

Larger and more instructable language models become less reliable
- PMID: 39322679
- PMCID: PMC11446866
- DOI: 10.1038/s41586-024-07930-y
Larger and more instructable language models become less reliable
Abstract
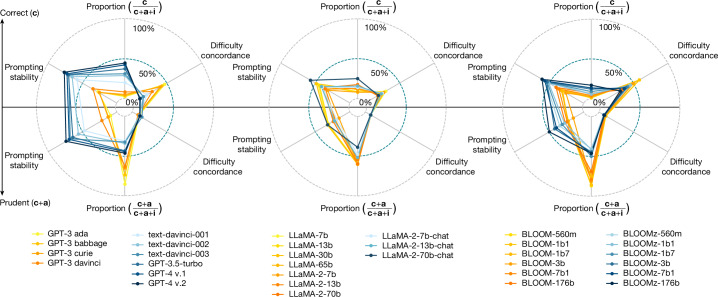
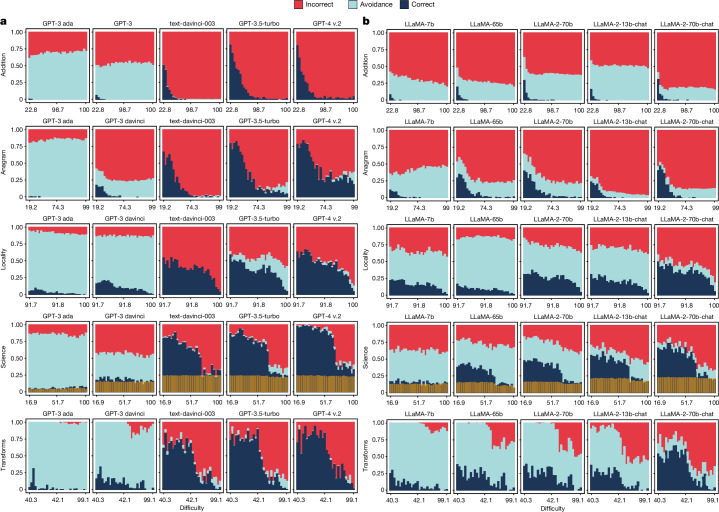
The prevailing methods to make large language models more powerful and amenable have been based on continuous scaling up (that is, increasing their size, data volume and computational resources1) and bespoke shaping up (including post-filtering2,3, fine tuning or use of human feedback4,5). However, larger and more instructable large language models may have become less reliable. By studying the relationship between difficulty concordance, task avoidance and prompting stability of several language model families, here we show that easy instances for human participants are also easy for the models, but scaled-up, shaped-up models do not secure areas of low difficulty in which either the model does not err or human supervision can spot the errors. We also find that early models often avoid user questions but scaled-up, shaped-up models tend to give an apparently sensible yet wrong answer much more often, including errors on difficult questions that human supervisors frequently overlook. Moreover, we observe that stability to different natural phrasings of the same question is improved by scaling-up and shaping-up interventions, but pockets of variability persist across difficulty levels. These findings highlight the need for a fundamental shift in the design and development of general-purpose artificial intelligence, particularly in high-stakes areas for which a predictable distribution of errors is paramount.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests. Some authors received economic compensation for red teaming some of the models that appear in this study, as well as for red teaming other models created by the same companies.
Figures






References
-
- Kaplan, J. et al. Scaling laws for neural language. Preprint at https://arxiv.org/abs/2001.08361 (2020).
-
- Markov, T. et al. A holistic approach to undesired content detection in the real world. In Proc. AAAI Conference on Artificial Intelligence 15009–15018 (PKP Publishing Services, 2023).
-
- OpenAI. GPT-4 technical report. Preprint at https://arxiv.org/abs/2303.08774 (2023).
-
- Chung, H. W. et al. Scaling instruction-finetuned language models. J. Mach. Learn. Res.25, 1–53 (2024).
-
- Ouyang, L. et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst.35, 27730–27744 (2022).
MeSH terms
LinkOut - more resources
Full Text Sources
