

This is a preprint.
Adapting Machine Learning Diagnostic Models to New Populations Using a Small Amount of Data: Results from Clinical Neuroscience
- PMID: 39314511
- PMCID: PMC11419182
Adapting Machine Learning Diagnostic Models to New Populations Using a Small Amount of Data: Results from Clinical Neuroscience
Abstract
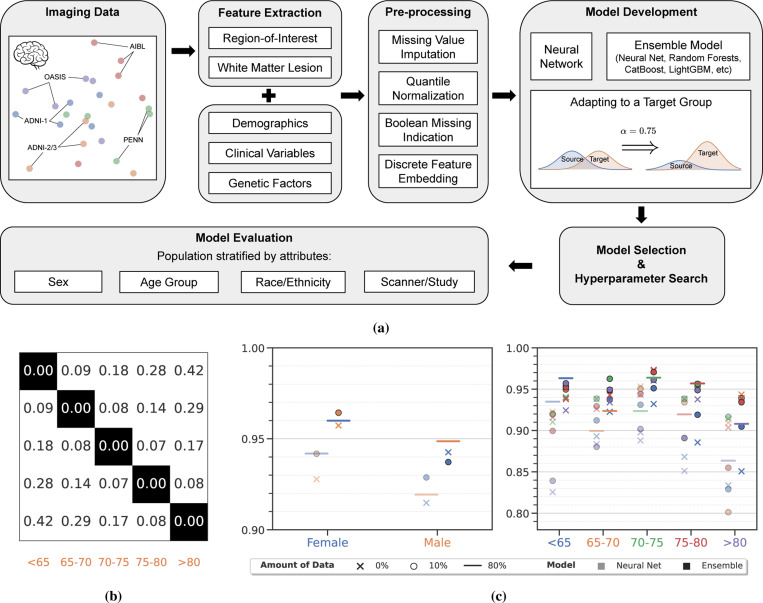
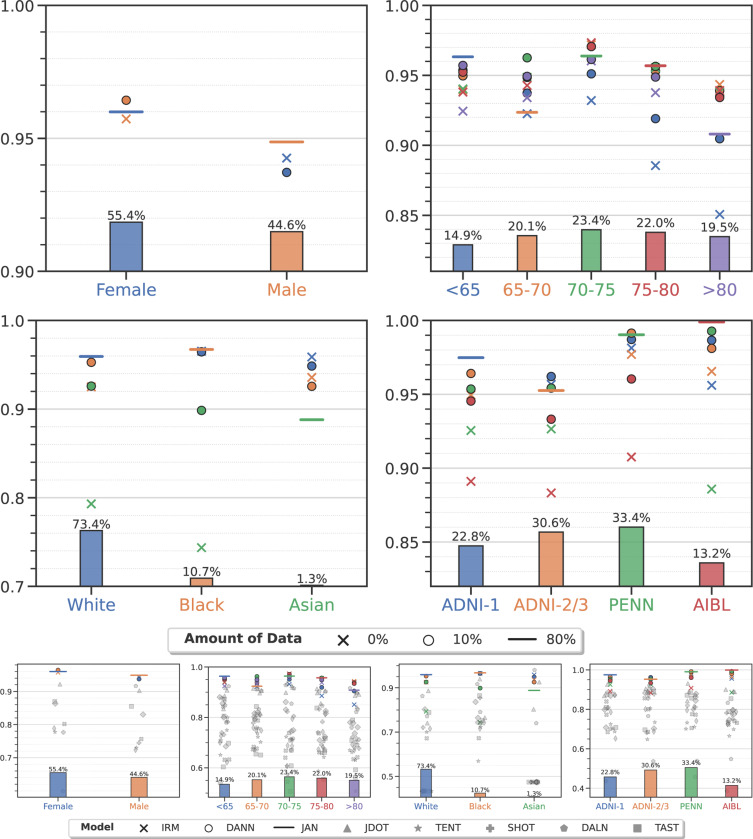
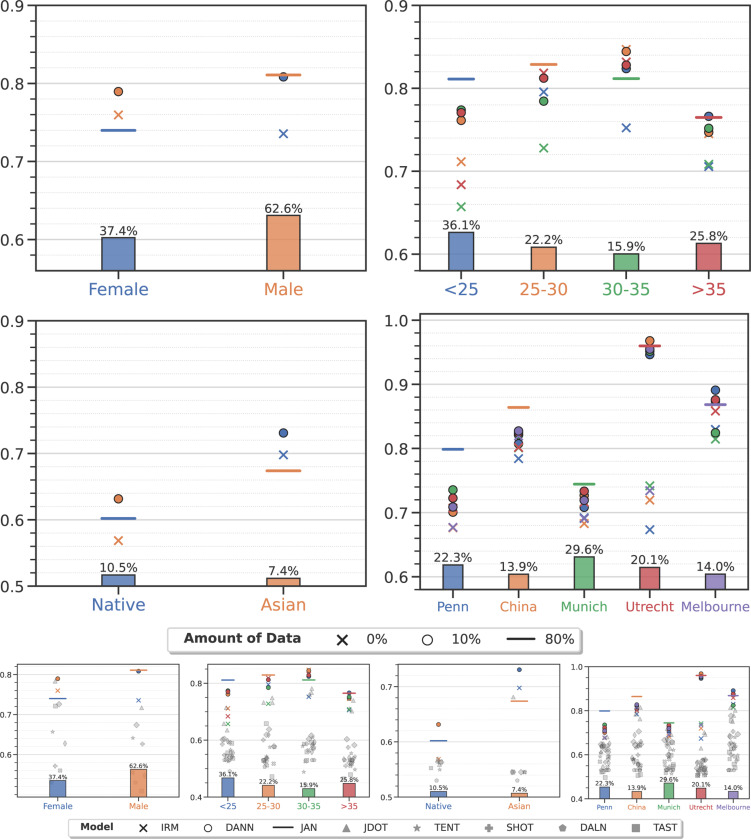
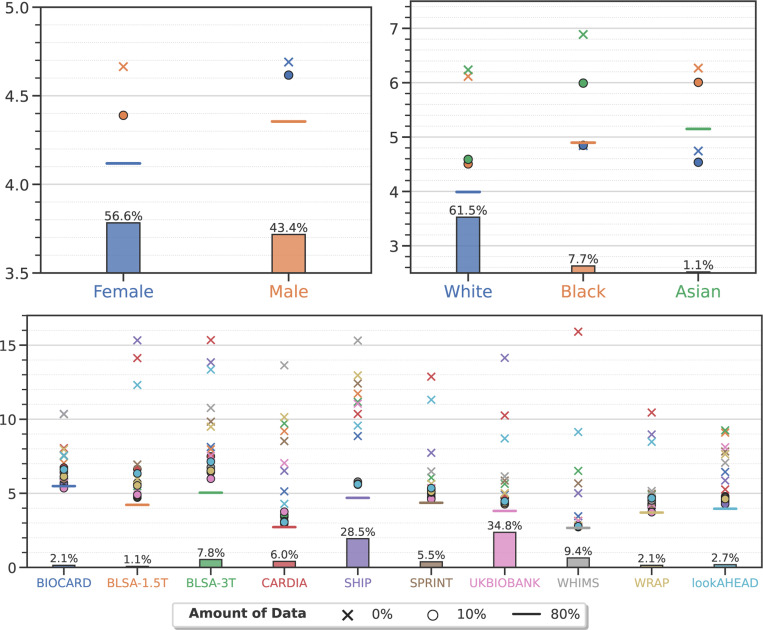
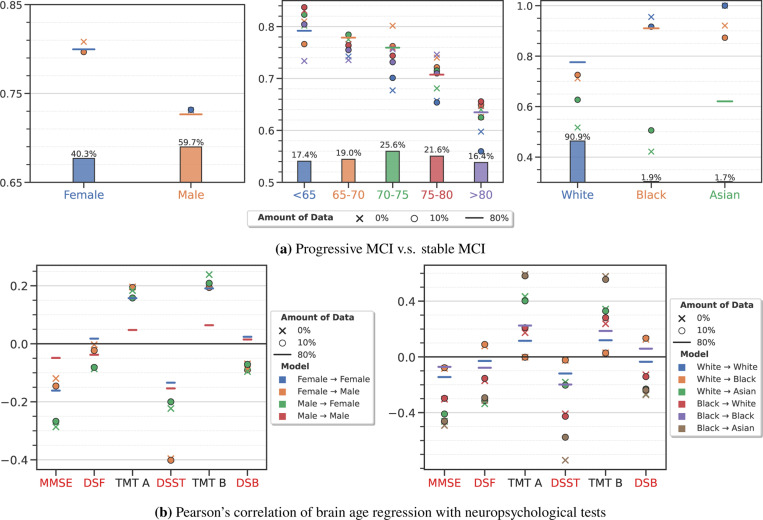
Machine learning (ML) is revolutionizing many areas of engineering and science, including healthcare. However, it is also facing a reproducibility crisis, especially in healthcare. ML models that are carefully constructed from and evaluated on data from one part of the population may not generalize well on data from a different population group, or acquisition instrument settings and acquisition protocols. We tackle this problem in the context of neuroimaging of Alzheimer's disease (AD), schizophrenia (SZ) and brain aging. We develop a weighted empirical risk minimization approach that optimally combines data from a source group, e.g., subjects are stratified by attributes such as sex, age group, race and clinical cohort to make predictions on a target group, e.g., other sex, age group, etc. using a small fraction (10%) of data from the target group. We apply this method to multi-source data of 15,363 individuals from 20 neuroimaging studies to build ML models for diagnosis of AD and SZ, and estimation of brain age. We found that this approach achieves substantially better accuracy than existing domain