

BaseNet: A transformer-based toolkit for nanopore sequencing signal decoding
- PMID: 39391372
- PMCID: PMC11465205
- DOI: 10.1016/j.csbj.2024.09.016
BaseNet: A transformer-based toolkit for nanopore sequencing signal decoding
Abstract
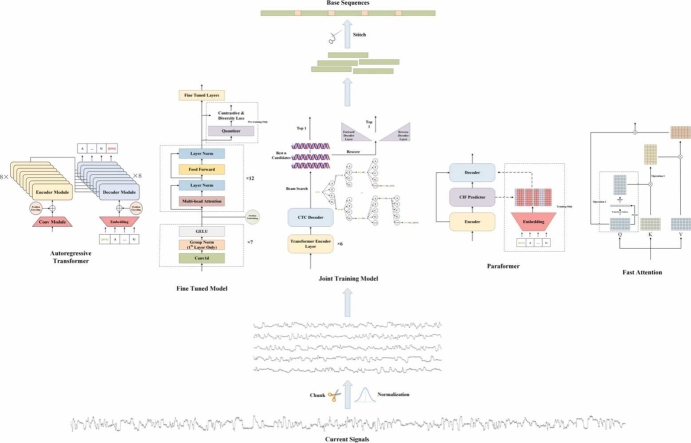
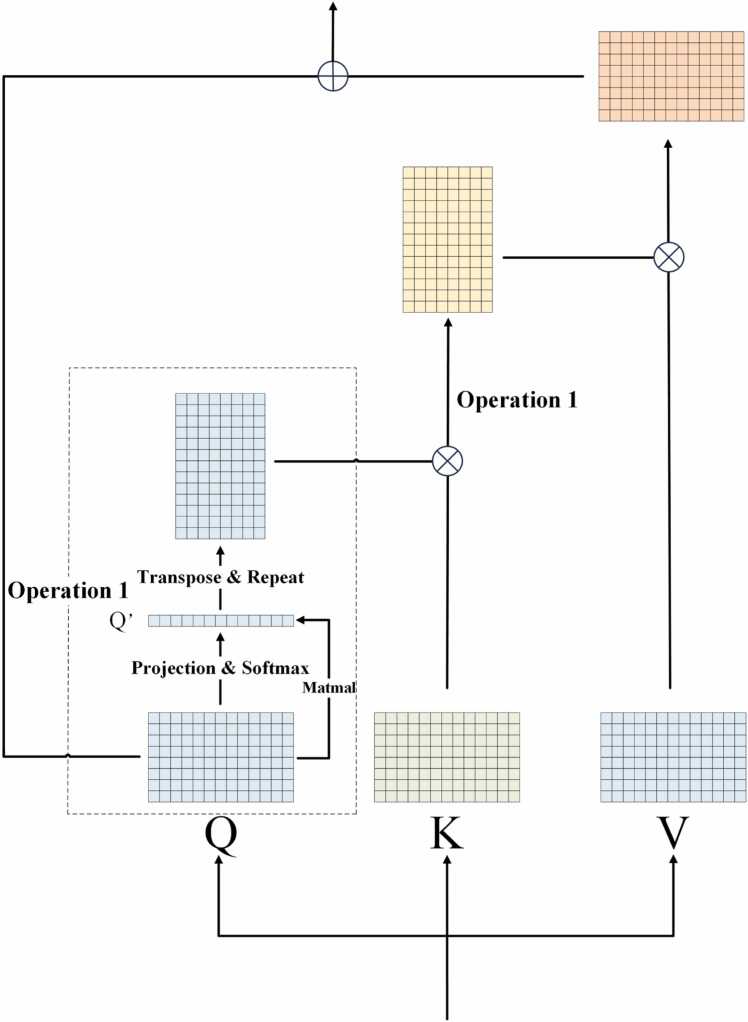
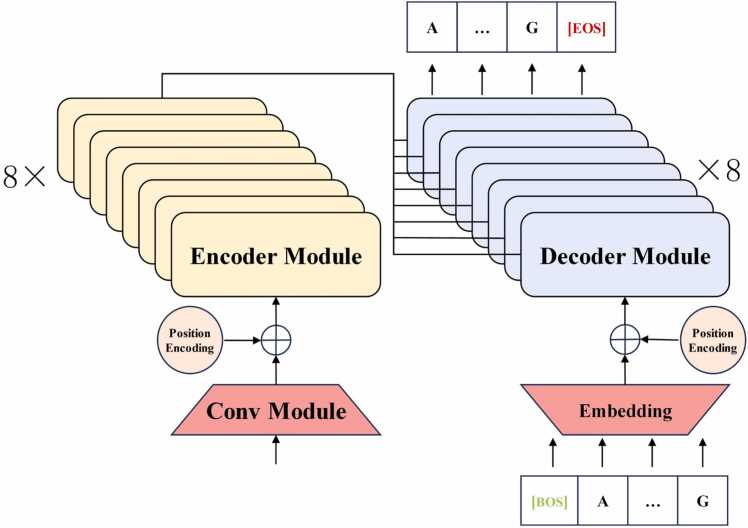
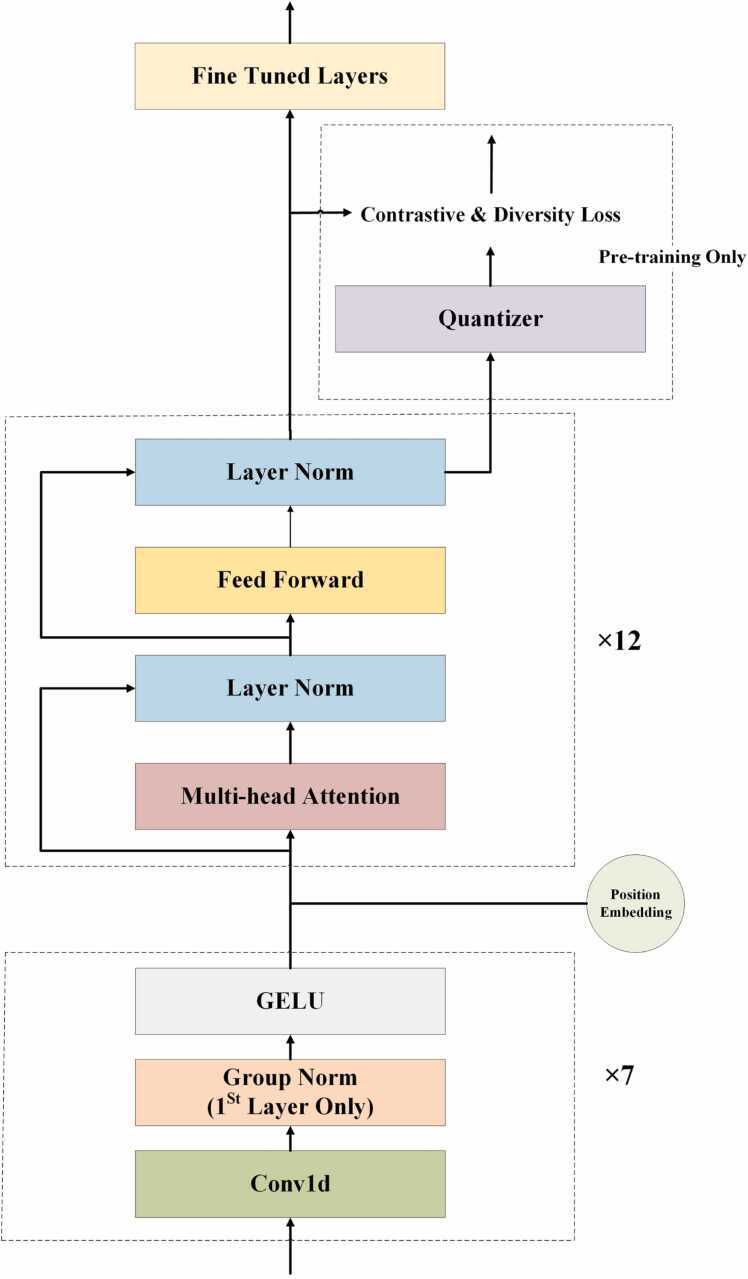
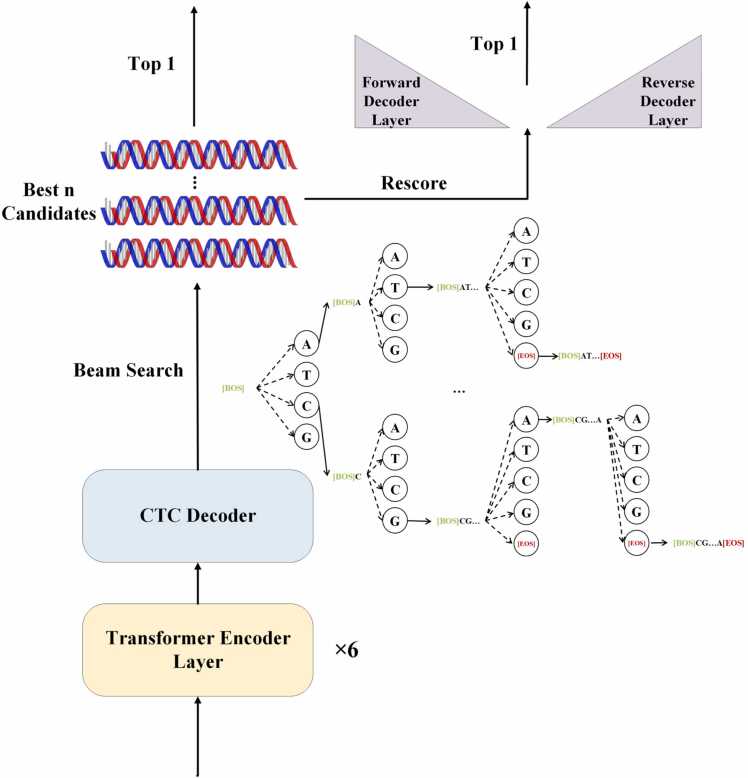
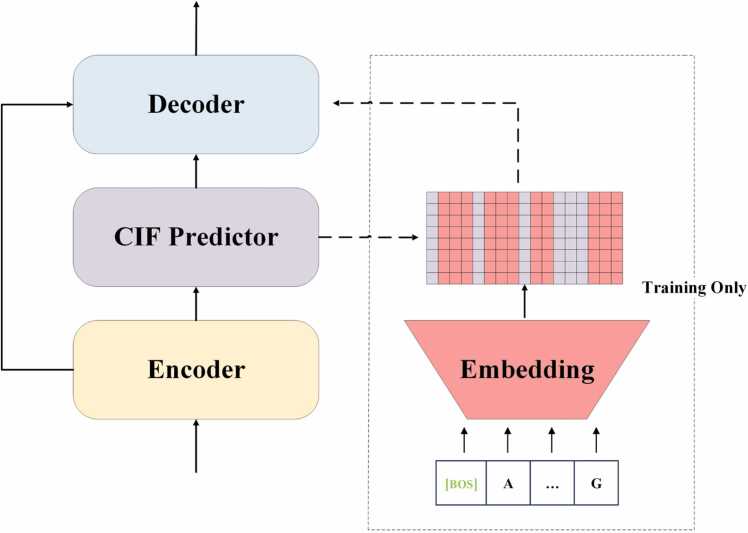
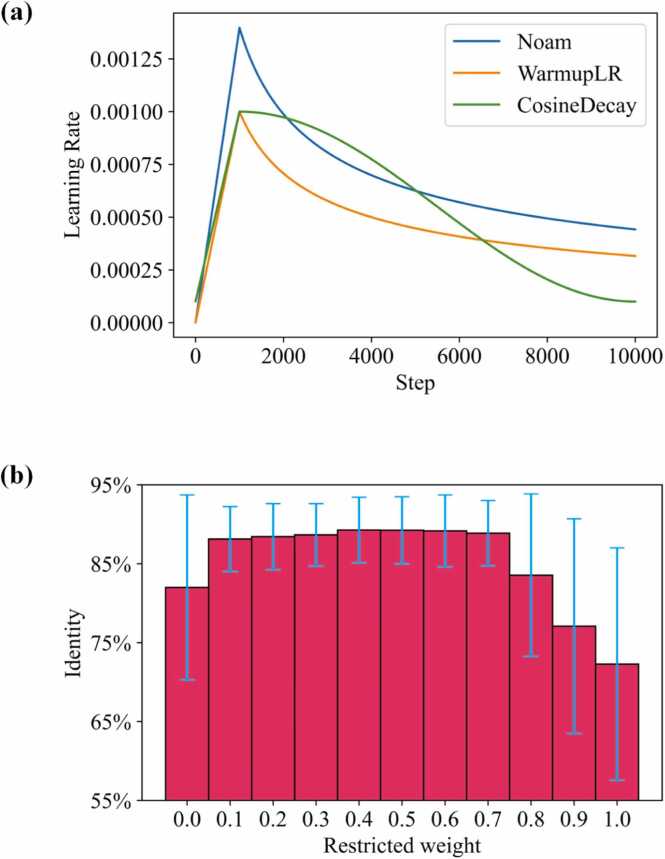
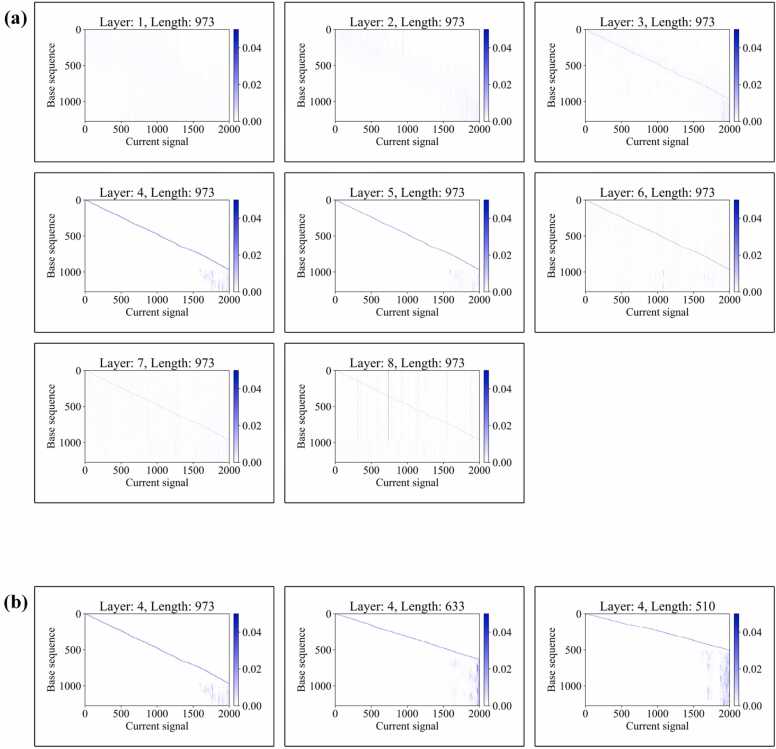
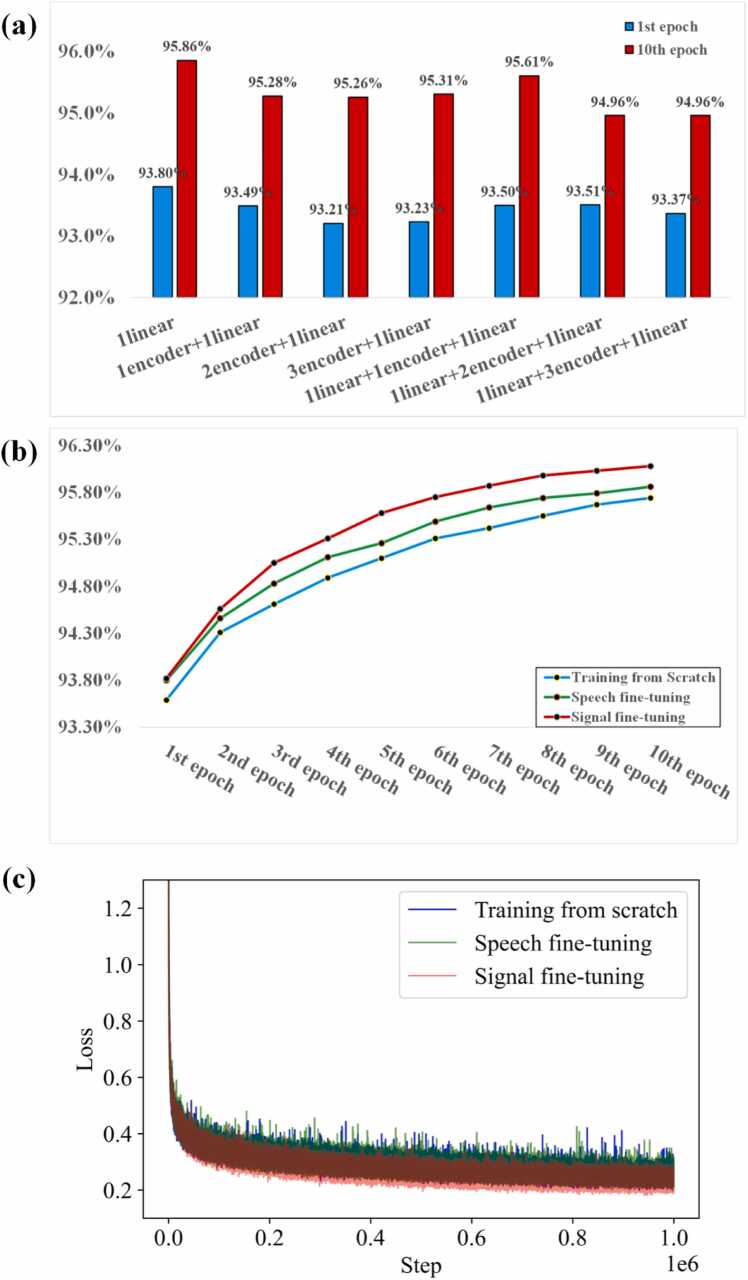
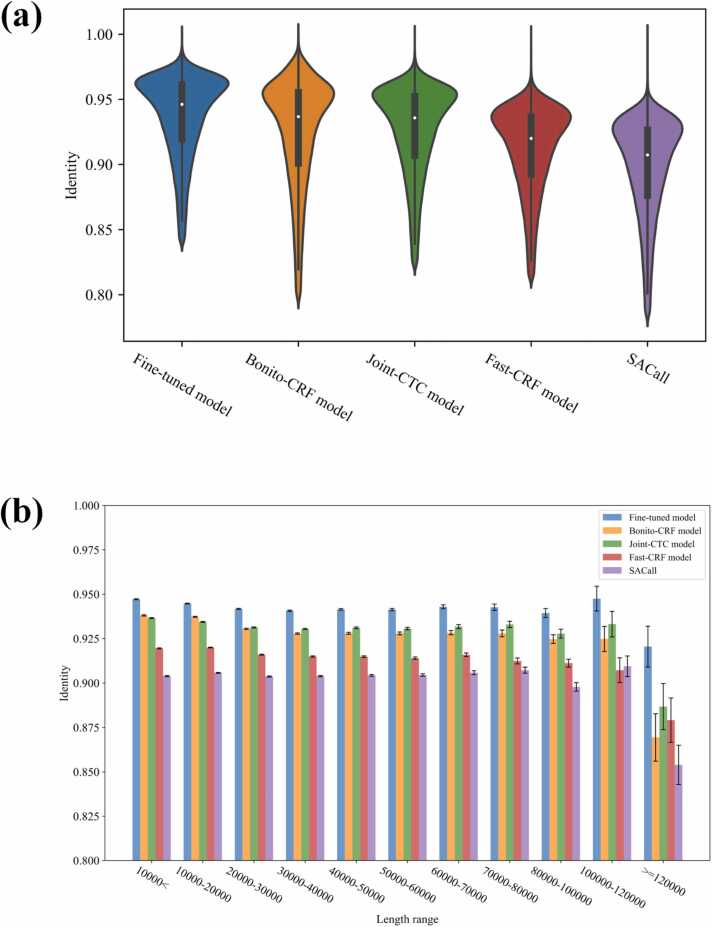
Nanopore sequencing provides a rapid, convenient and high-throughput solution for nucleic acid sequencing. Accurate basecalling in nanopore sequencing is crucial for downstream analysis. Traditional approaches such as Hidden Markov Models (HMM), Recurrent Neural Networks (RNN), and Convolutional Neural Networks (CNN) have improved basecalling accuracy but there is a continuous need for higher accuracy and reliability. In this study, we