

An open-source framework for end-to-end analysis of electronic health record data
- PMID: 39266748
- PMCID: PMC11564094
- DOI: 10.1038/s41591-024-03214-0
An open-source framework for end-to-end analysis of electronic health record data
Abstract
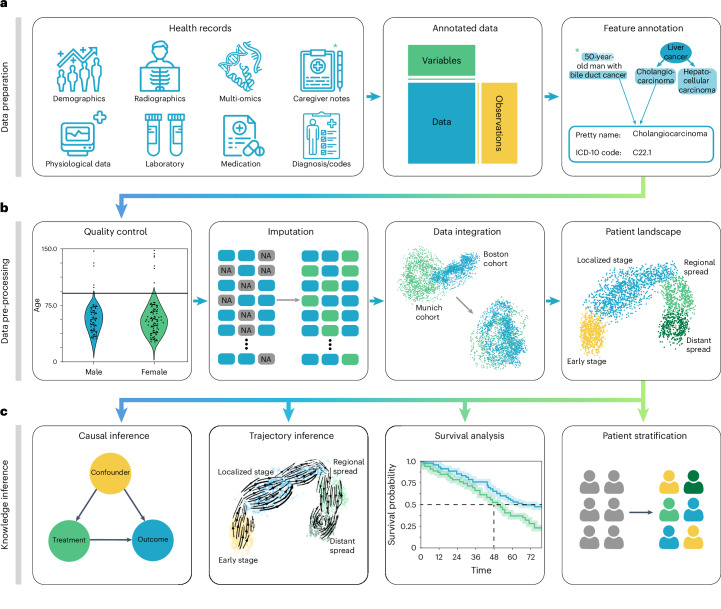
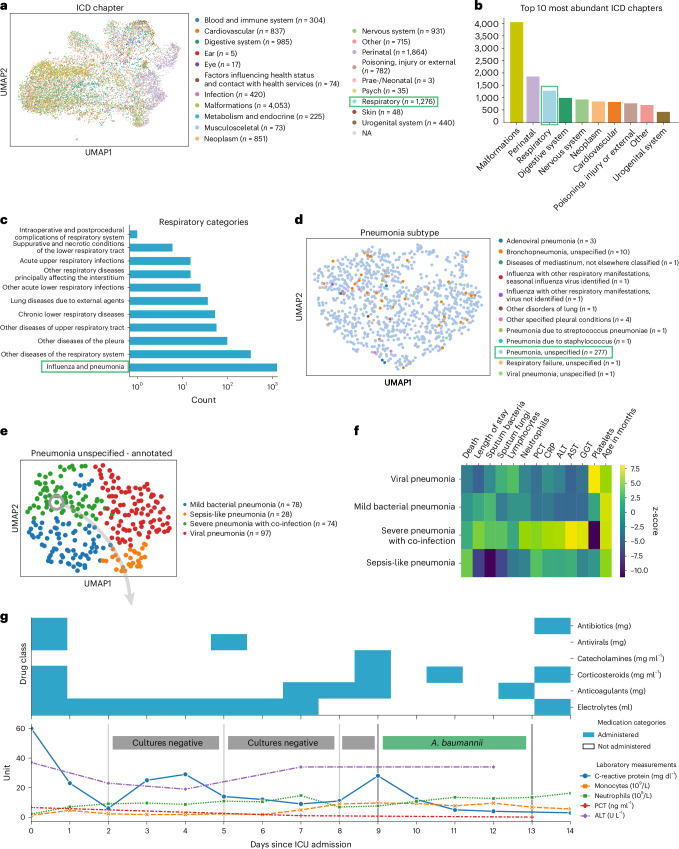
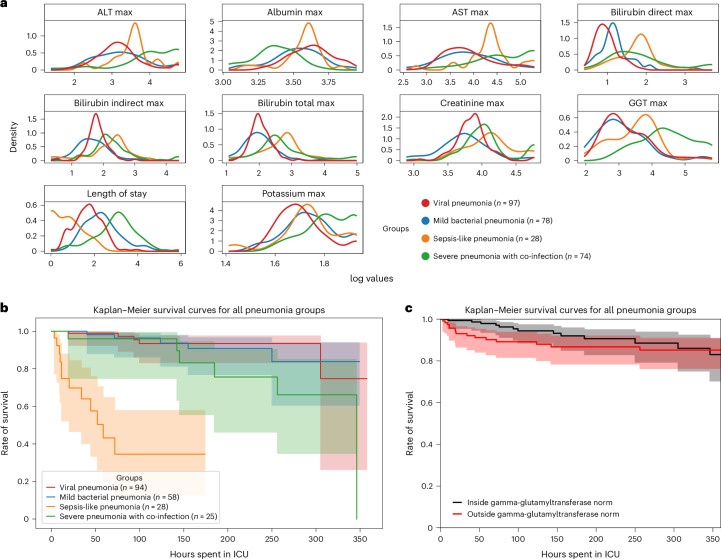
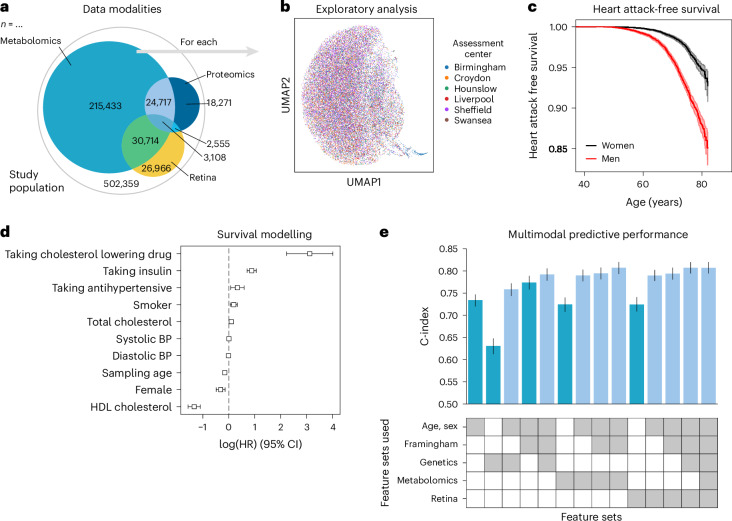
With progressive digitalization of healthcare systems worldwide, large-scale collection of electronic health records (EHRs) has become commonplace. However, an extensible framework for comprehensive exploratory analysis that accounts for data heterogeneity is missing. Here we introduce ehrapy, a modular open-source Python framework designed for exploratory analysis of heterogeneous epidemiology and EHR data. ehrapy incorporates a series of analytical steps, from data extraction and quality control to the generation of low-dimensional representations. Complemented by rich statistical modules, ehrapy facilitates associating patients with disease states, differential comparison between patient clusters, survival analysis, trajectory inference, causal inference and more. Leveraging ontologies, ehrapy further enables data sharing and training EHR deep learning models, paving the way for foundational models in biomedical research. We demonstrate ehrapy's features in six distinct examples. We applied ehrapy to stratify patients affected by unspecified pneumonia into finer-grained phenotypes. Furthermore, we reveal biomarkers for significant differences in survival among these groups. Additionally, we quantify medication-class effects of pneumonia medications on length of stay. We further leveraged ehrapy to analyze cardiovascular risks across different data modalities. We reconstructed disease state trajectories in patients with severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) based on imaging data. Finally, we conducted a case study to demonstrate how ehrapy can detect and mitigate biases in EHR data. ehrapy, thus, provides a framework that we envision will standardize analysis pipelines on EHR data and serve as a cornerstone for the community.
© 2024. The Author(s).
Conflict of interest statement
Figures












References
-
- Goldberger, A. L. et al. PhysioBank, PhysioToolkit, and PhysioNet: components of a new research resource for complex physiologic signals. Circulation101, E215–E220 (2000). - PubMed
-
- Atasoy, H., Greenwood, B. N. & McCullough, J. S. The digitization of patient care: a review of the effects of electronic health records on health care quality and utilization. Annu. Rev. Public Health40, 487–500 (2019). - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
