

A large-scale examination of inductive biases shaping high-level visual representation in brains and machines
- PMID: 39477923
- PMCID: PMC11526138
- DOI: 10.1038/s41467-024-53147-y
A large-scale examination of inductive biases shaping high-level visual representation in brains and machines
Abstract
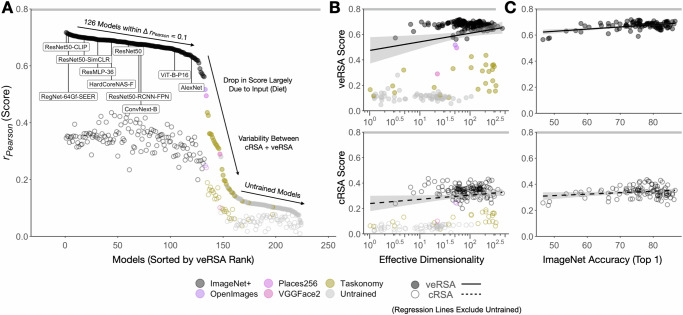
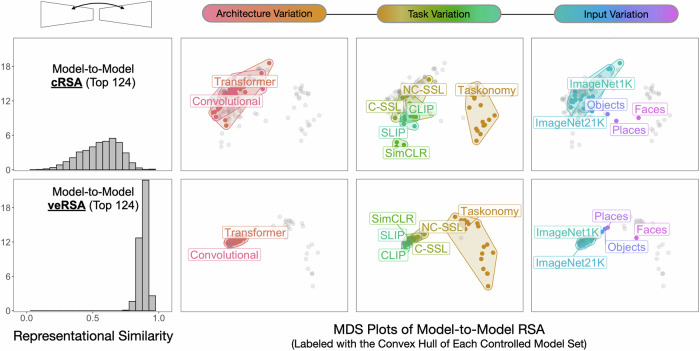
The rapid release of high-performing computer vision models offers new potential to study the impact of different inductive biases on the emergent brain alignment of learned representations. Here, we perform controlled comparisons among a curated set of 224 diverse models to test the impact of specific model properties on visual brain predictivity - a process requiring over 1.8 billion regressions and 50.3 thousand representational similarity analyses. We find that models with qualitatively different architectures (e.g. CNNs versus Transformers) and task objectives (e.g. purely visual contrastive learning versus vision- language alignment) achieve near equivalent brain predictivity, when other factors are held constant. Instead, variation across visual training