

Expanding drug targets for 112 chronic diseases using a machine learning-assisted genetic priority score
- PMID: 39406732
- PMCID: PMC11480483
- DOI: 10.1038/s41467-024-53333-y
Expanding drug targets for 112 chronic diseases using a machine learning-assisted genetic priority score
Abstract
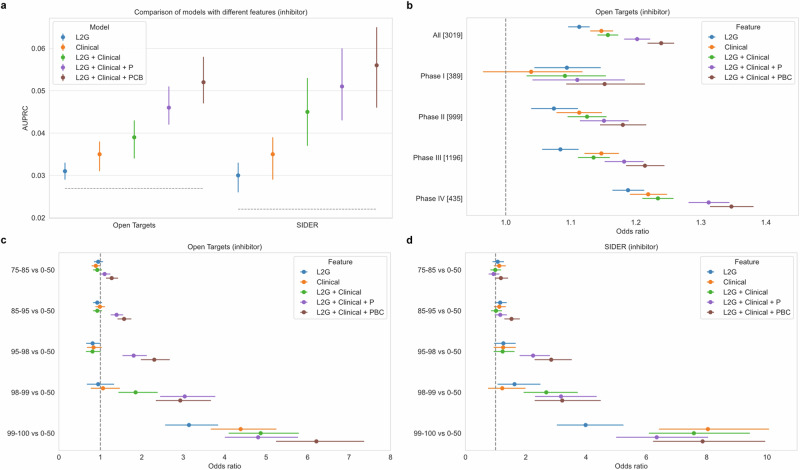
Identifying genetic drivers of chronic diseases is necessary for drug discovery. Here, we develop a machine learning-assisted genetic priority score, which we call ML-GPS, that incorporates genetic associations with predicted disease phenotypes to enhance target discovery. First, we construct gradient boosting models to predict 112 chronic disease phecodes in the UK Biobank and analyze associations of predicted and observed phenotypes with common, rare, and ultra-rare variants to model the allelic series. We integrate these associations with existing evidence using gradient boosting with continuous feature encoding to construct ML-GPS, training it to predict drug indications in Open Targets and externally testing it in SIDER. We then generate ML-GPS predictions for 2,362,636 gene-phecode pairs. We find that the use of predicted phenotypes, which identify substantially more genetic associations than observed phenotypes across the allele frequency spectrum, significantly improves the performance of ML-GPS. ML-GPS increases coverage of drug targets, with the top 1% of all scores providing support for 15,077 gene-phecode pairs that previously had no support. ML-GPS can also identify well-known target-disease relationships, promising targets without indicated drugs, and targets for several drugs in clinical trials, including LRRK2 inhibitors for Parkinson's disease and olpasiran for cardiovascular disease.
© 2024. The Author(s).
Conflict of interest statement
RD reported being a scientific co-founder, consultant and equity holder for Pensieve Health (pending) and being a consultant for Variant Bio, all not related to this work. DNC and MM acknowledge receipt of funding from Qiagen Ltd through a License agreement with Cardiff University, which is relevant to the use of HGMD Professional in this work. All other authors have no competing interests.
Figures






References
Publication types
MeSH terms
Grants and funding
- KL2 TR004421/TR/NCATS NIH HHS/United States
- R01-CA277794/U.S. Department of Health & Human Services | NIH | National Cancer Institute (NCI)
- R35 GM124836/GM/NIGMS NIH HHS/United States
- T32-GM007280/U.S. Department of Health & Human Services | NIH | National Institute of General Medical Sciences (NIGMS)
- 21CVD01/Fondation Leducq
- 2209-05535/Leona M. and Harry B. Helmsley Charitable Trust (Helmsley Charitable Trust)
- R01 HD107528/HD/NICHD NIH HHS/United States
- R01-HD107528/U.S. Department of Health & Human Services | NIH | Eunice Kennedy Shriver National Institute of Child Health and Human Development (NICHD)
- R01 CA277794/CA/NCI NIH HHS/United States
- T32 GM007280/GM/NIGMS NIH HHS/United States
- R35-GM124836/U.S. Department of Health & Human Services | NIH | National Institute of General Medical Sciences (NIGMS)
LinkOut - more resources
Full Text Sources
Miscellaneous
