

Bipolar disorder: Construction and analysis of a joint diagnostic model using random forest and feedforward neural networks
- PMID: 39206162
- PMCID: PMC11350441
- DOI: 10.1016/j.ibneur.2024.07.007
Bipolar disorder: Construction and analysis of a joint diagnostic model using random forest and feedforward neural networks
Abstract
Background: To construct a diagnostic model for Bipolar Disorder (BD) depressive phase using peripheral tissue RNA data from patients and combining Random Forest with Feedforward Neural Network methods.
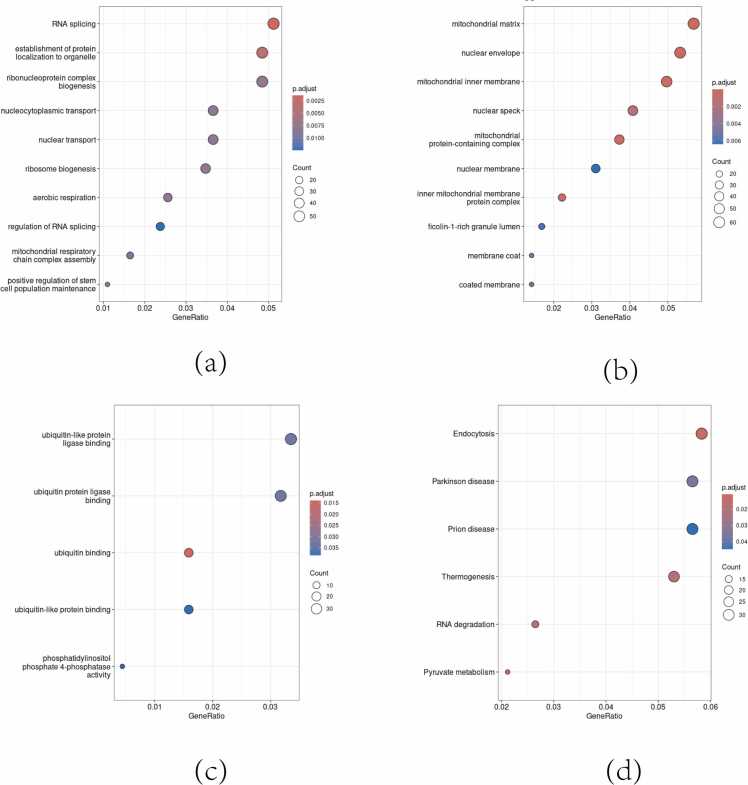
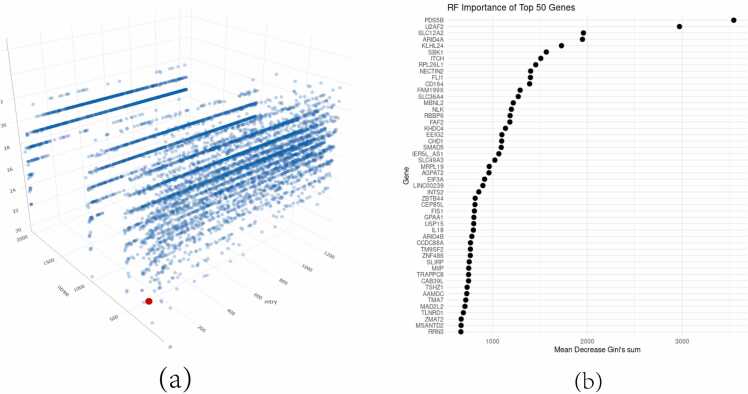
Methods: Datasets GSE23848, GSE39653, and GSE69486 were selected, and differential gene expression analysis was conducted using the limma package in R. Key genes from the differentially expressed genes were identified using the Random Forest method. These key genes' expression levels in each sample were used to train a Feedforward Neural Network model. Techniques like L1 regularization, early stopping, and dropout layers were employed to prevent model overfitting. Model performance was then validated, followed by GO, KEGG, and protein-protein interaction network analyses.
Results: The final model was a Feedforward Neural Network with two hidden layers and two dropout layers, comprising 2345 trainable parameters. Model performance on the validation set, assessed through 1000 bootstrap resampling iterations, demonstrated a specificity of 0.769 (95 % CI 0.571-1.000), sensitivity of 0.818 (95 % CI 0.533-1.000), AUC value of 0.832 (95 % CI 0.642-0.979), and accuracy of 0.792 (95 % CI 0.625-0.958). Enrichment analysis of key genes indicated no significant enrichment in any known pathways.
Conclusion: Key genes with biological significance were identified based on the decrease in Gini coefficient within the Random Forest model. The combined use of Random Forest and Feedforward Neural Network to establish a diagnostic model showed good classification performance in Bipolar Disorder.
Keywords: Bipolar disorder; Diagnostic models; Machine learning; Neural networks.
© 2024 The Authors. Published by Elsevier Inc. on behalf of International Brain Research Organization.
Conflict of interest statement
The authors declare that they have no competing interests
Figures




References
-
- Boulesteix A.L., Janitza S., Kruppa J., et al. Overview of random forest methodology and practical guidance with emphasis on computational biology and bioinformatics. WIREs Data Min. Knowl. Discov. 2012;2(6):493–507. doi: 10.1002/widm.1072. - DOI
-
- Breiman L. Random forests[J] Mach. Learn. 2001;45:5–32.
LinkOut - more resources
Full Text Sources