

"Doctor ChatGPT, Can You Help Me?" The Patient's Perspective: Cross-Sectional Study
- PMID: 39352738
- PMCID: PMC11480680
- DOI: 10.2196/58831
"Doctor ChatGPT, Can You Help Me?" The Patient's Perspective: Cross-Sectional Study
Abstract
Background: Artificial intelligence and the language models derived from it, such as ChatGPT, offer immense possibilities, particularly in the field of medicine. It is already evident that ChatGPT can provide adequate and, in some cases, expert-level responses to health-related queries and advice for patients. However, it is currently unknown how patients perceive these capabilities, whether they can derive benefit from them, and whether potential risks, such as harmful suggestions, are detected by patients.
Objective: This study aims to clarify whether patients can get useful and safe health care advice from an artificial intelligence chatbot assistant.
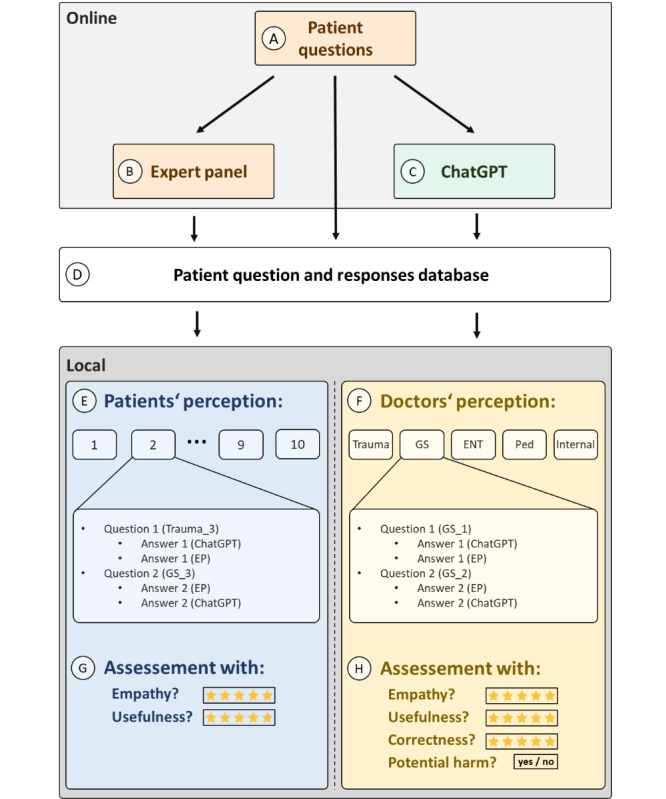
Methods: This cross-sectional study was conducted using 100 publicly available health-related questions from 5 medical specialties (trauma, general surgery, otolaryngology, pediatrics, and internal medicine) from a web-based platform for patients. Responses generated by ChatGPT-4.0 and by an expert panel (EP) of experienced physicians from the aforementioned web-based platform were packed into 10 sets consisting of 10 questions each. The blinded evaluation was carried out by patients regarding empathy and usefulness (assessed through the question: "Would this answer have helped you?") on a scale from 1 to 5. As a control, evaluation was also performed by 3 physicians in each respective medical specialty, who were additionally asked about the potential harm of the response and its correctness.
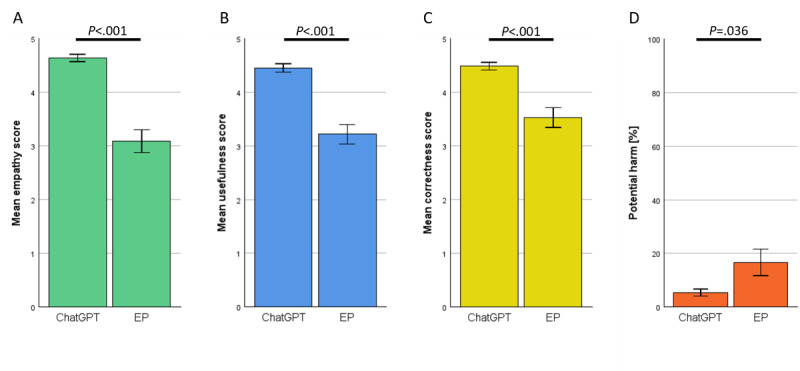
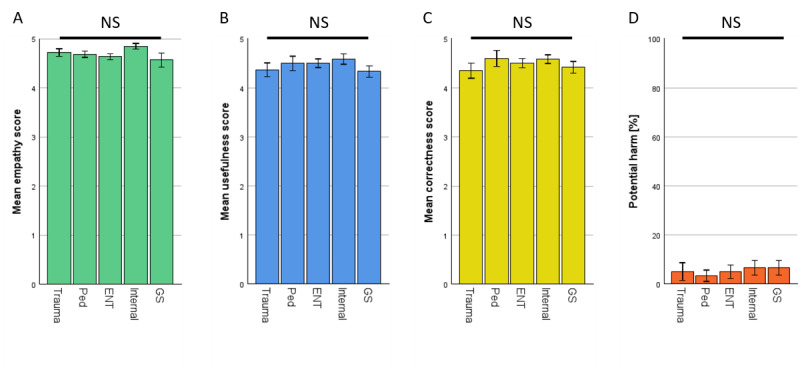
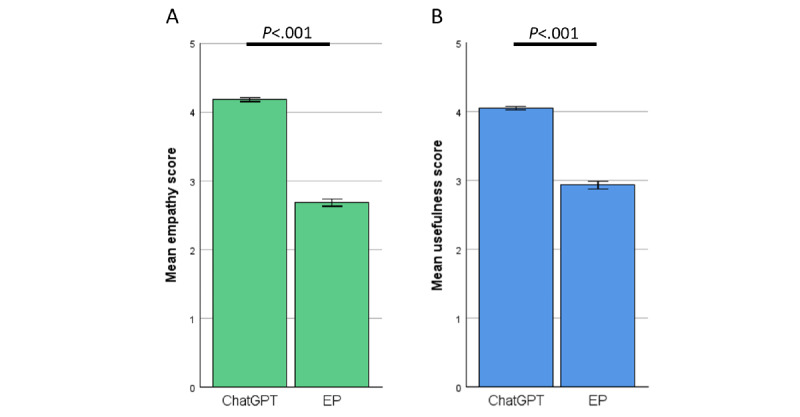
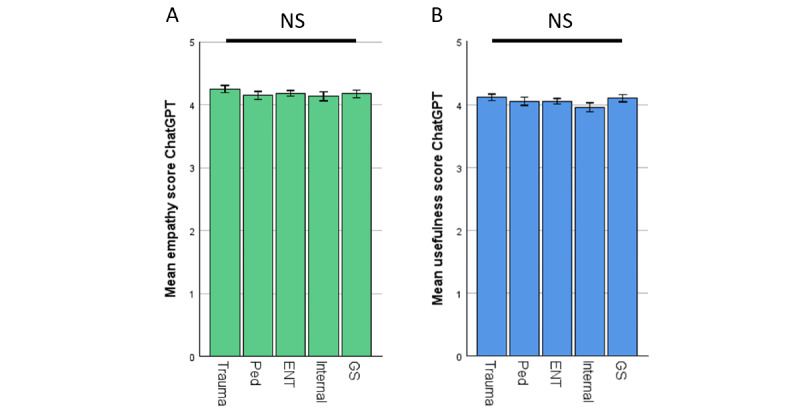
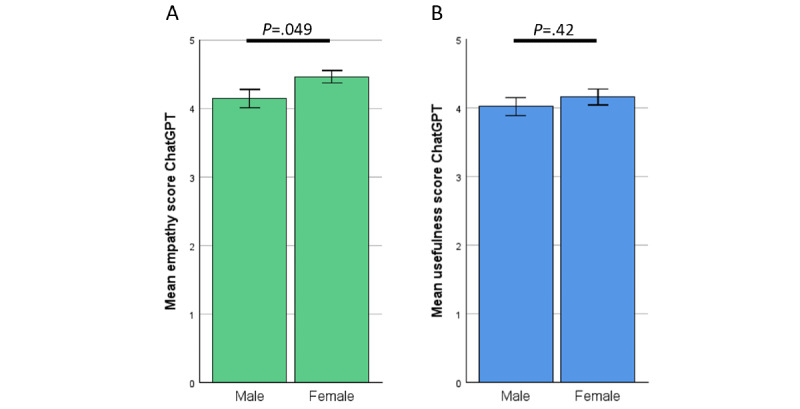
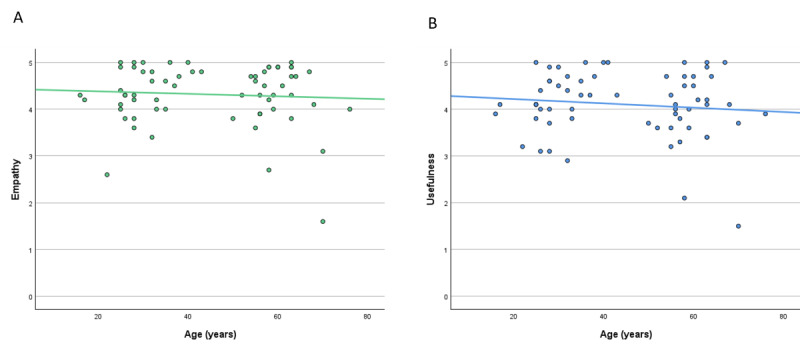
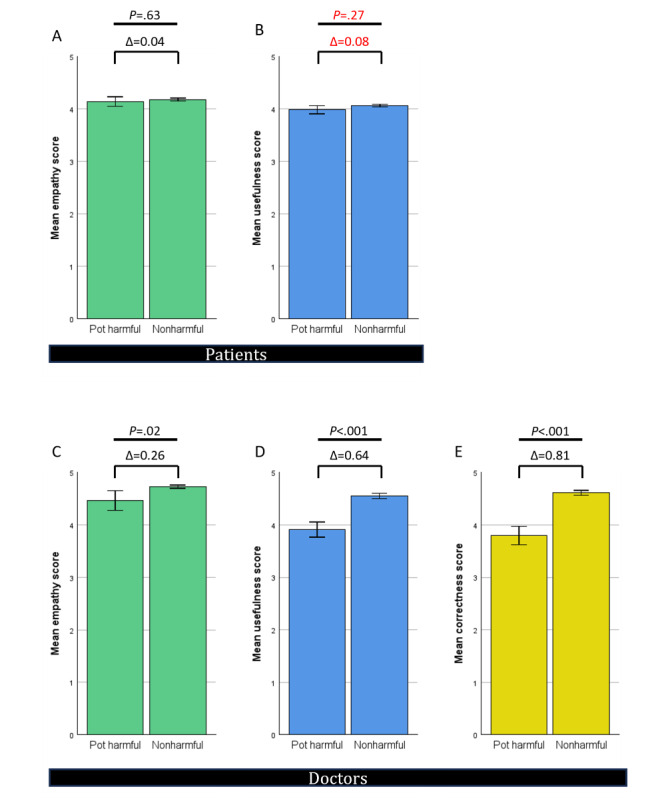
Results: In total, 200 sets of questions were submitted by 64 patients (mean 45.7, SD 15.9 years; 29/64, 45.3% male), resulting in 2000 evaluated answers of ChatGPT and the EP each. ChatGPT scored higher in terms of empathy (4.18 vs 2.7; P<.001) and usefulness (4.04 vs 2.98; P<.001). Subanalysis revealed a small bias in terms of levels of empathy given by women in comparison with men (4.46 vs 4.14; P=.049). Ratings of ChatGPT were high regardless of the participant's age. The same highly significant results were observed in the evaluation of the respective specialist physicians. ChatGPT outperformed significantly in correctness (4.51 vs 3.55; P<.001). Specialists rated the usefulness (3.93 vs 4.59) and correctness (4.62 vs 3.84) significantly lower in potentially harmful responses from ChatGPT (P<.001). This was not the case among patients.
Conclusions: The results indicate that ChatGPT is capable of supporting patients in health-related queries better than physicians, at least in terms of written advice through a web-based platform. In this study, ChatGPT's responses had a lower percentage of potentially harmful advice than the web-based EP. However, it is crucial to note that this finding is based on a specific study design and may not generalize to all health care settings. Alarmingly, patients are not able to independently recognize these potential dangers.
Keywords: AI; ChatGPT; LLM; artificial intelligence; chatbot; chatbots; empathy; large language models; patient education; patient information; patient perceptions.
©Jonas Armbruster, Florian Bussmann, Catharina Rothhaas, Nadine Titze, Paul Alfred Grützner, Holger Freischmidt. Originally published in the Journal of Medical Internet Research (https://www.jmir.org), 01.10.2024.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
References
-
- De Angelis L, Baglivo F, Arzilli G, Privitera GP, Ferragina P, Tozzi AE, Rizzo C. ChatGPT and the rise of large language models: the new AI-driven infodemic threat in public health. Front Public Health. 2023;11:1166120. doi: 10.3389/fpubh.2023.1166120. https://europepmc.org/abstract/MED/37181697 - DOI - PMC - PubMed
-
- Christiano PF, Leike J, Brown TB, Martic M, Legg S, Amodei D. Deep reinforcement learning from human preferences. arXiv. Preprint posted online. 2013:1–17. doi: 10.5260/chara.21.2.8. - DOI
-
- Ouyang L, Wu J, Jiang X, Almeida D, Wainwright CL, Mishkin P, Zhang C, Agarwal S, Slama K, Ray A, Schulman J, Hilton J, Kelton F, Miller L, Simens M, Askell A, Welinder P, Christiano P, Leike J, Lowe R. Training language models tof ollow instructions with human feedback. arXiv. Published online. 2022 Mar 4;:1–68.
-
- Min B, Ross H, Sulem E, Veyseh APB, Nguyen TH, Sainz O, Agirre E, Heintz I, Roth D. Recent advances in natural language processing via large pre-trained language models: a survey. ACM Comput. Surv. 2023 Sep 14;56(2):1–40. doi: 10.1145/3605943. - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
Research Materials
