

Comparative modeling reveals the molecular determinants of aneuploidy fitness cost in a wild yeast model
- PMID: 39317188
- PMCID: PMC11602619
- DOI: 10.1016/j.xgen.2024.100656
Comparative modeling reveals the molecular determinants of aneuploidy fitness cost in a wild yeast model
Abstract
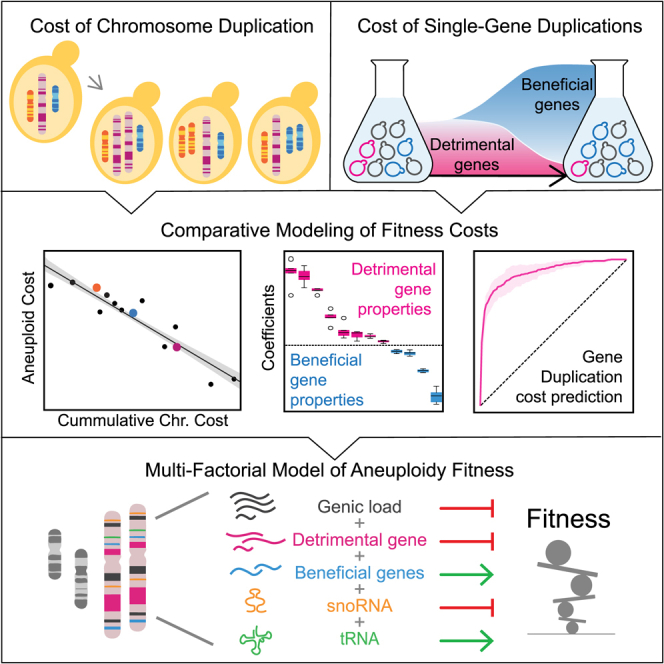
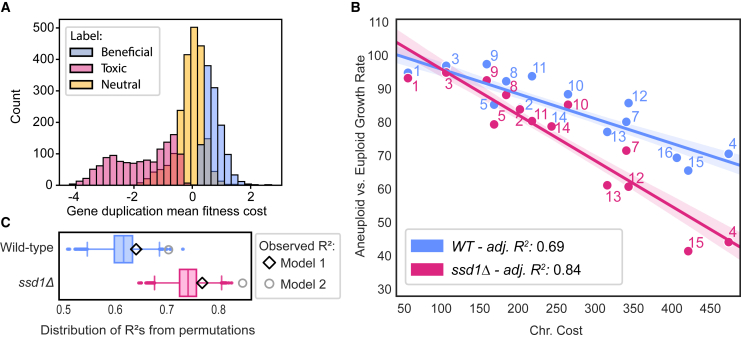
Although implicated as deleterious in many organisms, aneuploidy can underlie rapid phenotypic evolution. However, aneuploidy will be maintained only if the benefit outweighs the cost, which remains incompletely understood. To quantify this cost and the molecular determinants behind it, we generated a panel of chromosome duplications in Saccharomyces cerevisiae and applied comparative modeling and molecular validation to understand aneuploidy toxicity. We show that 74%-94% of the variance in aneuploid strains' growth rates is explained by the cumulative cost of genes on each chromosome, measured for single-gene duplications using a genomic library, along with the deleterious contribution of small nucleolar RNAs (snoRNAs) and beneficial effects of tRNAs. Machine learning to identify properties of detrimental gene duplicates provided no support for the balance hypothesis of aneuploidy toxicity and instead identified gene length as the best predictor of toxicity. Our results present a generalized framework for the cost of aneuploidy with implications for disease biology and evolution.
Keywords: CNV; aneuploidy; balance hypothesis; dosage-sensitive genes; driver genes; genic load; snoRNA; tRNA.
Copyright © 2024 The Author(s). Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
Declaration of interests The authors have no competing interests to declare.
Figures





Update of
-
Comparative modeling reveals the molecular determinants of aneuploidy fitness cost in a wild yeast model.bioRxiv [Preprint]. 2024 Apr 13:2024.04.09.588778. doi: 10.1101/2024.04.09.588778. bioRxiv. 2024. Update in: Cell Genom. 2024 Oct 9;4(10):100656. doi: 10.1016/j.xgen.2024.100656. PMID: 38645209 Free PMC article. Updated. Preprint.
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
