

DINO-Mix enhancing visual place recognition with foundational vision model and feature mixing
- PMID: 39333370
- PMCID: PMC11437288
- DOI: 10.1038/s41598-024-73853-3
DINO-Mix enhancing visual place recognition with foundational vision model and feature mixing
Abstract
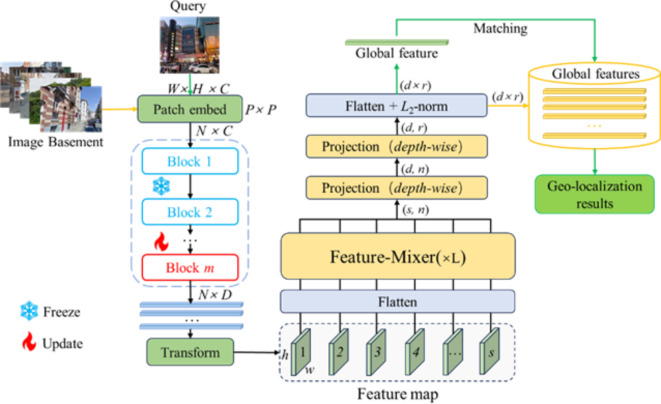
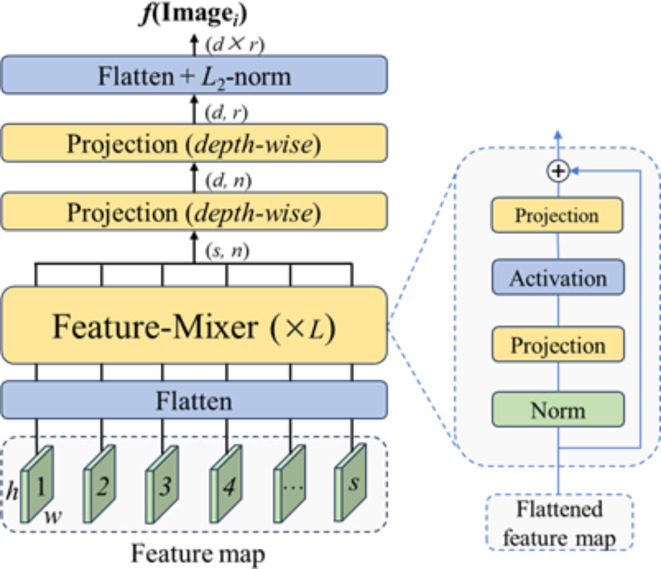
Using visual place recognition (VPR) technology to ascertain the geographical location of publicly available images is a pressing issue. Although most current VPR methods achieve favorable results under ideal conditions, their performance in complex environments, characterized by lighting variations, seasonal changes, and occlusions, is generally unsatisfactory. Therefore, obtaining efficient and robust image feature descriptors in complex environments is a pressing issue. In this study, we utilized the DINOv2 model as the backbone for trimming and fine-tuning to extract robust image features and employed a feature mix module to aggregate image features, resulting in globally robust and generalizable descriptors that enable high-precision VPR. We experimentally demonstrated that the proposed DINO-Mix outperforms the current state-of-the-art (SOTA) methods. Using test sets having lighting variations, seasonal changes, and occlusions such as Tokyo24/7, Nordland, and SF-XL-Testv1, our proposed architecture achieved Top-1 accuracy rates of 91.75%, 80.18%, and 82%, respectively, and exhibited an average accuracy improvement of 5.14%. In addition, we compared it with other SOTA methods using representative image retrieval case studies, and our architecture outperformed its competitors in terms of VPR performance. Furthermore, we visualized the attention maps of DINO-Mix and other methods to provide a more intuitive understanding of their respective strengths. These visualizations serve as compelling evidence of the superiority of the DINO-Mix framework in this domain.
Keywords: DINOv2; Feature mixer; Foundational vision model; Image retrieval; Visual place recognition.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures







References
-
- Middelberg, S., Sattler, T., Untzelmann, O. & Kobbelt, L. Scalable 6-DOF Localization on Mobile Devices. in (eds. Fleet, D., Pajdla, T., Schiele, B. & Tuytelaars, T.) vol. 8690 268–283 (2014).
-
- Suenderhauf, N. et al. Place Recognition with ConvNet Landmarks: Viewpoint-Robust, Condition-Robust, Training-Free. in Robotics: Science and Systems XI (Robotics: Science and Systems Foundation, doi: (2015). 10.15607/RSS.2015.XI.022
-
- Chaabane, M., Gueguen, L., Trabelsi, A., Beveridge, R. & O’Hara, S. End-to-end Learning Improves Static Object Geo-localization from Video. in Ieee Winter Conference on Applications of Computer Vision Wacv 2021 2062–2071 (Ieee, New York, 2021). doi: (2021). 10.1109/WACV48630.2021.00211
-
- Wilson, D. et al. Object Tracking and Geo-localization from Street images. Remote Sens. 14, 2575 (2022). - DOI
-
- Agarwal, S., Snavely, N., Simon, I., Seitz, S. M. & Szeliski, R. Building Rome in a Day. in IEEE 12th International Conference on Computer Vision (ICCV) 72–79 (2009). doi: (2009). 10.1109/ICCV.2009.5459148
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
