

This is a preprint.
An instantaneous voice synthesis neuroprosthesis
- PMID: 39229047
- PMCID: PMC11370360
- DOI: 10.1101/2024.08.14.607690
An instantaneous voice synthesis neuroprosthesis
Update in
-
An instantaneous voice-synthesis neuroprosthesis.Nature. 2025 Aug;644(8075):145-152. doi: 10.1038/s41586-025-09127-3. Epub 2025 Jun 12. Nature. 2025. PMID: 40506548
Abstract
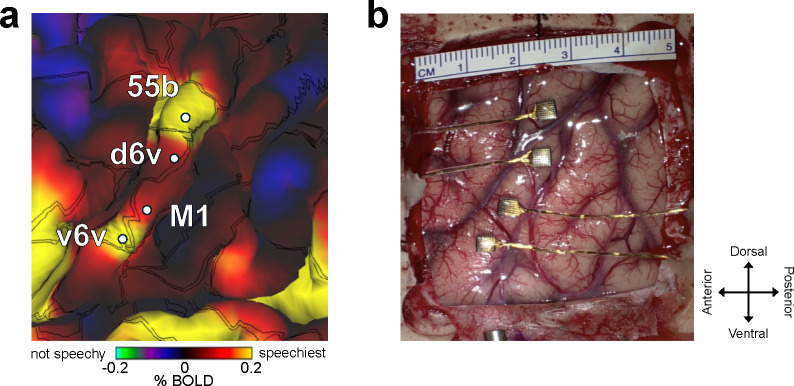
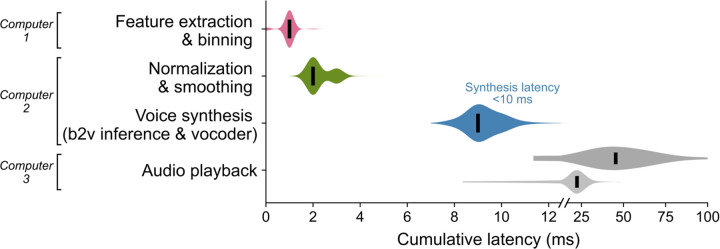
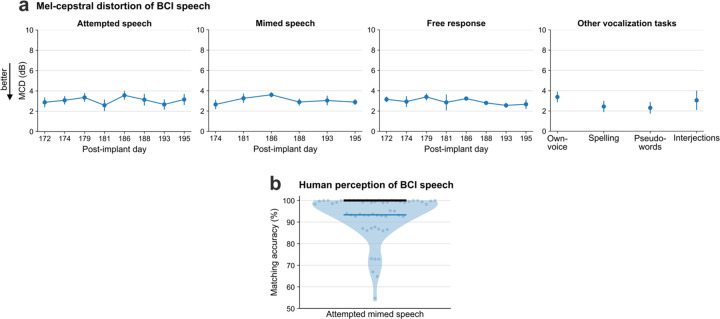
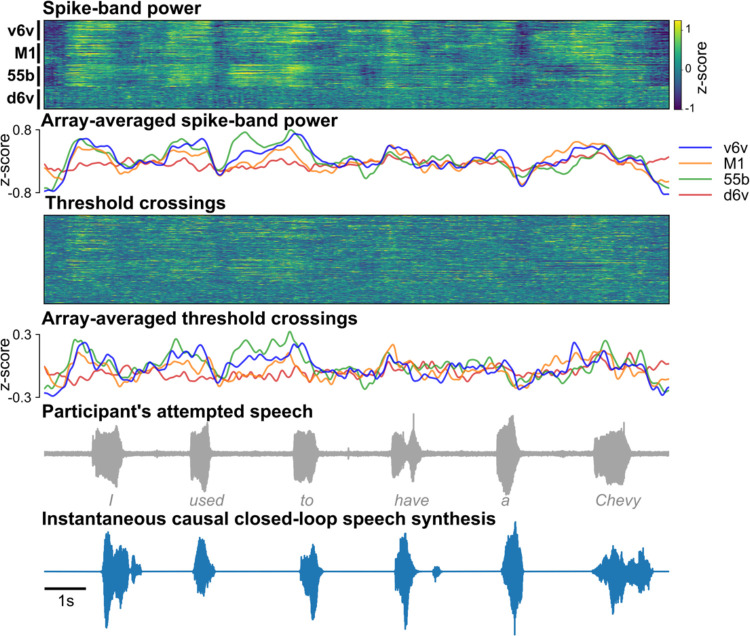
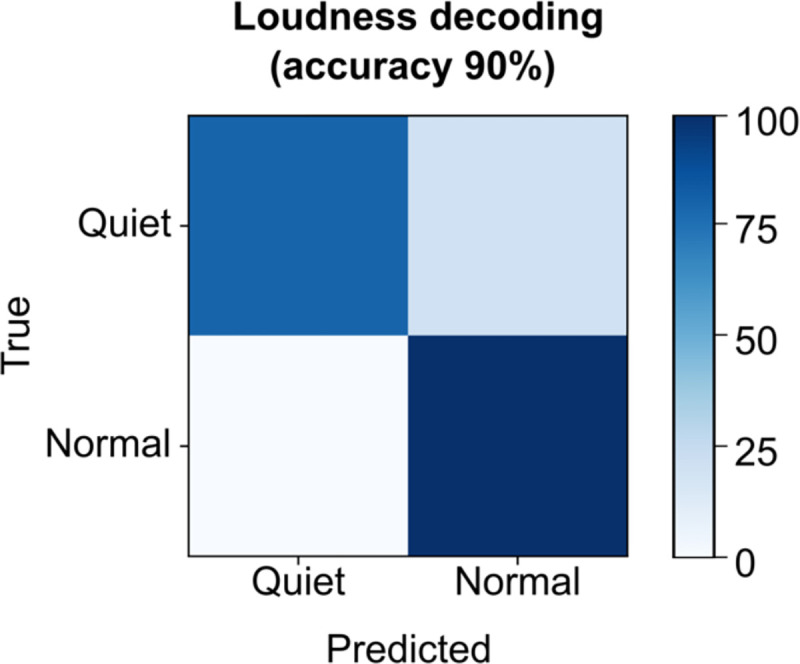
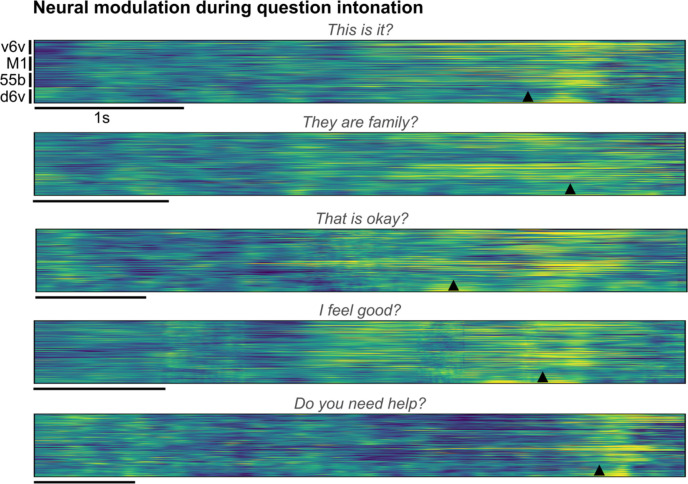
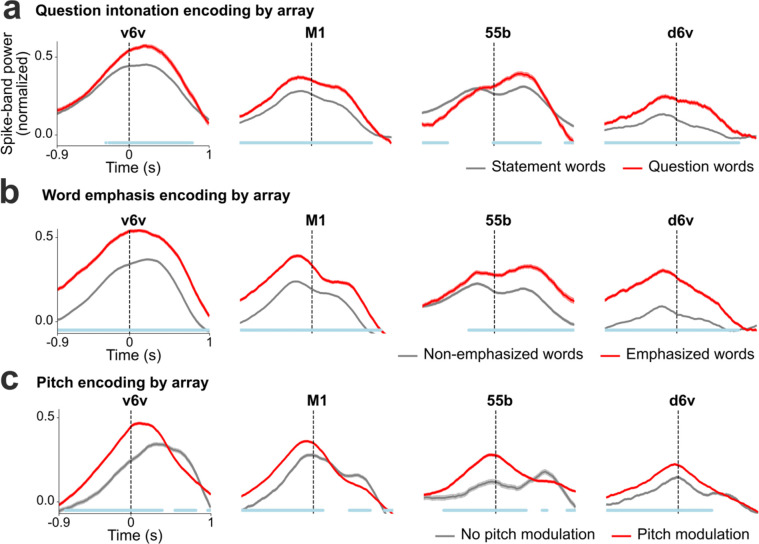
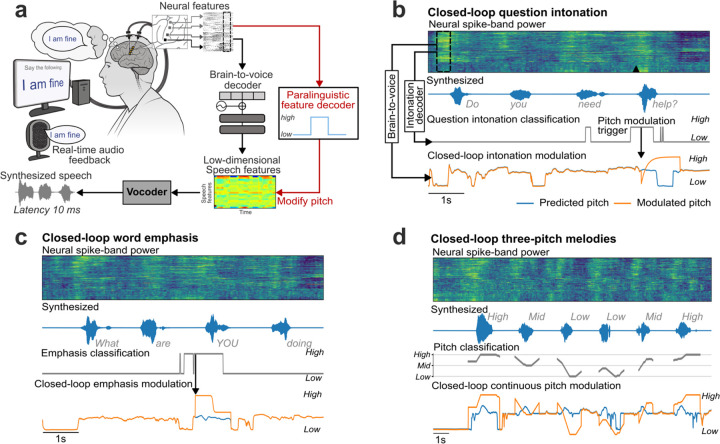
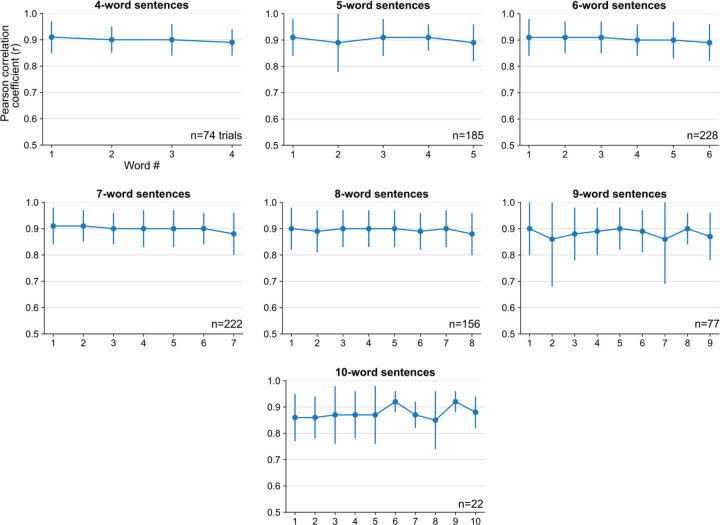
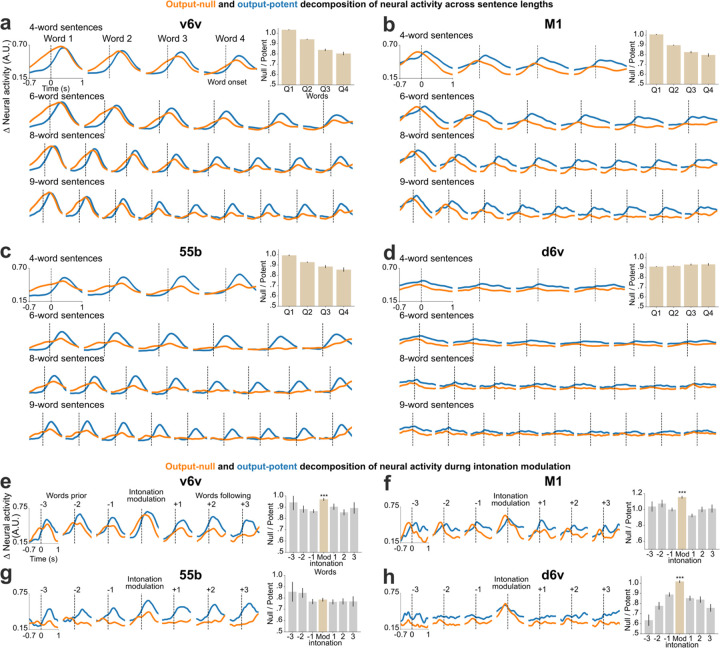
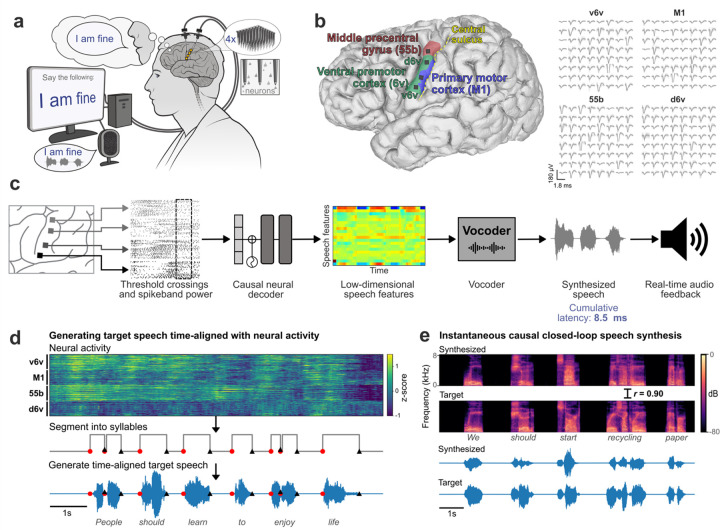
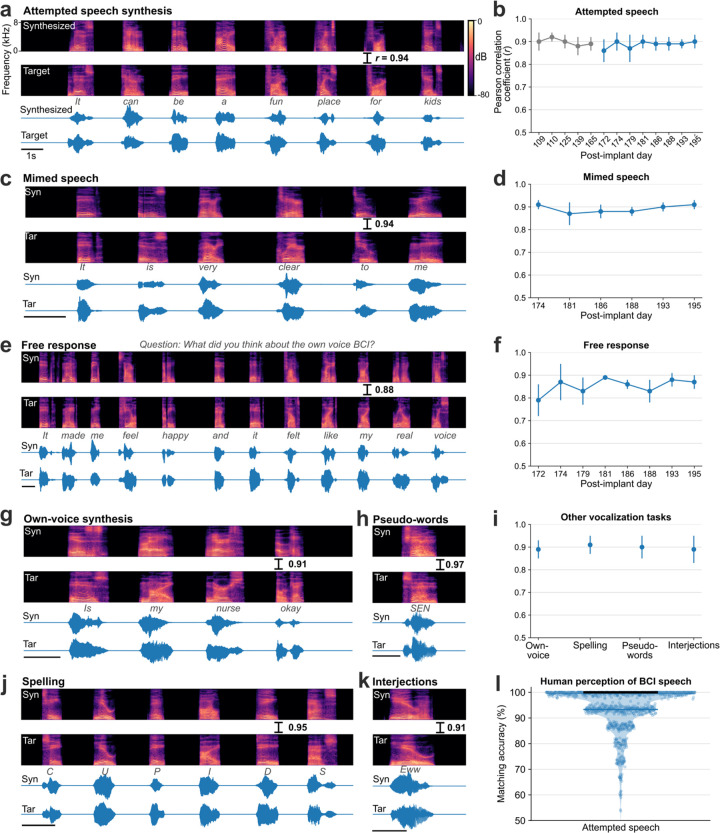
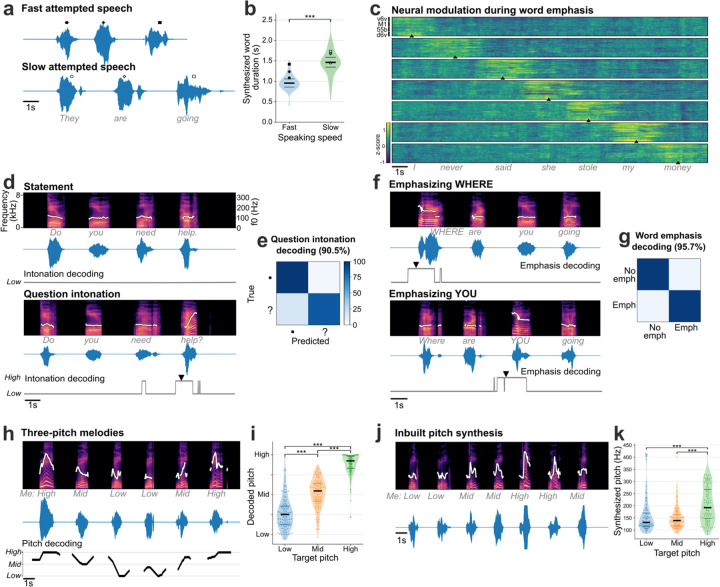
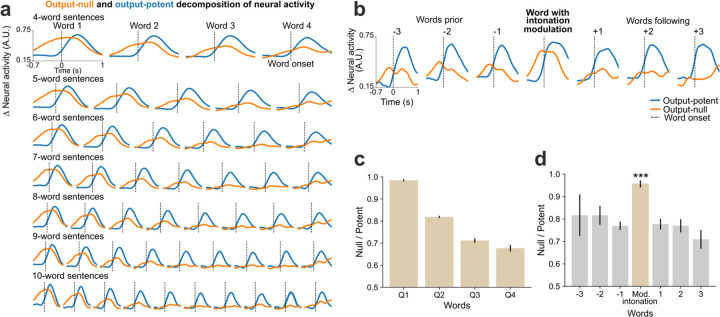
Brain computer interfaces (BCIs) have the potential to restore communication to people who have lost the ability to speak due to neurological disease or injury. BCIs have been used to translate the neural correlates of attempted speech into text1-3. However, text communication fails to capture the nuances of human speech