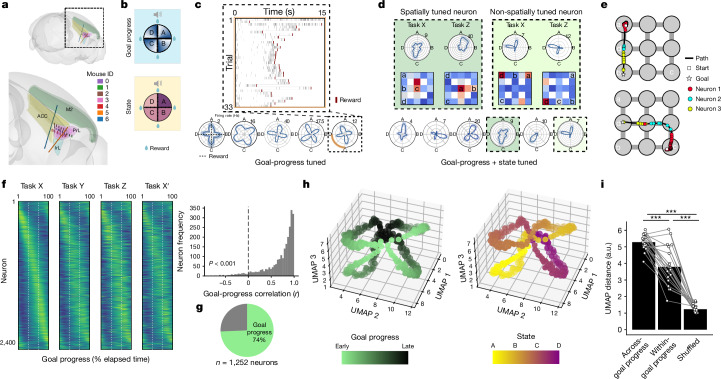
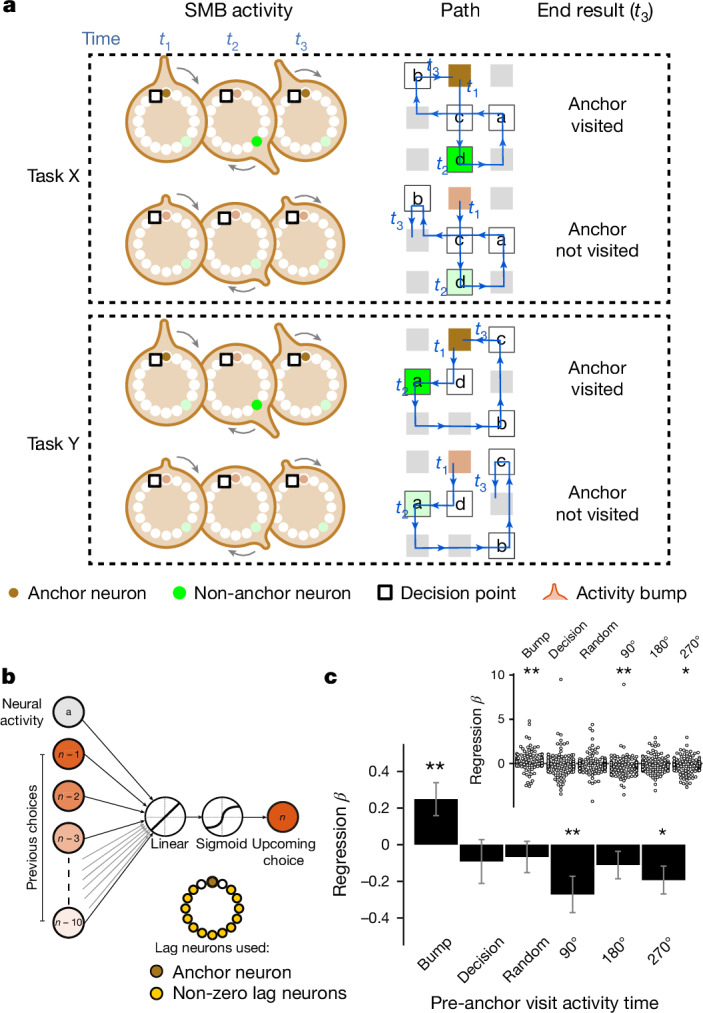
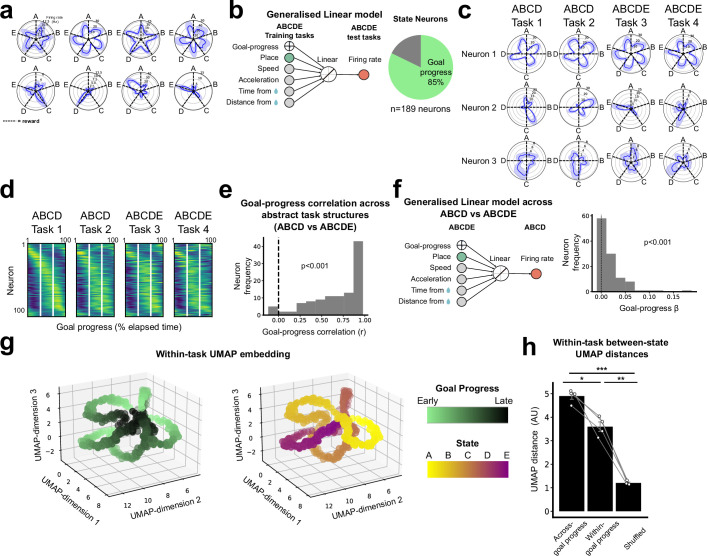
Extended Data Fig. 9. The Structured memory buffers model allows precise and generalisable prediction of future behaviour from neuronal activity.