adaptation techniques: it obtains area under curve greater than 0.95 for AD classification, area under curve greater than 0.7 for SZ classification and mean absolute error less than 5 years for brain age prediction on all target groups, achieving robustness to variations of scanners, protocols, and demographic or clinical characteristics. In some cases, it is even better than training on all data from the target group, because it leverages the diversity and size of a larger training set. We also demonstrate the utility of our models for prognostic tasks such as predicting disease progression in individuals with mild cognitive impairment. Critically, our brain age prediction models lead to new clinical insights regarding correlations with neurophysiological tests. In summary, we present a relatively simple methodology, along with ample experimental evidence, supporting the good generalization of ML models to new datasets and patient cohorts.
Keywords: MRI; distribution shift; domain adaptation; domain generalization; neurological disorder.
Conflict of interest statement
Competing interests The authors declare no competing interests.
Figures
Similar articles
-
Embracing the disharmony in medical imaging: A Simple and effective framework for domain adaptation.Med Image Anal. 2022 Feb;76:102309. doi: 10.1016/j.media.2021.102309. Epub 2021 Nov 26. Med Image Anal. 2022. PMID: 34871931 Free PMC article.
-
Ensemble machine learning model trained on a new synthesized dataset generalizes well for stress prediction using wearable devices.J Biomed Inform. 2023 Dec;148:104556. doi: 10.1016/j.jbi.2023.104556. Epub 2023 Dec 2. J Biomed Inform. 2023. PMID: 38048895
