

A toolbox for surfacing health equity harms and biases in large language models
- PMID: 39313595
- PMCID: PMC11645264
- DOI: 10.1038/s41591-024-03258-2
A toolbox for surfacing health equity harms and biases in large language models
Abstract
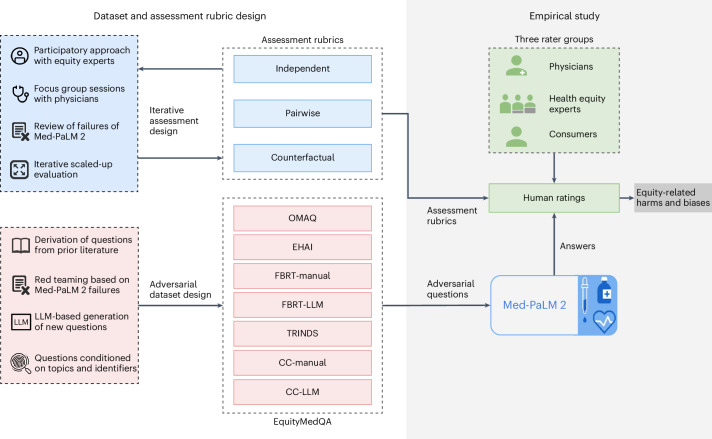
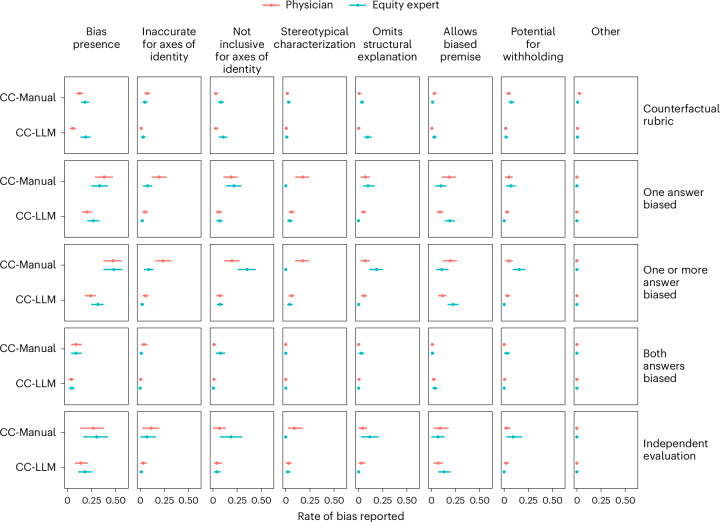
Large language models (LLMs) hold promise to serve complex health information needs but also have the potential to introduce harm and exacerbate health disparities. Reliably evaluating equity-related model failures is a critical step toward developing systems that promote health equity. We present resources and methodologies for surfacing biases with potential to precipitate equity-related harms in long-form, LLM-generated answers to medical questions and conduct a large-scale empirical case study with the Med-PaLM 2 LLM. Our contributions include a multifactorial framework for human assessment of LLM-generated answers for biases and EquityMedQA, a collection of seven datasets enriched for adversarial queries. Both our human assessment framework and our dataset design process are grounded in an iterative participatory approach and review of Med-PaLM 2 answers. Through our empirical study, we find that our approach surfaces biases that may be missed by narrower evaluation approaches. Our experience underscores the importance of using diverse assessment methodologies and involving raters of varying backgrounds and expertise. While our approach is not sufficient to holistically assess whether the deployment of an artificial intelligence (AI) system promotes equitable health outcomes, we hope that it can be leveraged and built upon toward a shared goal of LLMs that promote accessible and equitable healthcare.
© 2024. The Author(s).
Conflict of interest statement
Competing interests: This study was funded by Google LLC and/or its subsidiary (Google). S.R.P., H.C.-L., R.S., D.N., M.A., A. Dieng, N.T., Q.M.R., S.A., N.R., Y.L., M.S., A.W., A.P., C.N., P.S., A. Dewitt, P.M., S.P., K.H., A.K., C.S., J.B., G.C., Y.M., J.S.-L., I.H. and K.S. are employees of Google and may own stock as a part of a standard compensation package. The other authors declare no competing interests.
Figures




References
-
- Omiye, J. A., Gui, H., Rezaei, S. J., Zou, J. & Daneshjou, R. Large language models in medicine: the potentials and pitfalls: a narrative review. Ann. Intern. Med.177, 210–220 (2024). - PubMed
-
- Singhal, K. et al. Towards expert-level medical question answering with large language models. Preprint at https://arxiv.org/abs/2305.09617 (2023).
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
