

Dissociative and prioritized modeling of behaviorally relevant neural dynamics using recurrent neural networks
- PMID: 39242944
- PMCID: PMC11452342
- DOI: 10.1038/s41593-024-01731-2
Dissociative and prioritized modeling of behaviorally relevant neural dynamics using recurrent neural networks
Abstract
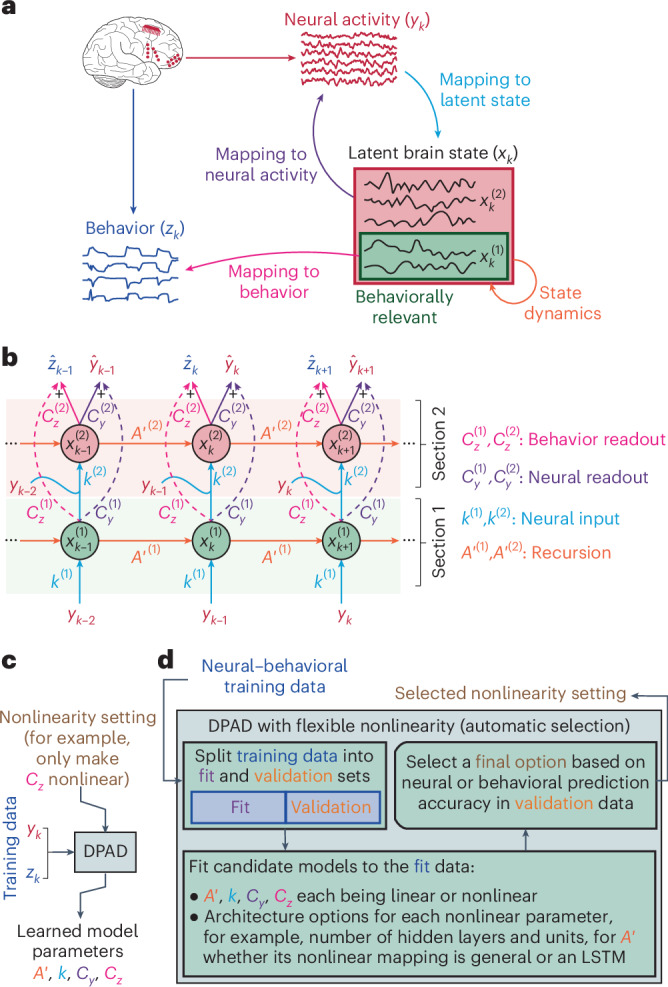
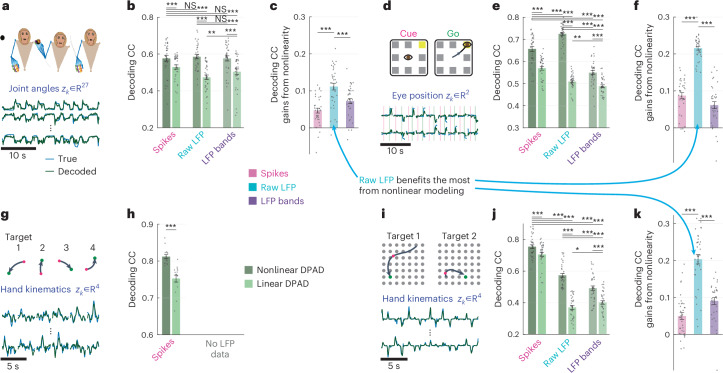
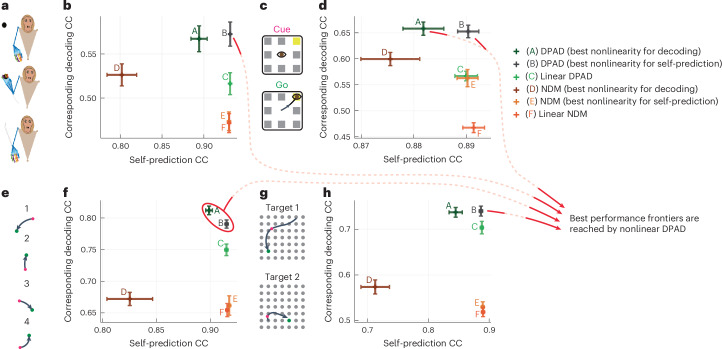
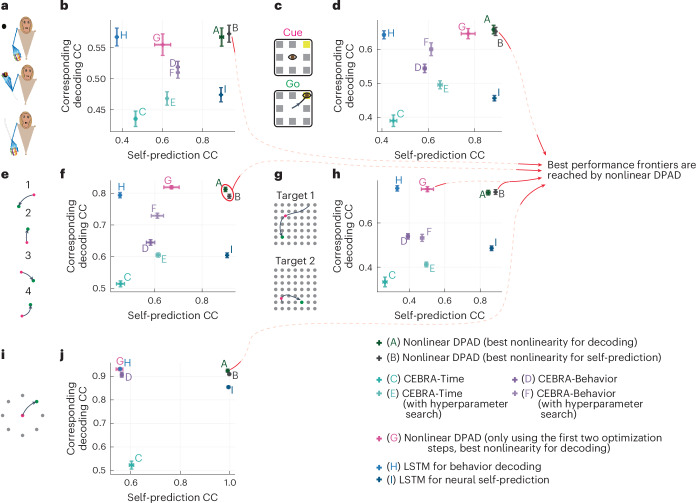
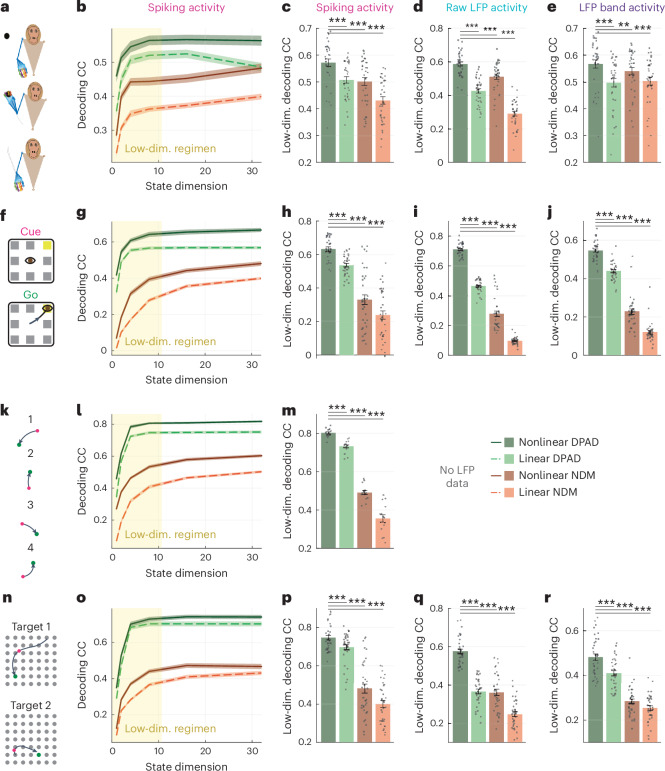
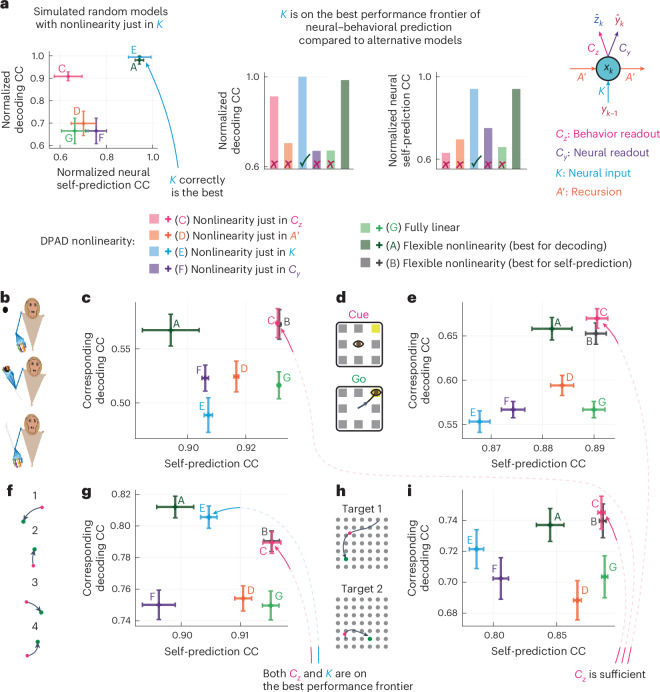
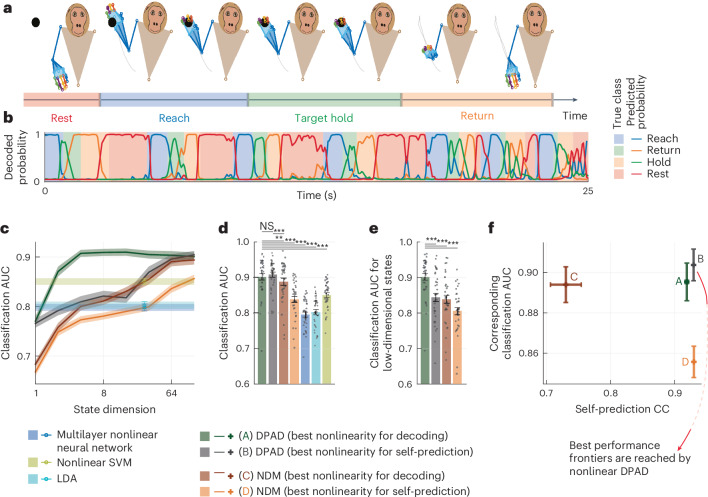
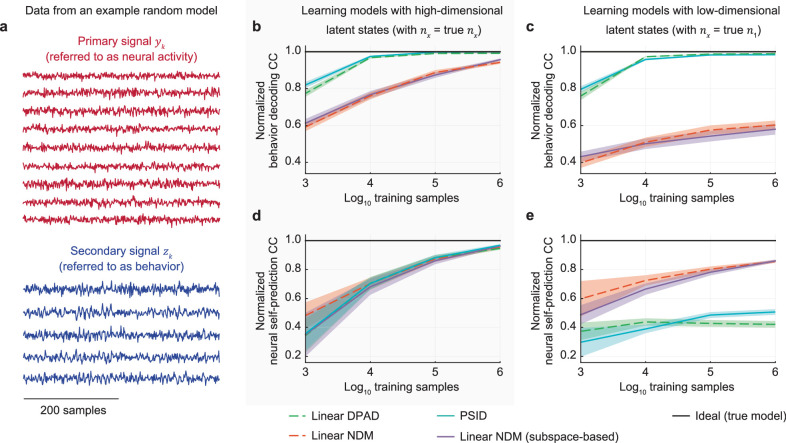