introduce BaseNet (https://github.com/liqingwen98/BaseNet), an open-source toolkit that utilizes transformer models for advanced signal decoding in nanopore sequencing. BaseNet incorporates both autoregressive and non-autoregressive transformer-based decoding mechanisms, offering state-of-the-art algorithms freely accessible for future improvement. Our research indicates that cross-attention weights effectively map the relationship between current signals and base sequences, joint loss training through adding a pair of forward and reverse decoder facilitate model converge, and large-scale pre-trained models achieve superior decoding accuracy. This study helps to advance the field of nanopore sequencing signal decoding, contributes to technological advancements, and provides novel concepts and tools for researchers and practitioners.
Keywords: Basecall; Machine learning algorithm; Nanopore sequencing; Transformer.
© 2024 The Authors.
Conflict of interest statement
Daqian Wang and Jizhong Lou are co-founders and shareholders of Beijing Polyseq Biotech Co. Ltd. Beijing Polyseq Biotech Co. Ltd. and Institute of Biophysics, Chinese Academy of Sciences have filed a patent using materials described in this article.
Figures
References
-
- Davenport C.F., Scheithauer T., Dunst A., Bahr F.S., Dorda M., Wiehlmann L., et al. Genome-Wide Methylation Mapping Using Nanopore Sequencing Technology Identifies Novel Tumor Suppressor Genes in Hepatocellular Carcinoma. Int J Mol Sci. 2021;22(8):3937. https://www.mdpi.com/1422-0067/22/8/3937 - PMC - PubMed
LinkOut - more resources
Full Text Sources
Other Literature Sources