-
Generalization of diffusion magnetic resonance imaging-based brain age prediction model through transfer learning.Neuroimage. 2020 Aug 15;217:116831. doi: 10.1016/j.neuroimage.2020.116831. Epub 2020 May 11. Neuroimage. 2020. PMID: 32438048
-
Machine learning methods for predicting progression from mild cognitive impairment to Alzheimer's disease dementia: a systematic review.Alzheimers Res Ther. 2021 Sep 28;13(1):162. doi: 10.1186/s13195-021-00900-w. Alzheimers Res Ther. 2021. PMID: 34583745 Free PMC article.
-
Structural magnetic resonance imaging for the early diagnosis of dementia due to Alzheimer's disease in people with mild cognitive impairment.Cochrane Database Syst Rev. 2020 Mar 2;3(3):CD009628. doi: 10.1002/14651858.CD009628.pub2. Cochrane Database Syst Rev. 2020. PMID: 32119112 Free PMC article.
References
-
- Habes M., Pomponio R., Shou H., Doshi J., Mamourian E., Erus G., Nasrallah I., Launer L. J., Rashid T., Bilgel M., et al. The Brain Chart of Aging: Machine-learning Analytics Reveals Links between Brain Aging, White Matter Disease, Amyloid Burden, and Cognition in the iSTAGING Consortium of 10,216 Harmonized MR Scans. Alzheimer’s & Dementia 17, 89–102 (2021). - PMC - PubMed
-
- Jack C. R. Jr, Bernstein M. A., Fox N. C., Thompson P., Alexander G., Harvey D., Borowski B., Britson P. J., L. Whitwell J., Ward C., et al. The Alzheimer’s Disease Neuroimaging Initiative (ADNI): MRI Methods. Journal of Magnetic Resonance Imaging: An Official Journal of the International Society for Magnetic Resonance in Medicine 27, 685–691 (2008). - PMC - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources