

A pathology foundation model for cancer diagnosis and prognosis prediction
- PMID: 39232164
- PMCID: PMC12186853
- DOI: 10.1038/s41586-024-07894-z
A pathology foundation model for cancer diagnosis and prognosis prediction
Abstract
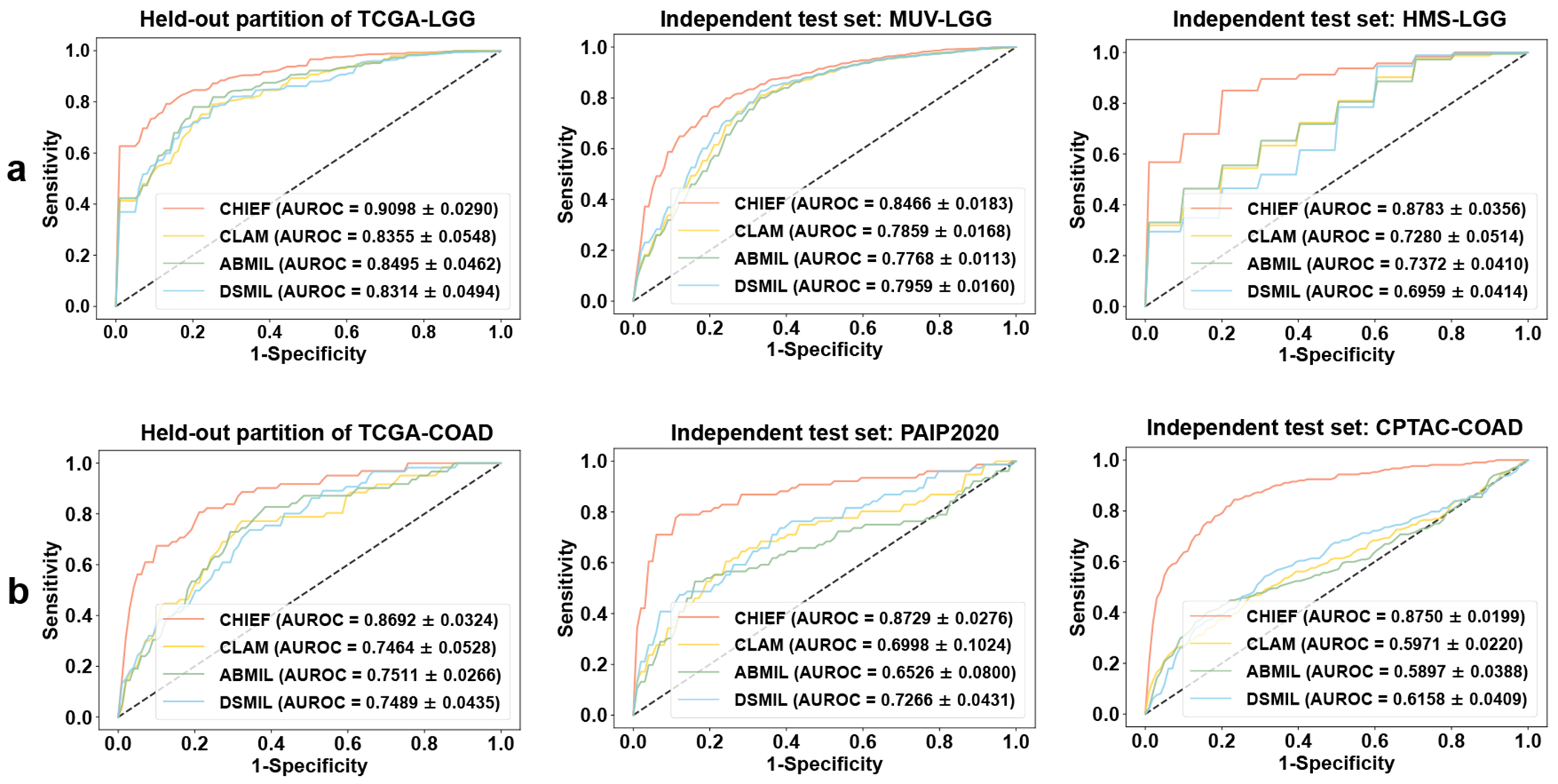
Histopathology image evaluation is indispensable for cancer diagnoses and subtype classification. Standard artificial intelligence methods for histopathology image analyses have focused on optimizing specialized models for each diagnostic task1,2. Although such methods have achieved some success, they often have limited generalizability to images generated by different digitization protocols or samples collected from different populations3. Here, to address this challenge, we devised the Clinical Histopathology Imaging Evaluation Foundation (CHIEF) model, a general-purpose weakly supervised machine learning framework to extract pathology imaging features for systematic cancer evaluation. CHIEF leverages two complementary pretraining methods to extract diverse pathology representations: unsupervised pretraining for tile-level feature identification and weakly supervised pretraining for whole-slide pattern recognition. We developed CHIEF using 60,530 whole-slide images spanning 19 anatomical sites. Through pretraining on 44 terabytes of high-resolution pathology imaging datasets, CHIEF extracted microscopic representations useful for cancer cell detection, tumour origin identification, molecular profile characterization and prognostic prediction. We successfully validated CHIEF using 19,491 whole-slide images from 32 independent slide sets collected from 24 hospitals and cohorts internationally. Overall, CHIEF outperformed the state-of-the-art deep learning methods by up to 36.1%, showing its ability to address domain shifts observed in samples from diverse populations and processed by different slide preparation methods. CHIEF provides a generalizable foundation for efficient digital pathology evaluation for patients with cancer.
© 2024. The Author(s), under exclusive licence to Springer Nature Limited.
Conflict of interest statement
Jun Zhang and X.H. were employees of Tencent AI Lab. K.-H.Y. is an inventor of U.S. patent 16/179,101 (patent assigned to Harvard University) and was a consultant of Curatio.DL (not related to this work). K.L.L. was a consultant of Travera, BMS, Servier, Integragen, LEK, and Blaze Bioscience, received equity from Travera, and has research funding from BMS and Lilly (not related to this work). The remaining authors declare no competing interests.
Figures













References
-
- Van der Laak J, Litjens G & Ciompi F Deep learning in histopathology: the path to the clinic. Nat. Med 27, 775–784 (2021). - PubMed
-
- Shmatko A, Ghaffari Laleh N, Gerstung M & Kather JN Artificial intelligence in histopathology: enhancing cancer research and clinical oncology. Nat. Cancer 3, 1026–1038 (2022). - PubMed
-
- Song AH et al. Artificial intelligence for digital and computational pathology. Nat. Rev. Bioeng 1, 930–949 (2023).
Method References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