such as prosody, intonation and immediately hearing one's own voice. Here, we demonstrate a "brain-to-voice" neuroprosthesis that instantaneously synthesizes voice with closed-loop audio feedback by decoding neural activity from 256 microelectrodes implanted into the ventral precentral gyrus of a man with amyotrophic lateral sclerosis and severe dysarthria. We overcame the challenge of lacking ground-truth speech for training the neural decoder and were able to accurately synthesize his voice. Along with phonemic content, we were also able to decode paralinguistic features from intracortical activity, enabling the participant to modulate his BCI-synthesized voice in real-time to change intonation, emphasize words, and sing short melodies. These results demonstrate the feasibility of enabling people with paralysis to speak intelligibly and expressively through a BCI.
Conflict of interest statement
Competing Interests: Stavisky is an inventor on intellectual property owned by Stanford University that has been licensed to Blackrock Neurotech and Neuralink Corp. Wairagkar, Stavisky, and Brandman have patent applications related to speech BCI owned by the Regents of the University of California. Brandman is a surgical consultant to Paradromics Inc. Stavisky is a scientific advisor to Sonera and ALVI Labs. The MGH Translational Research Center has a clinical research support agreement with Neuralink, Synchron, Axoft, Precision Neuro, and Reach Neuro, for which Hochberg provides consultative input. Mass General Brigham (MGB) is convening the Implantable Brain-Computer Interface Collaborative Community (iBCI-CC); charitable gift agreements to MGB, including those received to date from Paradromics, Synchron, Precision Neuro, Neuralink, and Blackrock Neurotech, support the iBCI-CC, for which Hochberg provides effort.
Figures
References
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources