

Decoding the diagnostic and therapeutic potential of microbiota using pan-body pan-disease microbiomics
- PMID: 39327438
- PMCID: PMC11427559
- DOI: 10.1038/s41467-024-52598-7
Decoding the diagnostic and therapeutic potential of microbiota using pan-body pan-disease microbiomics
Abstract
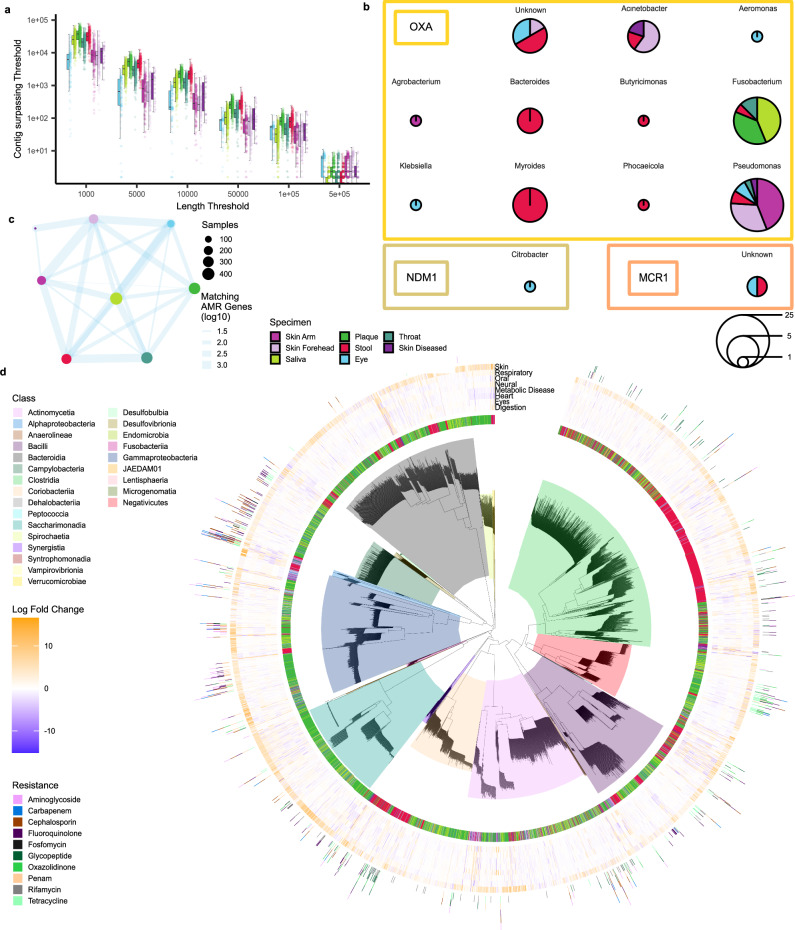
The human microbiome emerges as a promising reservoir for diagnostic markers and therapeutics. Since host-associated microbiomes at various body sites differ and diseases do not occur in isolation, a comprehensive analysis strategy highlighting the full potential of microbiomes should include diverse specimen types and various diseases. To ensure robust data quality and comparability across specimen types and diseases, we employ standardized protocols to generate sequencing data from 1931 prospectively collected specimens, including from saliva, plaque, skin, throat, eye, and stool, with an average sequencing depth of 5.3 gigabases. Collected from 515 patients, these samples yield an average of 3.7 metagenomes per patient. Our results suggest significant microbial variations across diseases and specimen types, including unexpected anatomical sites. We identify 583 unexplored species-level genome bins (SGBs) of which 189 are significantly disease-associated. Of note, the existence of microbial resistance genes in one specimen was indicative of the same resistance genes in other specimens of the same patient. Annotated and previously undescribed SGBs collectively harbor 28,315 potential biosynthetic gene clusters (BGCs), with 1050 significant correlations to diseases. Our combinatorial approach identifies distinct SGBs and BGCs, emphasizing the value of pan-body pan-disease microbiomics as a source for diagnostic and therapeutic strategies.
© 2024. The Author(s).
Conflict of interest statement
G.P.S., R.M., and A.K. are co-founders of MooH GmbH, a company developing metagenomic based oral health tests. FM is supported by Deutsche Gesellschaft für Kardiologie (DGK), Deutsche Forschungsgemeinschaft (SFB TRR219, Project-ID 322900939), and Deutsche Herzstiftung. His institution (Saarland University) has received scientific support from Ablative Solutions, Medtronic, and ReCor Medical. He has received speaker honoraria/consulting fees from Ablative Solutions, Amgen, Astra-Zeneca, Bayer, Boehringer Ingelheim, Inari, Medtronic, Merck, ReCor Medical, Servier, and Terumo. The remaining authors declare no competing interests.
Figures



References
-
- Kahrstrom, C. T., Pariente, N. & Weiss, U. Intestinal microbiota in health and disease. Nature535, 47 (2016). - PubMed
-
- Katsanos, A. H. et al. in Biomarkers for Endometriosis: State of the Art (ed Thomas D’Hooghe) 41-75 (Springer International Publishing, 2017).
Publication types
MeSH terms
Associated data
LinkOut - more resources
Full Text Sources
