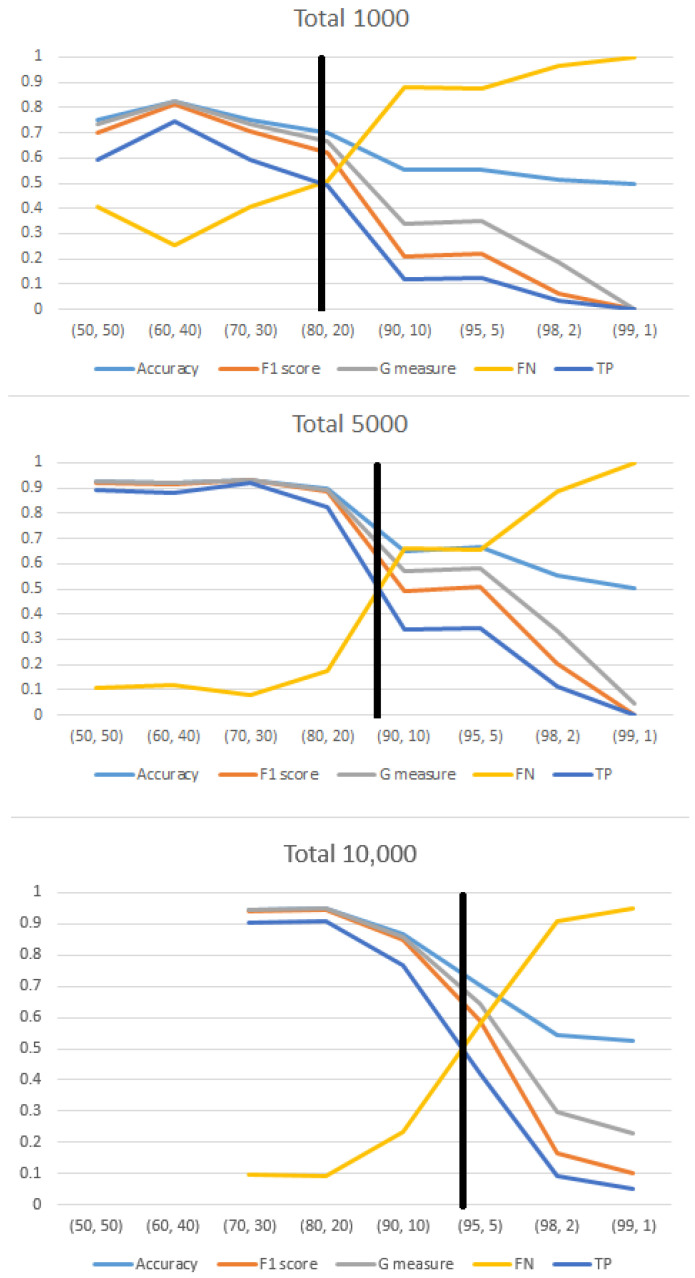
Results: The study revealed that increasing dataset size positively impacts CNN performance, but this improvement saturates beyond a certain size. A novel finding is that the data balance ratio influences performance more significantly than dataset size. The behavior of three-class classification mirrored that of binary classification, underscoring the importance of balanced datasets for accurate classification.
Conclusions: This study emphasizes the fact that achieving balanced representation in datasets is crucial for optimal CNN performance in healthcare, challenging the conventional focus on dataset size. Balanced datasets improve classification accuracy, both in two-class and three-class scenarios, highlighting the need for data-balancing techniques to improve model reliability and effectiveness.
Motivation: Our study is motivated by a scenario with 100 patient samples, offering two options: a balanced dataset with 200 samples and an unbalanced dataset with 500 samples (400 healthy individuals). We aim to provide insights into the optimal choice based on the interplay between dataset size and imbalance, enriching the discourse for stakeholders interested in achieving optimal model performance.
Limitations: Recognizing a single model's generalizability limitations, we assert that further studies on diverse datasets are needed.
Keywords: CNN; COVID-19; classification biases; imbalanced data; pulmonary disease.
Conflict of interest statement
The authors declare no conflicts of interest.
Figures
Similar articles
-
Generalizability of convolutional neural network-based model observer in breast tomosynthesis across volume glandular fractions and signal sizes.Med Phys. 2025 Jun;52(6):4023-4038. doi: 10.1002/mp.17725. Epub 2025 Feb 27. Med Phys. 2025. PMID: 40017130
-
Assessing and mitigating the effects of class imbalance in machine learning with application to X-ray imaging.Int J Comput Assist Radiol Surg. 2020 Dec;15(12):2041-2048. doi: 10.1007/s11548-020-02260-6. Epub 2020 Sep 23. Int J Comput Assist Radiol Surg. 2020. PMID: 32965624
-
From Binary to Multi-Class Classification: A Two-Step Hybrid CNN-ViT Model for Chest Disease Classification Based on X-Ray Images.Diagnostics (Basel). 2024 Dec 6;14(23):2754. doi: 10.3390/diagnostics14232754. Diagnostics (Basel). 2024. PMID: 39682662 Free PMC article.
-
CNN-Bi-LSTM: A Complex Environment-Oriented Cattle Behavior Classification Network Based on the Fusion of CNN and Bi-LSTM.Sensors (Basel). 2023 Sep 6;23(18):7714. doi: 10.3390/s23187714. Sensors (Basel). 2023. PMID: 37765771 Free PMC article.
-
Class imbalance on medical image classification: towards better evaluation practices for discrimination and calibration performance.Eur Radiol. 2024 Dec;34(12):7895-7903. doi: 10.1007/s00330-024-10834-0. Epub 2024 Jun 11. Eur Radiol. 2024. PMID: 38861161 Review.
References
-
- Rout N., Mishra D., Mallick M.K. International Proceedings on Advances in Soft Computing, Intelligent Systems and Applications. Springer; Singapore: 2018. Handling imbalanced data: A survey.
-
- López V., Fernández A., García S., Palade V., Herrera F. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Inf. Sci. 2013;250:113–141. doi: 10.1016/j.ins.2013.07.007. - DOI
-
- Li Q., Mao Y. A review of boosting methods for imbalanced data classification. Pattern Anal. Appl. 2014;17:679–693. doi: 10.1007/s10044-014-0392-8. - DOI
-
- Han C., Wang P., Huang R., Cui L. HCTNet: An experience-guided deep learning network for inter-patient arrhythmia classification on imbalanced dataset. Biomed. Signal Process. Control. 2022;78:103910. doi: 10.1016/j.bspc.2022.103910. - DOI
LinkOut - more resources
Full Text Sources
