

Human versus Artificial Intelligence: ChatGPT-4 Outperforming Bing, Bard, ChatGPT-3.5 and Humans in Clinical Chemistry Multiple-Choice Questions
- PMID: 39319062
- PMCID: PMC11421444
- DOI: 10.2147/AMEP.S479801
Human versus Artificial Intelligence: ChatGPT-4 Outperforming Bing, Bard, ChatGPT-3.5 and Humans in Clinical Chemistry Multiple-Choice Questions
Abstract
Introduction: Artificial intelligence (AI) chatbots excel in language understanding and generation. These models can transform healthcare education and practice. However, it is important to assess the performance of such AI models in various topics to highlight its strengths and possible limitations. This study aimed to evaluate the performance of ChatGPT (GPT-3.5 and GPT-4), Bing, and Bard compared to human students at a postgraduate master's level in Medical Laboratory Sciences.
Methods: The study design was based on the METRICS checklist for the design and reporting of AI-based studies in healthcare. The study utilized a dataset of 60 Clinical Chemistry multiple-choice questions (MCQs) initially conceived for assessing 20 MSc students. The revised Bloom's taxonomy was used as the framework for classifying the MCQs into four cognitive categories: Remember, Understand, Analyze, and Apply. A modified version of the CLEAR tool was used for the assessment of the quality of AI-generated content, with Cohen's κ for inter-rater agreement.
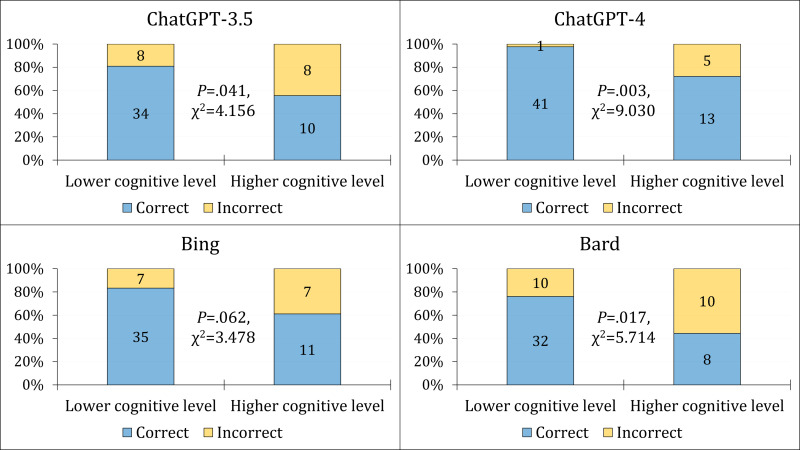
Results: Compared to the mean students' score which was 0.68±0.23, GPT-4 scored 0.90 ± 0.30, followed by Bing (0.77 ± 0.43), GPT-3.5 (0.73 ± 0.45), and Bard (0.67 ± 0.48). Statistically significant better performance was noted in lower cognitive domains (Remember and Understand) in GPT-3.5 (P=0.041), GPT-4 (P=0.003), and Bard (P=0.017) compared to the higher cognitive domains (Apply and Analyze). The CLEAR scores indicated that ChatGPT-4 performance was "Excellent" compared to the "Above average" performance of ChatGPT-3.5, Bing, and Bard.
Discussion: The findings indicated that ChatGPT-4 excelled in the Clinical Chemistry exam, while ChatGPT-3.5, Bing, and Bard were above average. Given that the MCQs were directed to postgraduate students with a high degree of specialization, the performance of these AI chatbots was remarkable. Due to the risk of academic dishonesty and possible dependence on these AI models, the appropriateness of MCQs as an assessment tool in higher education should be re-evaluated.
Keywords: AI in healthcare education; evaluation; higher education; large language models.
© 2024 Sallam et al.
Conflict of interest statement
The authors report no conflicts of interest in this work.
Figures
References
-
- Chiu TKF. Future research recommendations for transforming higher education with generative AI. Comp Educat. 100197. doi: 10.1016/j.caeai.2023.100197 - DOI
-
- Rawas S. ChatGPT: empowering lifelong learning in the digital age of higher education. Educat Inform Technol. 2023. doi: 10.1007/s10639-023-12114-8 - DOI
-
- Rahiman HU, Kodikal R. Revolutionizing education: artificial intelligence empowered learning in higher education. Cogent Educat. 2024;11:2293431. doi: 10.1080/2331186X.2023.2293431 - DOI
-
- Crompton H, Burke D. Artificial intelligence in higher education: the state of the field. Int J Educa Technol High Educ. 2023;20:22. doi: 10.1186/s41239-023-00392-8 - DOI
LinkOut - more resources
Full Text Sources
