

This is a preprint.
Human-specific gene expansions contribute to brain evolution
- PMID: 39386494
- PMCID: PMC11463660
- DOI: 10.1101/2024.09.26.615256
Human-specific gene expansions contribute to brain evolution
Update in
-
Human-specific gene expansions contribute to brain evolution.Cell. 2025 Sep 18;188(19):5363-5383.e22. doi: 10.1016/j.cell.2025.06.037. Epub 2025 Jul 21. Cell. 2025. PMID: 40695280
Abstract
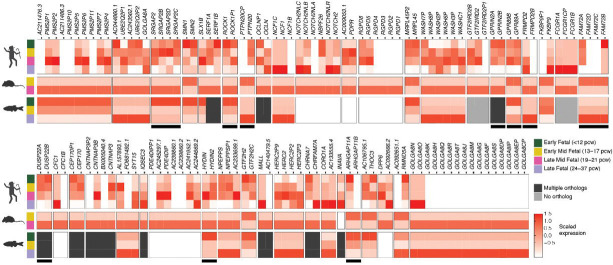
Duplicated genes expanded in the human lineage likely contributed to brain evolution, yet challenges exist in their discovery due to sequence-assembly errors. We used a complete telomere-to-telomere genome sequence to identify 213 human-specific gene families. From these, 362 paralogs were found in all modern human genomes tested and brain transcriptomes, making them top candidates contributing to human-universal brain features. Choosing a subset of paralogs, long-read DNA sequencing of hundreds of modern humans revealed previously hidden signatures of selection, including for T-cell marker CD8B. To understand roles in brain development, we generated zebrafish CRISPR "knockout" models of nine orthologs and introduced mRNA-encoding paralogs, effectively "humanizing" larvae. Our findings implicate two genes in possibly contributing to hallmark features of the human brain: GPR89B in dosage-mediated brain expansion and FRMPD2B in altered synapse signaling. Our holistic approach provides insights and a comprehensive resource for studying gene expansion drivers of human brain evolution.
Keywords: brain; copy-number variation; gene duplications; gene expression; human evolution; neurodevelopment; segmental duplications; sequencing; zebrafish.
Conflict of interest statement
Declaration of Interests Authors have nothing to disclose.
Figures





References
-
- Carroll S.B. (2003). Genetics and the making of Homo sapiens. Nature 422, 849–857. - PubMed
-
- Varki A., and Altheide T.K. (2005). Comparing the human and chimpanzee genomes: Searching for needles in a haystack. Preprint, 10.1101/gr.3737405 https://doi.org/10.1101/gr.3737405. - DOI - PubMed
-
- Pääbo S. (2014). The Human Condition—A Molecular Approach. Preprint, 10.1016/j.cell.2013.12.036 https://doi.org/10.1016/j.cell.2013.12.036. - DOI - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials