

Task-Adaptive Angle Selection for Computed Tomography-Based Defect Detection
- PMID: 39330428
- PMCID: PMC11433431
- DOI: 10.3390/jimaging10090208
Task-Adaptive Angle Selection for Computed Tomography-Based Defect Detection
Abstract
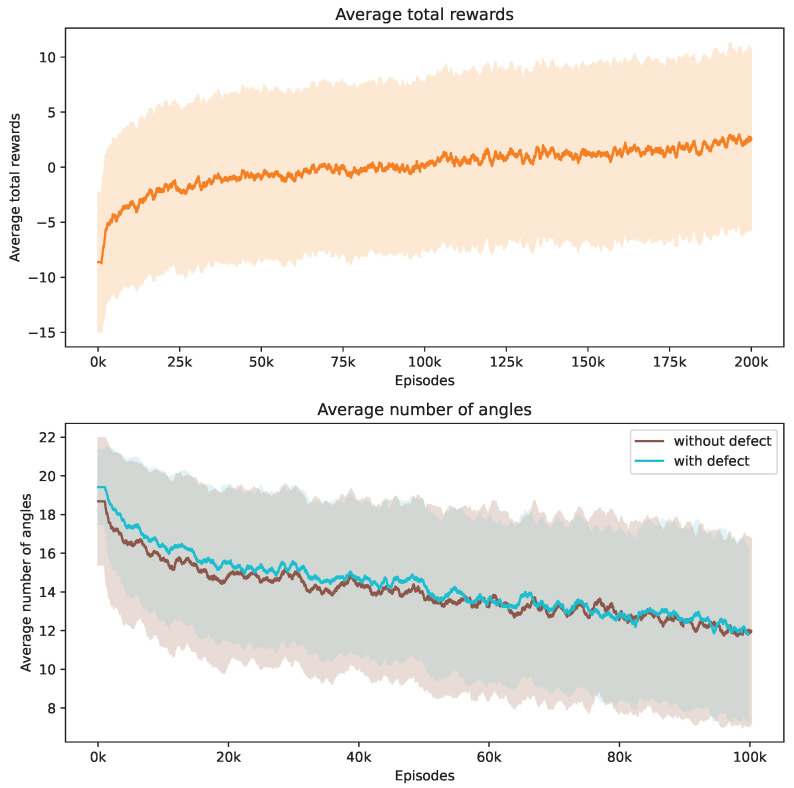
Sparse-angle X-ray Computed Tomography (CT) plays a vital role in industrial quality control but leads to an inherent trade-off between scan time and reconstruction quality. Adaptive angle selection strategies try to improve upon this based on the idea that the geometry of the object under investigation leads to an uneven distribution of the information content over the projection angles. Deep Reinforcement Learning (DRL) has emerged as an effective approach for adaptive angle selection in X-ray CT. While previous studies focused on optimizing generic image quality measures using a fixed number of angles, our work extends them by considering a specific downstream task, namely image-based defect detection, and introducing flexibility in the number of angles used. By leveraging prior knowledge about typical defect characteristics, our task-adaptive angle selection method, adaptable in terms of angle count, enables easy detection of defects in the reconstructed images.
Keywords: adaptive angle selection; computed tomography; deep learning; defect detection; reinforcement learning.
Conflict of interest statement
The authors declare no conflicts of interest. The funders had no role in the design of this study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Figures














References
-
- Kazantsev I. Information content of projections. Inverse Probl. 1991;7:887. doi: 10.1088/0266-5611/7/6/010. - DOI
-
- Batenburg K.J., Palenstijn W.J., Balázs P., Sijbers J. Dynamic angle selection in binary tomography. Comput. Vis. Image Underst. 2013;117:306–318.
-
- Dabravolski A., Batenburg K.J., Sijbers J. Dynamic angle selection in X-ray computed tomography. Nucl. Instruments Methods Phys. Res. Sect. B Beam Interact. Mater. Atoms. 2014;324:17–24.
-
- Burger M., Hauptmann A., Helin T., Hyvönen N., Puska J.P. Sequentially optimized projections in X-ray imaging. Inverse Probl. 2021;37:075006.
Grants and funding
LinkOut - more resources
Full Text Sources
