

Demonstration of 4-quadrant analog in-memory matrix multiplication in a single modulation
- PMID: 39372606
- PMCID: PMC11449787
- DOI: 10.1038/s44335-024-00010-4
Demonstration of 4-quadrant analog in-memory matrix multiplication in a single modulation
Abstract
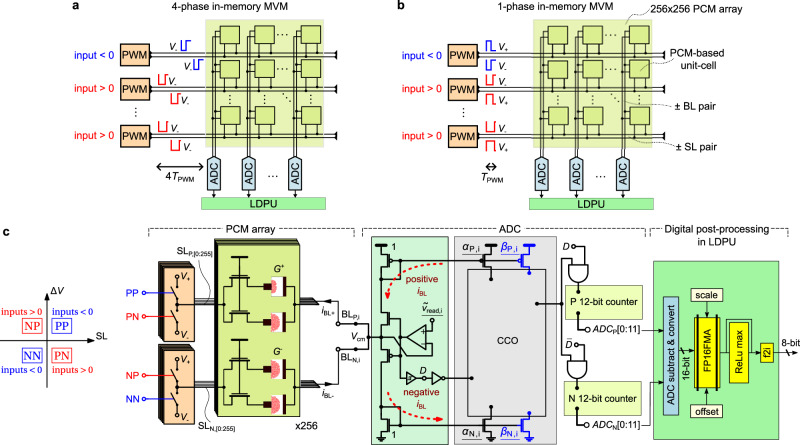
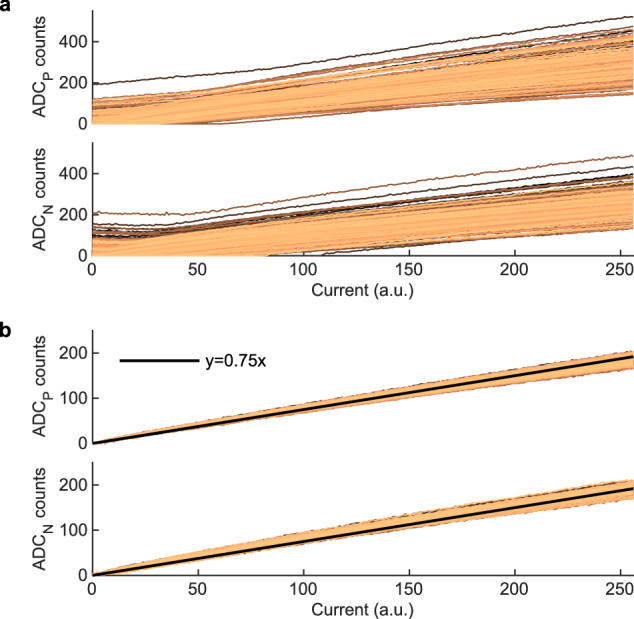
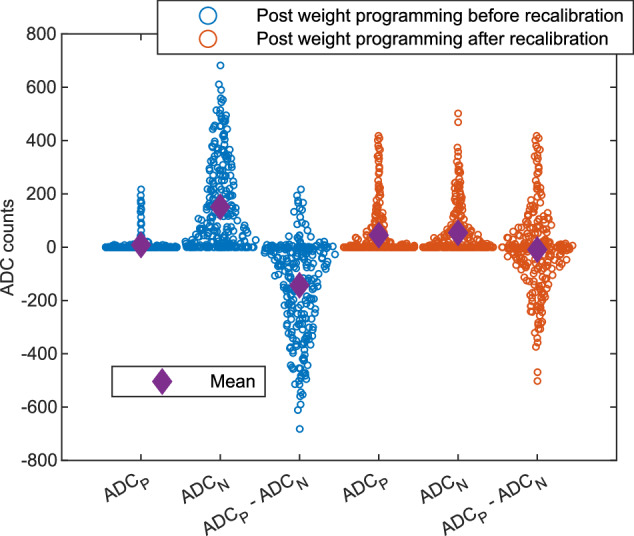
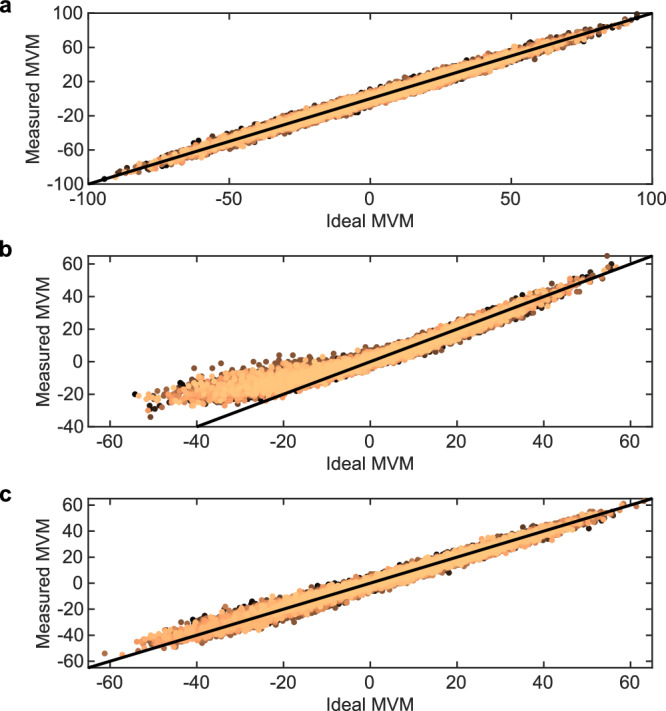
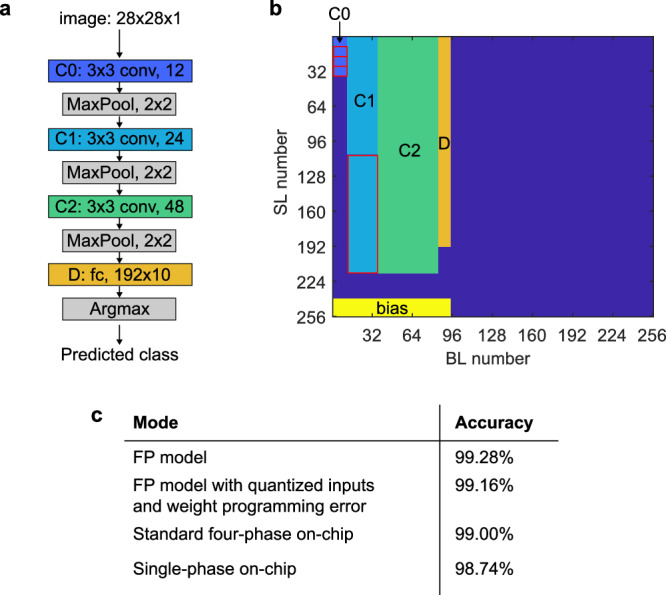
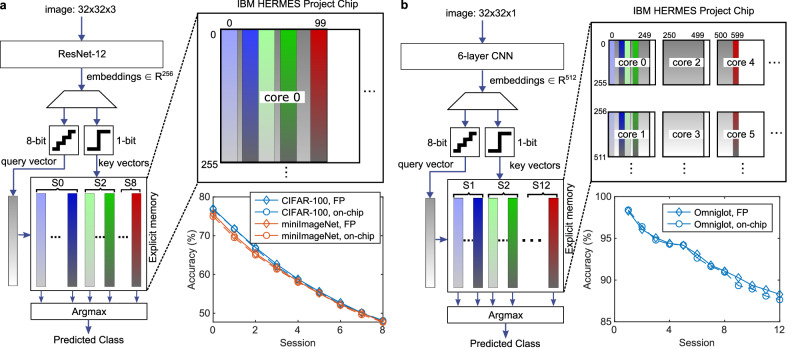
Analog in-memory computing (AIMC) leverages the inherent physical characteristics of resistive memory devices to execute computational operations, notably matrix-vector multiplications (MVMs). However, executing MVMs using a single-phase reading scheme to reduce latency necessitates the simultaneous application of both positive and negative voltages across resistive memory devices. This degrades the accuracy of the computation due to the dependence of the device conductance on the voltage polarity. Here, we demonstrate the realization of a 4-quadrant MVM in a single modulation by developing analog and digital calibration procedures to mitigate the conductance polarity dependence, fully implemented on a multi-core AIMC chip based on phase-change memory. With this approach, we experimentally demonstrate accurate neural network inference and similarity search tasks using one or multiple cores of the chip, at 4 times higher MVM throughput and energy efficiency than the conventional four-phase reading scheme.
Keywords: Electrical and electronic engineering; Electronic devices.
© The Author(s) 2024.
Conflict of interest statement
Competing interestsThe authors declare no competing interests.
Figures

References
-
- Huang, Y. et al. Memristor-based hardware accelerators for artificial intelligence. Nat. Rev. Electr. Eng.1, 286–299 (2024). - DOI
-
- Le Gallo, M. et al. A 64-core mixed-signal in-memory compute chip based on phase-change memory for deep neural network inference. Nat. Electron.6, 680–1693 (2023). - DOI
LinkOut - more resources
Full Text Sources