diets yields the largest, most consistent effect on brain predictivity. Many models achieve similarly high brain predictivity, despite clear variation in their underlying representations - suggesting that standard methods used to link models to brains may be too flexible. Broadly, these findings challenge common assumptions about the factors underlying emergent brain alignment, and outline how we can leverage controlled model comparison to probe the common computational principles underlying biological and artificial visual systems.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
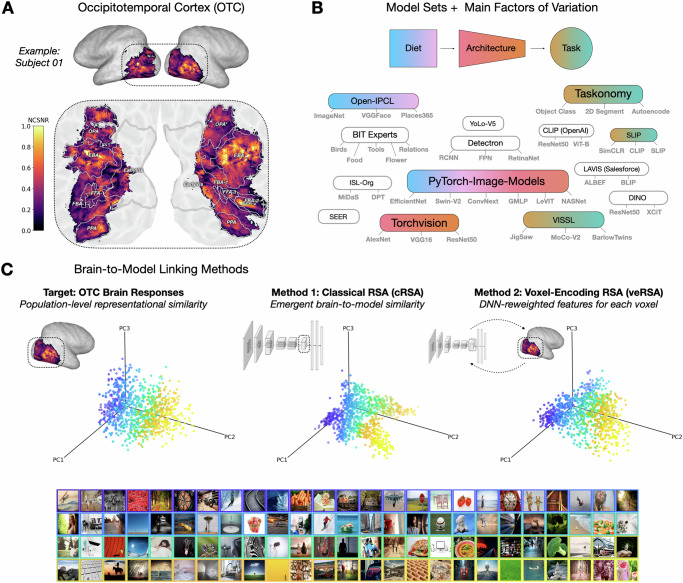
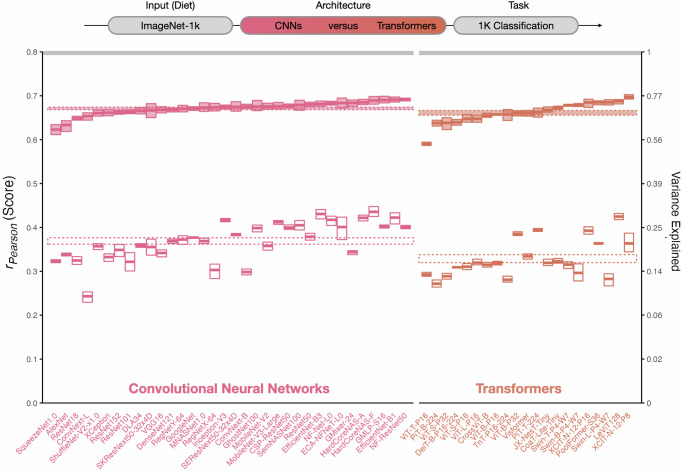
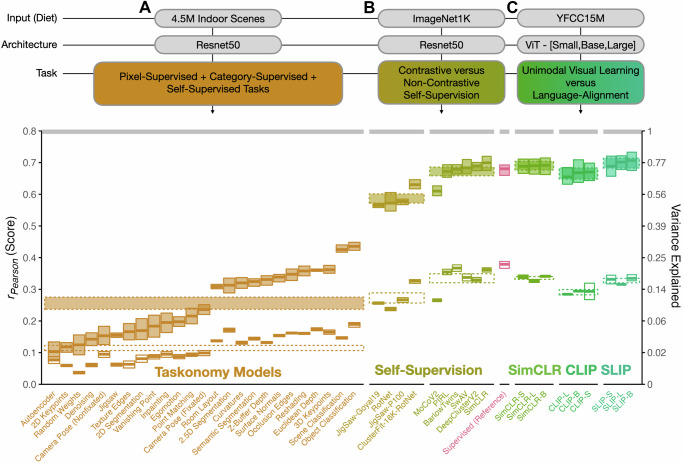
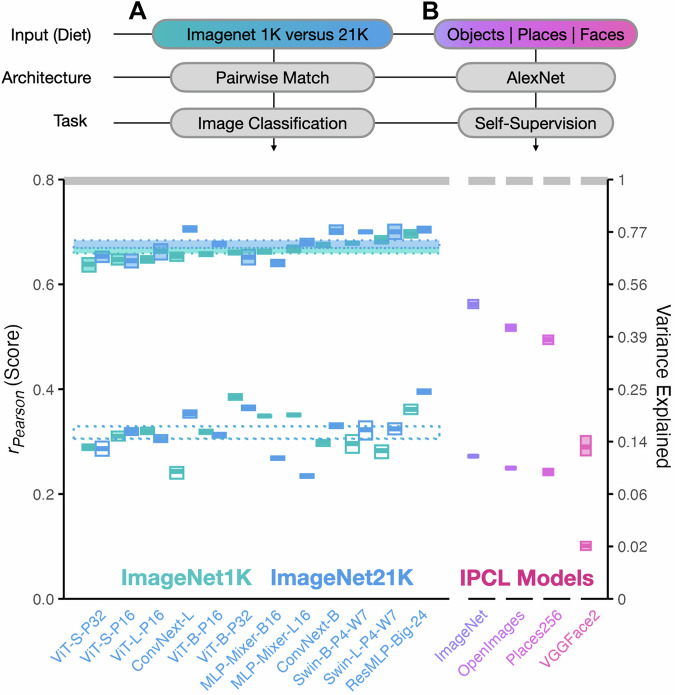
References
-
- Olshausen, B. A., Field, D. J. et al. Sparse coding of natural images produces localized, oriented, bandpass receptive fields. Submitted to Nature. Available electronically as ftp://redwood. psych. cornell. edu/pub/papers/sparse-coding. ps, 1995. Citeseer.
-
- Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, 1097–1105 (2012).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
