

This is a preprint.
Perceptual Expertise and Attention: An Exploration using Deep Neural Networks
- PMID: 39464001
- PMCID: PMC11507720
- DOI: 10.1101/2024.10.15.617743
Perceptual Expertise and Attention: An Exploration using Deep Neural Networks
Abstract
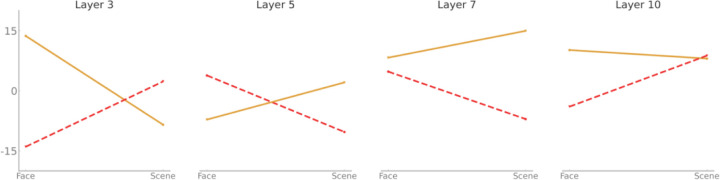
Perceptual expertise and attention are two important factors that enable superior object recognition and task performance. While expertise enhances knowledge and provides a holistic understanding of the environment, attention allows us to selectively focus on task-related information and suppress distraction. It has been suggested that attention operates differently in experts and in novices, but much remains unknown. This study investigates the relationship between perceptual expertise and attention using convolutional neural networks (CNNs), which are shown to be good models of primate visual pathways. Two CNN models were trained to become experts in either face or scene recognition, and the effect of attention on performance was evaluated in tasks involving complex stimuli, such as superimposed images containing superimposed faces and scenes. The goal was to explore how feature-based attention (FBA) influences recognition within and outside the domain of expertise of the models. We found that each model performed better in its area of expertise-and that FBA further enhanced task performance, but only within the domain of expertise, increasing performance by up to 35% in scene recognition, and 15% in face recognition. However, attention had reduced or negative effects when applied outside the models' expertise domain. Neural unit-level analysis revealed that expertise led to stronger tuning towards category-specific features and sharper tuning curves, as reflected in greater representational dissimilarity between targets and distractors, which, in line with the biased competition model of attention, leads to enhanced performance by reducing competition. These findings highlight the critical role of neural tuning at single as well as network level neural in distinguishing the effects of attention in experts and in novices and demonstrate that CNNs can be used fruitfully as computational models for addressing neuroscience questions not practical with the empirical methods.
Figures





References
-
- Xu K, Ba J, Kiros R, Cho K, Courville A, Salakhudinov R, et al. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In: Francis B, David B, editors. Proceedings of the 32nd International Conference on Machine Learning; Proceedings of Machine Learning Research: PMLR; 2015. p. 2048–57.
-
- Cao C, Liu X, Yang Y, Yu Y, Wang J, Wang Z, et al. Look and Think Twice: Capturing Top-Down Visual Attention with Feedback Convolutional Neural Networks. 2015 IEEE International Conference on Computer Vision (ICCV)2015. p. 2956–64.
-
- Yang X, Yan J, Wang W, Li S, Hu B, Lin J. Brain-inspired models for visual object recognition: an overview. Artificial Intelligence Review. 2022;55(7):5263–311.
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources