

Assessing generalizability of an AI-based visual test for cervical cancer screening
- PMID: 39356713
- PMCID: PMC11446437
- DOI: 10.1371/journal.pdig.0000364
Assessing generalizability of an AI-based visual test for cervical cancer screening
Abstract
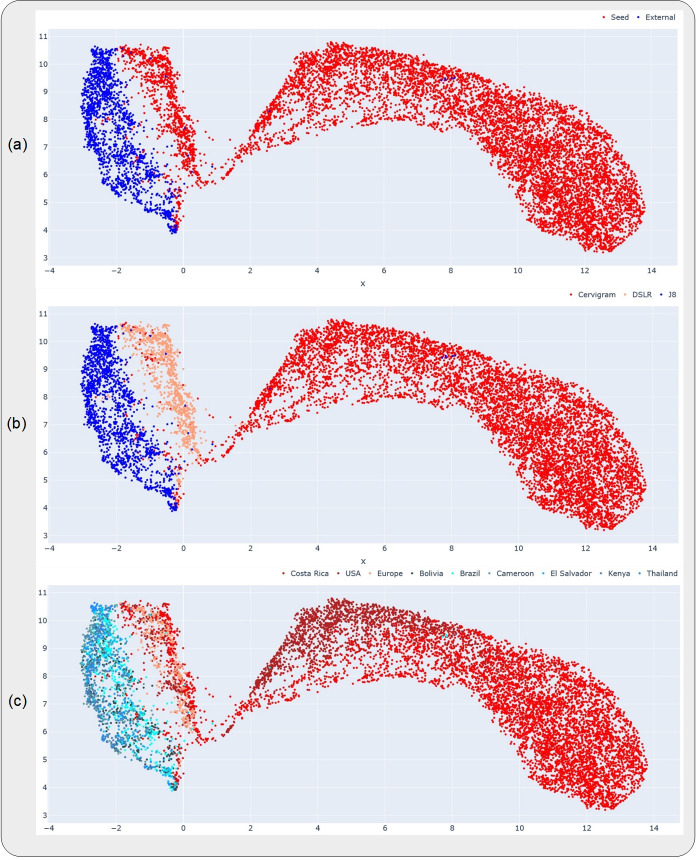
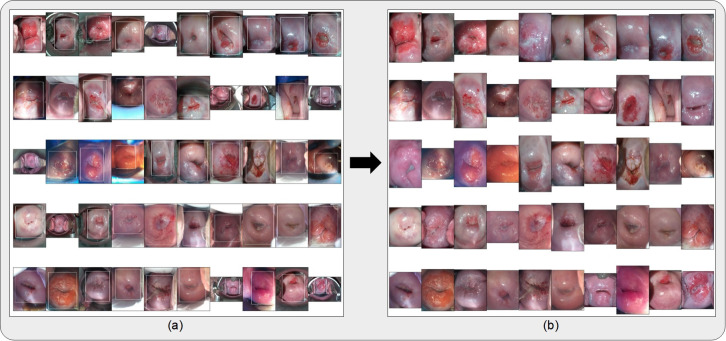
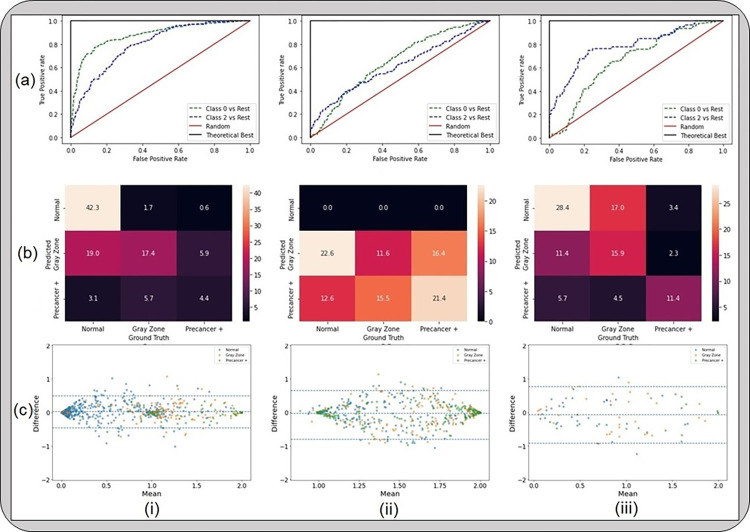
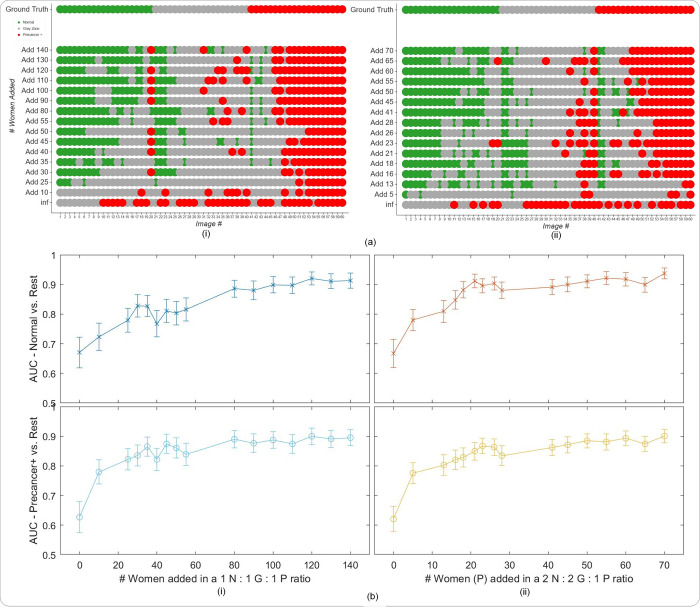
A number of challenges hinder artificial intelligence (AI) models from effective clinical translation. Foremost among these challenges is the lack of generalizability, which is defined as the ability of a model to perform well on datasets that have different characteristics from the training data. We recently investigated the development of an AI pipeline on digital images of the cervix, utilizing a multi-heterogeneous dataset of 9,462 women (17,013 images) and a multi-stage model selection and optimization approach, to generate a diagnostic classifier able to classify images of the cervix into "normal", "indeterminate" and "precancer/cancer" (denoted as "precancer+") categories. In this work, we investigate the performance of this multiclass classifier on external data not utilized in training and internal validation, to assess the generalizability of the classifier when moving to new settings. We assessed both the classification performance and repeatability of our classifier model across the two axes of heterogeneity present in our dataset: image capture device and geography, utilizing both out-of-the-box inference and retraining with external data. Our results demonstrate that device-level heterogeneity affects our model performance more than geography-level heterogeneity. Classification performance of our model is strong on images from a new geography without retraining, while incremental retraining with inclusion of images from a new device progressively improves classification performance on that device up to a point of saturation. Repeatability of our model is relatively unaffected by data heterogeneity and remains strong throughout. Our work supports the need for optimized retraining approaches that address data heterogeneity (e.g., when moving to a new device) to facilitate effective use of AI models in new settings.
Copyright: This is an open access article, free of all copyright, and may be freely reproduced, distributed, transmitted, modified, built upon, or otherwise used by anyone for any lawful purpose. The work is made available under the Creative Commons CC0 public domain dedication.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Piccialli F, Somma V Di, Giampaolo F, Cuomo S, Fortino G. A survey on deep learning in medicine: Why, how and when? Inf Fusion. 2021;66: 111–137. doi: 10.1016/J.INFFUS.2020.09.006 - DOI
Grants and funding
LinkOut - more resources
Full Text Sources