

Tracking neurons across days with high-density probes
- PMID: 39333269
- PMCID: PMC11978519
- DOI: 10.1038/s41592-024-02440-1
Tracking neurons across days with high-density probes
Abstract
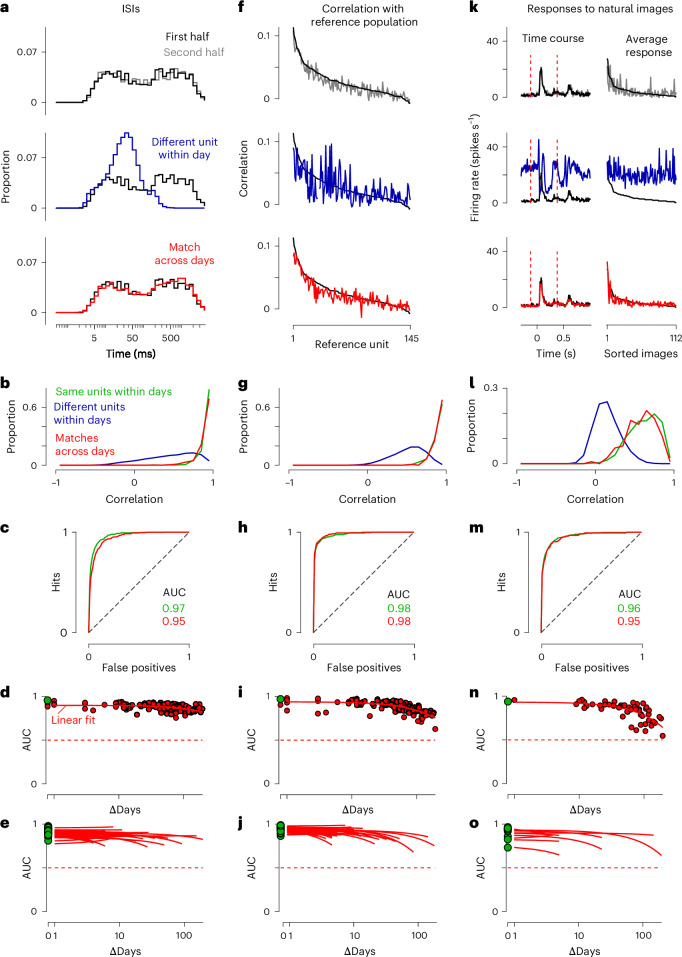
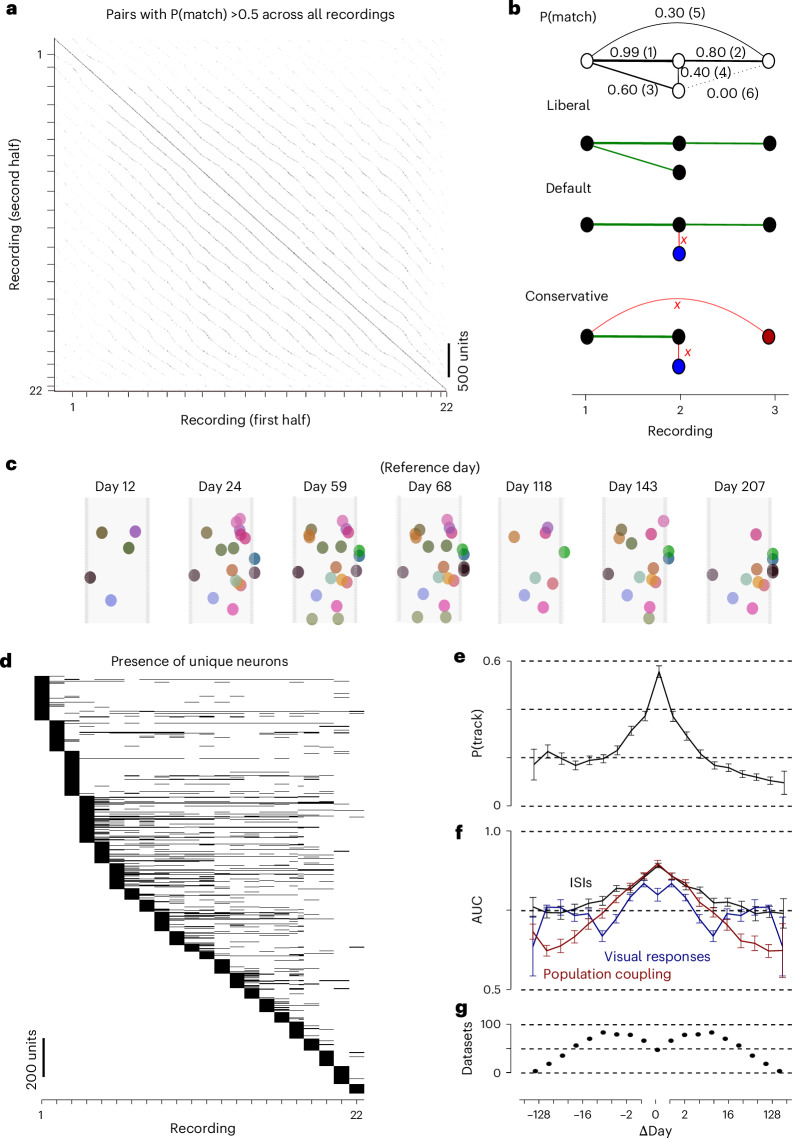
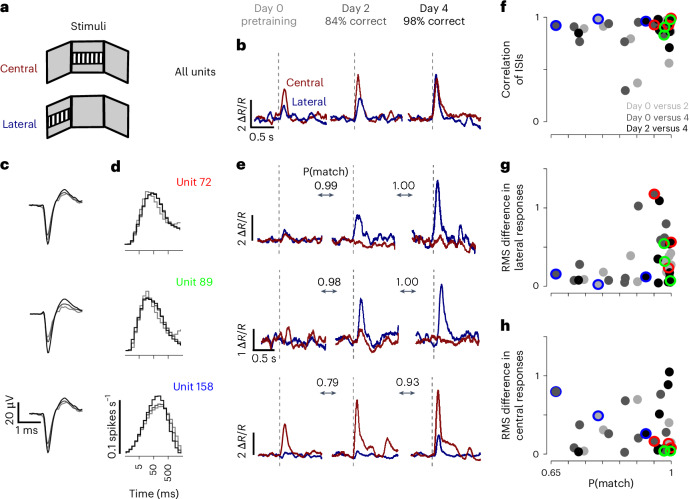
Neural activity spans multiple time scales, from milliseconds to months. Its evolution can be recorded with chronic high-density arrays such as Neuropixels probes, which can measure each spike at tens of sites and record hundreds of neurons. These probes produce vast amounts of data that require different approaches for tracking neurons across recordings. Here, to meet this need, we developed UnitMatch, a pipeline that operates after spike sorting, based only on each unit's average spike waveform. We tested UnitMatch in Neuropixels recordings from the mouse brain, where it tracked neurons across weeks. Across the brain, neurons had distinctive inter-spike interval distributions. Their correlations with other neurons remained stable over weeks. In the visual cortex, the neurons' selectivity for visual stimuli remained similarly stable. In the striatum, however, neuronal responses changed across days during learning of a task. UnitMatch is thus a promising tool to reveal both invariance and plasticity in neural activity across days.
© 2024. Crown.
Conflict of interest statement
Competing interests: The authors declare no competing interests.
Figures









References
-
- Deitch, D., Rubin, A. & Ziv, Y. Representational drift in the mouse visual cortex. Curr. Biol.31, 4327–4339.e6 (2021). - PubMed
MeSH terms
Grants and funding
- 101022757/EC | Horizon 2020 Framework Programme (EU Framework Programme for Research and Innovation H2020)
- 227065/WT_/Wellcome Trust/United Kingdom
- BB/T016639/1/RCUK | Biotechnology and Biological Sciences Research Council (BBSRC)
- 223144/WT_/Wellcome Trust/United Kingdom
- WT_/Wellcome Trust/United Kingdom
LinkOut - more resources
Full Text Sources