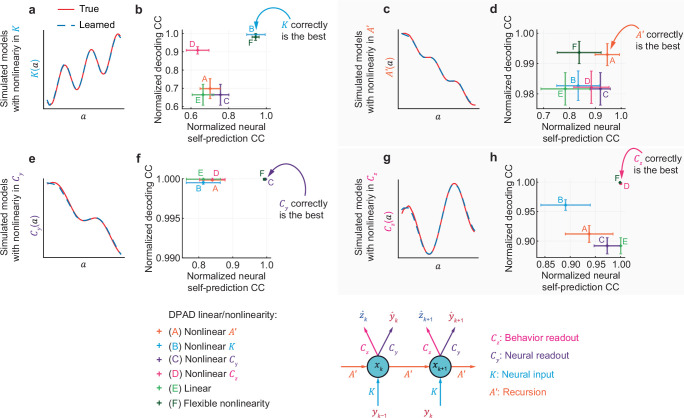
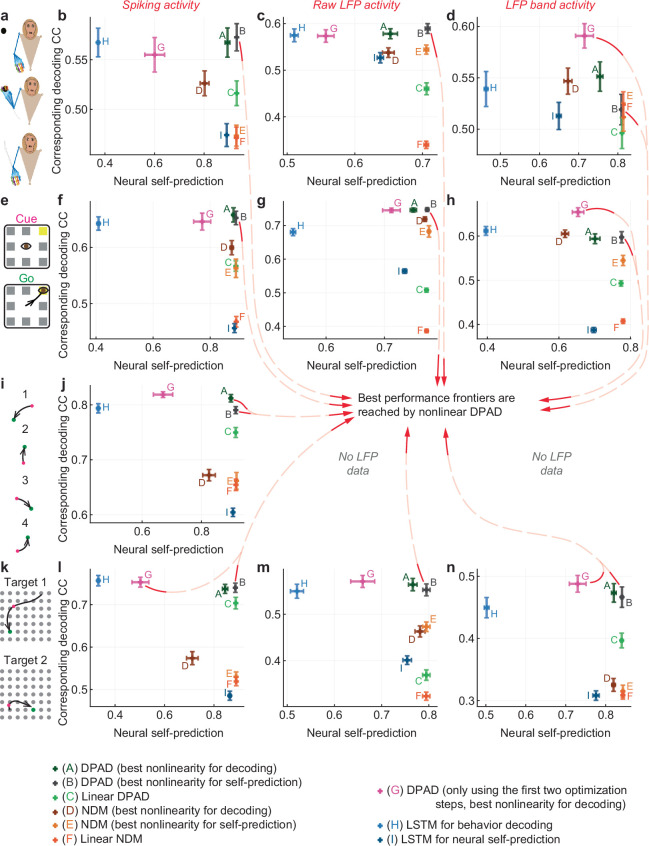
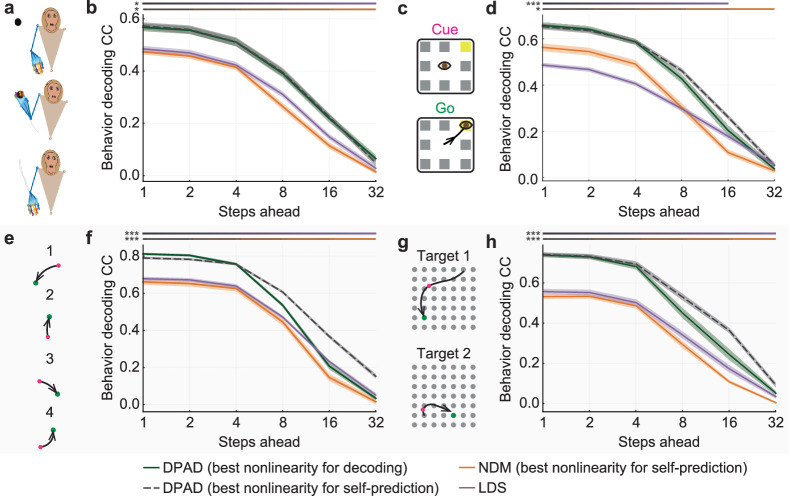
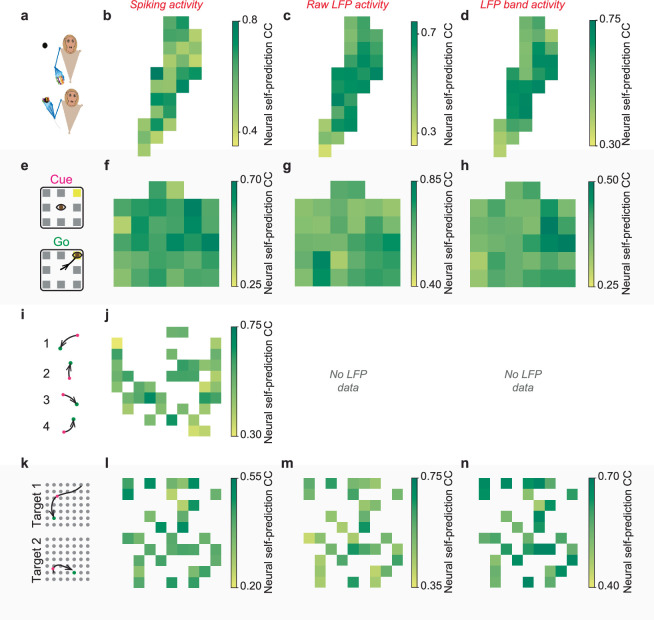
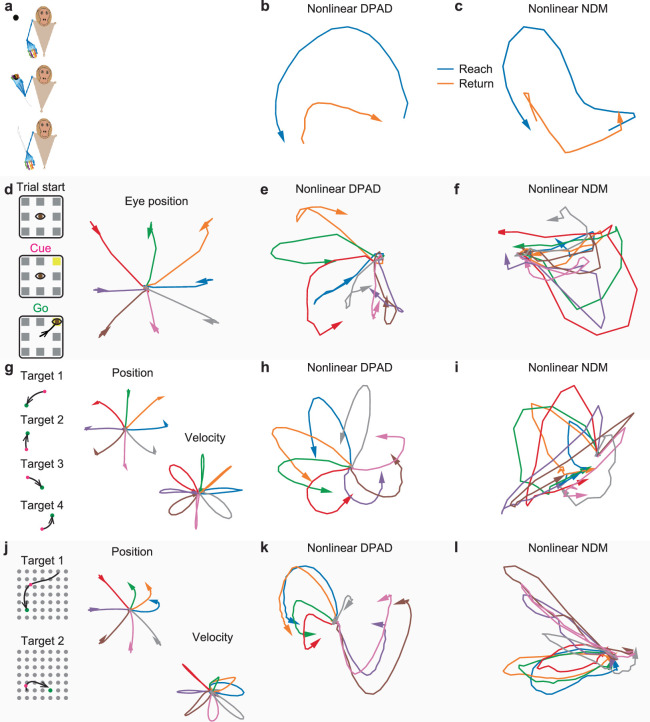
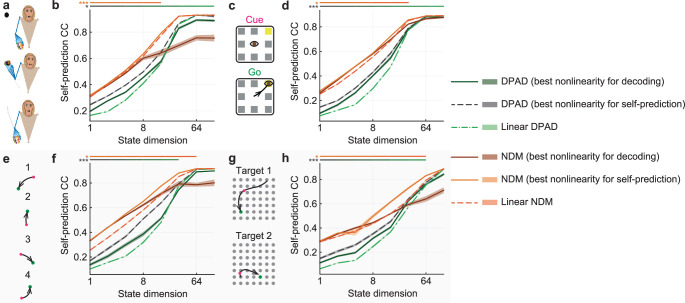
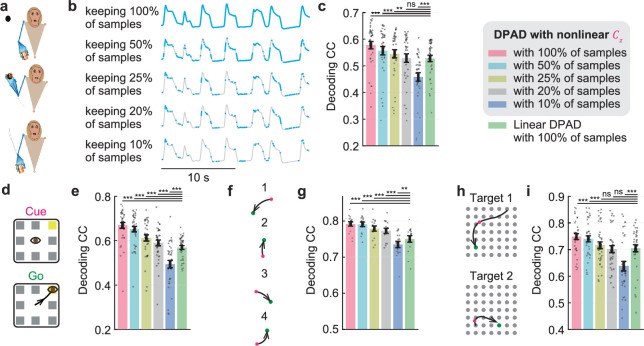
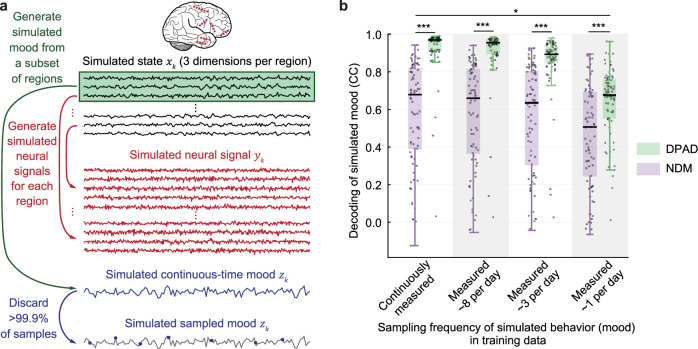
Understanding the dynamical transformation of neural activity to behavior requires new capabilities to nonlinearly model, dissociate and prioritize behaviorally relevant neural dynamics and test hypotheses about the origin of nonlinearity. We present dissociative prioritized analysis of dynamics (DPAD), a nonlinear dynamical modeling approach that enables these capabilities with a multisection neural network architecture and training approach. Analyzing cortical spiking and local field potential activity across four movement tasks, we demonstrate five use-cases. DPAD enabled more accurate neural-behavioral prediction. It identified nonlinear dynamical transformations of local field potentials that were more behavior predictive than traditional power features. Further, DPAD achieved behavior-predictive nonlinear neural dimensionality reduction. It enabled hypothesis testing regarding nonlinearities in neural-behavioral transformation, revealing that, in our datasets, nonlinearities could largely be isolated to the mapping from latent cortical dynamics to behavior. Finally, DPAD extended across continuous, intermittently sampled and categorical behaviors. DPAD provides a powerful tool for nonlinear dynamical modeling and investigation of neural-behavioral data.
© 2024. The Author(s).
Conflict of interest statement
University of Southern California has a patent related to modeling and decoding of shared dynamics between signals in which M.M.S. and O.G.S. are inventors. The other author declares no competing interests.
Figures
References
-
- Macke, J. H. et al. Empirical models of spiking in neural populations. In Advances in Neural Information Processing Systems 24 (eds. Shawe-Taylor, J., Zemel, R. S., Bartlett, P. L., Pereira, F. & Weinberger, K. Q.) 1350–1358 (Curran Associates, 2011).
MeSH terms
Grants and funding
- N00014-19-1-2128/United States Department of Defense | U.S. Navy (United States Navy)
- DP2 MH126378/MH/NIMH NIH HHS/United States
- R61MH135407/U.S. Department of Health & Human Services | National Institutes of Health (NIH)
- R01 MH123770/MH/NIMH NIH HHS/United States
- R01MH123770/U.S. Department of Health & Human Services | National Institutes of Health (NIH)
LinkOut - more resources
Full Text Sources
