

Identification of a serum proteomic biomarker panel using diagnosis specific ensemble learning and symptoms for early pancreatic cancer detection
- PMID: 39208354
- PMCID: PMC11389906
- DOI: 10.1371/journal.pcbi.1012408
Identification of a serum proteomic biomarker panel using diagnosis specific ensemble learning and symptoms for early pancreatic cancer detection
Abstract
Background: The grim (<10% 5-year) survival rates for pancreatic ductal adenocarcinoma (PDAC) are attributed to its complex intrinsic biology and most often late-stage detection. The overlap of symptoms with benign gastrointestinal conditions in early stage further complicates timely detection. The suboptimal diagnostic performance of carbohydrate antigen (CA) 19-9 and elevation in benign hyperbilirubinaemia undermine its reliability, leaving a notable absence of accurate diagnostic biomarkers. Using a selected patient cohort with benign pancreatic and biliary tract conditions we aimed to develop a data analysis protocol leading to a biomarker signature capable of distinguishing patients with non-specific yet concerning clinical presentations, from those with PDAC.
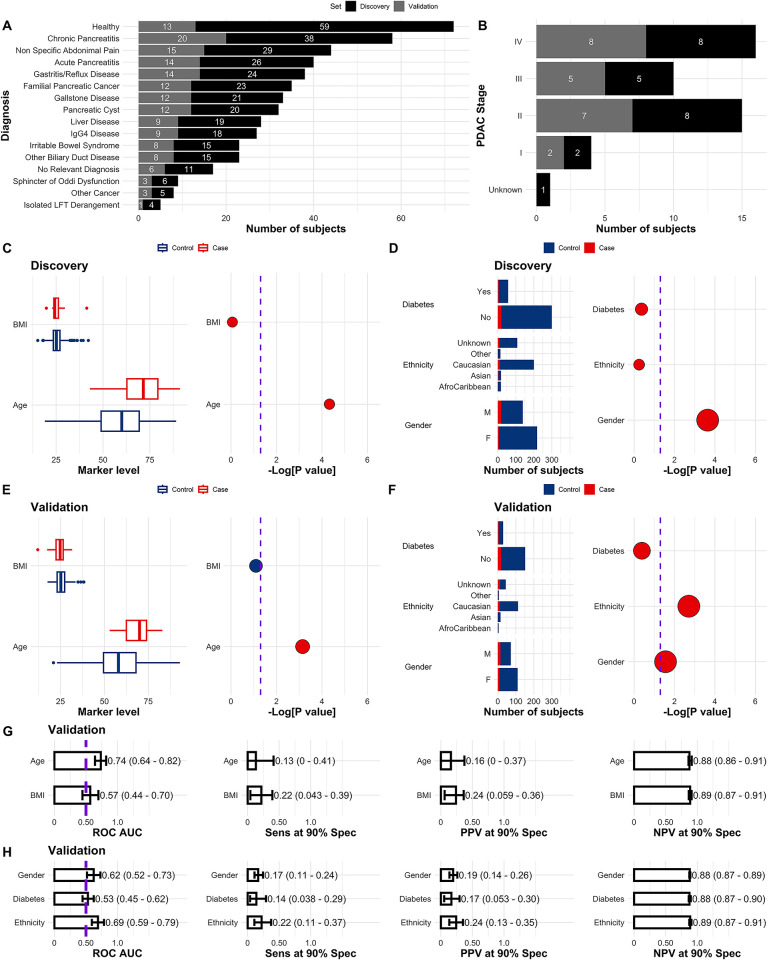
Methods: 539 patient serum samples collected under the Accelerated Diagnosis of neuro Endocrine and Pancreatic TumourS (ADEPTS) study (benign disease controls and PDACs) and the UK Collaborative Trial of Ovarian Cancer Screening (UKCTOCS, healthy controls) were screened using the Olink Oncology II panel, supplemented with five in-house markers. 16 specialized base-learner classifiers were stacked to select and enhance biomarker performances and robustness in blinded samples. Each base-learner was constructed through cross-validation and recursive feature elimination in a discovery set comprising approximately two thirds of the ADEPTS and UKCTOCS samples and contrasted specific diagnosis with PDAC.
Results: The signature which was developed using diagnosis-specific ensemble learning demonstrated predictive capabilities outperforming CA19-9, the only biomarker currently accepted by the FDA and the National Comprehensive Cancer Network guidelines for pancreatic cancer, and other individual biomarkers and combinations in both discovery and held-out validation sets. An AUC of 0.98 (95% CI 0.98-0.99) and sensitivity of 0.99 (95% CI 0.98-1) at 90% specificity was achieved with the ensemble method, which was significantly larger than the AUC of 0.79 (95% CI 0.66-0.91) and sensitivity 0.67 (95% CI 0.50-0.83), also at 90% specificity, for CA19-9, in the discovery set (p = 0.0016 and p = 0.00050, respectively). During ensemble signature validation in the held-out set, an AUC of 0.95 (95% CI 0.91-0.99), sensitivity 0.86 (95% CI 0.68-1), was attained compared to an AUC of 0.80 (95% CI 0.66-0.93), sensitivity 0.65 (95% CI 0.48-0.56) at 90% specificity for CA19-9 alone (p = 0.0082 and p = 0.024, respectively). When validated only on the benign disease controls and PDACs collected from ADEPTS, the diagnostic-specific signature achieved an AUC of 0.96 (95% CI 0.92-0.99), sensitivity 0.82 (95% CI 0.64-0.95) at 90% specificity, which was still significantly higher than the performance for CA19-9 taken as a single predictor, AUC of 0.79 (95% CI 0.64-0.93) and sensitivity of 0.18 (95% CI 0.03-0.69) (p = 0.013 and p = 0.0055, respectively).
Conclusion: Our ensemble modelling technique outperformed CA19-9, individual biomarkers and indices developed with prevailing algorithms in distinguishing patients with non-specific but concerning symptoms from those with PDAC, with implications for improving its early detection in individuals at risk.
Copyright: © 2024 Ney et al. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
I have read the journal’s policy and the authors of this manuscript have the following competing interests: UM reports stock ownership in Abcodia UK between 2011 and 2021; UM has received grants from the Medical Research Council (MRC), Cancer Research UK, the National Institute for Health Research (NIHR), the India Alliance, NIHR Biomedical Research Centre at University College London Hospital, and The Eve Appeal; UM currently has research collaborations with iLOF, RNA Guardian and Micronoma, with funding paid to UCL; UM holds patent number EP10178345.4 for Breast Cancer Diagnostics; AG currently has research collaborations with Micronoma and iLoF, with the research funding awarded to UCL. The other authors have declared that no competing interests exist.
Figures





References
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
