

Deep learning as Ricci flow
- PMID: 39379488
- PMCID: PMC11461635
- DOI: 10.1038/s41598-024-74045-9
Deep learning as Ricci flow
Abstract
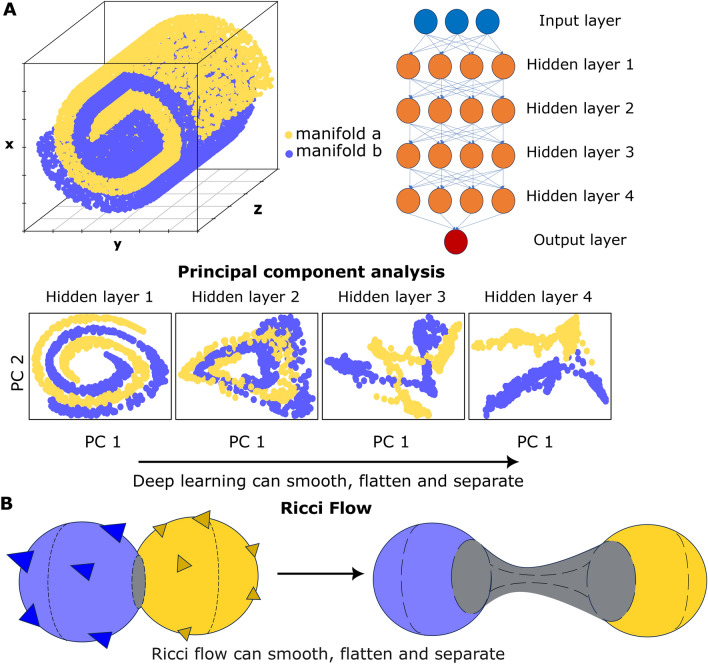
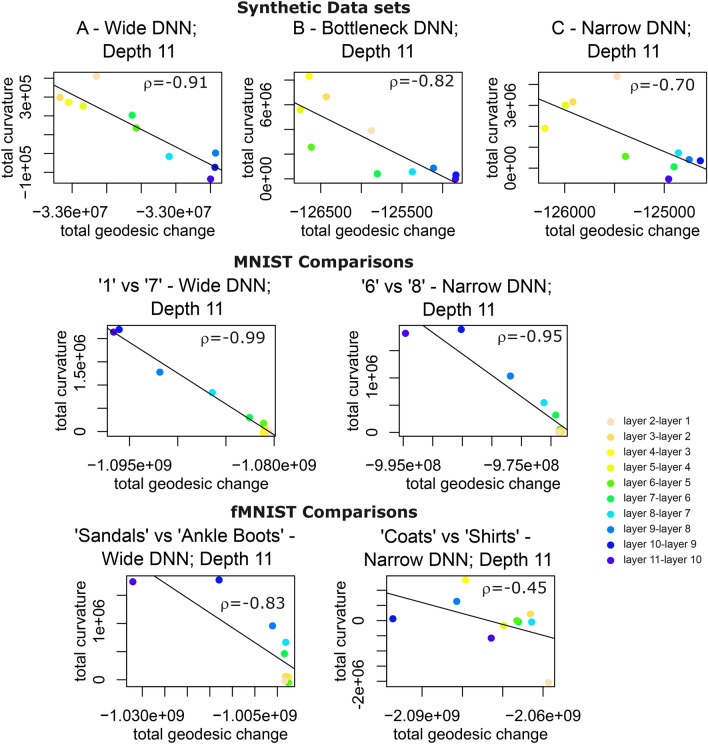
Deep neural networks (DNNs) are powerful tools for approximating the distribution of complex data. It is known that data passing through a trained DNN classifier undergoes a series of geometric and topological simplifications. While some progress has been made toward understanding these transformations in neural networks with smooth activation functions, an understanding in the more general setting of non-smooth activation functions, such as the rectified linear unit (ReLU), which tend to perform better, is required. Here we propose that the geometric transformations performed by DNNs during classification tasks have parallels to those expected under Hamilton's Ricci flow-a tool from differential geometry that evolves a manifold by smoothing its curvature, in order to identify its topology. To illustrate this idea, we present a computational framework to quantify the geometric changes that occur as data passes through successive layers of a DNN, and use this framework to motivate a notion of 'global Ricci network flow' that can be used to assess a DNN's ability to disentangle complex data geometries to solve classification problems. By training more than 1500 DNN classifiers of different widths and depths on synthetic and real-world data, we show that the strength of global Ricci network flow-like behaviour correlates with accuracy for well-trained DNNs, independently of depth, width and data set. Our findings motivate the use of tools from differential and discrete geometry to the problem of explainability in deep learning.
Keywords: Complex network; Deep learning; Differential geometry; Ricci flow.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures


References
-
- Kotsiantis, S. B. et al. Supervised machine learning: A review of classification techniques. Emerg. Artif. Intell. Appl. Comput. Eng.160 (1), 3–24 (2007).
-
- LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature521 (7553), 436–444 (2015). - PubMed
-
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control Signals Syst.2 (4), 303–314 (1989).
-
- Hornik, K., Stinchcombe, M. & White, H. Multilayer feedforward networks are universal approximators. Neural Netw.2 (5), 359–366 (1989).
-
- Montufar, G. F., Pascanu, R., Cho, K. & Bengio, Y. On the number of linear regions of deep neural networks. Adv. Neural Inf. Process. Syst.27 (2014).
LinkOut - more resources
Full Text Sources