a) Schematic showing distal prediction of animal’s choices from memory buffers as a function of previous trial choices. By harnessing variability in the coupling between anchor visits and bump initiation, we can test whether SMB activity can predict future choices while controlling for previous choices. In this example we show an SMB with an anchor at location 2 (top middle location shaded in brown) at intermediate goal progress (i.e. half way between goals). Each row shows a different scenario across two consecutive trials (trial N-1 and trial N) in the same task and the expected activity of neurons anchored to this location/goal-progress conjunction. Scenario 1 (0:0): the animal doesn’t visit the anchoring behavioural step in trial N-1 and hence the activity of neurons on this SMB is low. This results in the animal not visiting the anchoring behavioural step in trial N. Scenario 2 (0:1): the animal again doesn’t visit the anchoring behavioural step in trial N-1 but this time the activity of neurons on the SMB is high (e.g. due to noise or top down modulation). This results in the animal visiting the anchoring behavioural step in trial N. Scenario 3 (1:0): the animal visits the anchoring behavioural step in trial N-1 but the activity of neurons on the SMB for this anchor is low (e.g. due to noise or top down modulation). This results in the animal not visiting the anchoring behavioural step in trial N. Scenario 4 (1:1): the animal visits the anchoring behavioural step in trial N-1 and the activity of neurons on the SMB is high. This results in the animal visiting the anchoring behavioural step again in trial N. In effect the variability in the size of the bump in relation to the anchoring behavioural step visit allows us to decouple the SMBs’ activity from previous choices. This makes it possible to test whether SMB activity predicts future choices of the animal. Note that the time stamps shown on the SMB (t1,t2 and t3) are all in trial N. Reproduced/adapted with permission from Gil Costa. b) Prediction of behaviour. Normalised firing rates of neurons during their “bump time”: i.e. the lag at which they are active relative to the anchor. X-axis labels denote visits to a goal-progress/place anchor in the current (N) and upcoming trial (N + 1). For example a value of 0:1 means the anchoring behavioural step was not visited in trial N but visited in trial N + 1. Bump time activity is higher before visits to the neuron’s anchor in trial N + 1 whether the anchoring behavioural step was not visited in trial N (left) or when it was visited in trial N (right). Wilcoxon tests (two-sided): Anchoring behavioural step not visited in trial N: n = 131 tasks, statistic=2749, P = 3.0 × 10−4. Anchoring behavioural step visited in trial N: n = 123 tasks, statistic=2754, P = 0.008. In addition, an ANOVA on all data (N = 123 tasks) showed a trend towards a main effect of Past F = 3.51 P = 0.063, df1 = 1, df2 = 122, a main effect of Future F = 6.06 P = 0.015, df1 = 1, df2 = 122 and no Past x Future interaction F = 0.80 P = 0.373, df1 = 1, df2 = 122. Scatter plots showing individual points of the same data are shown next to each of the bar plots. c) Regression coefficients were positive for neuronal activity at the “bump time” and also for previous behavioural choices, gradually decreasing with trials in the past. T-tests (two-sided) against 0: “bump time”: N = 131 tasks, statistic=2.74, P = 0.007, df = 130;“n-1”: N = 131, statistic=7.39, P = 1.60 × 10−13, df = 130; “n-2” N = 131, statistic=8.03 P = 5.04 × 10−13, df = 130; “n-3” N = 131, statistic = 4.77 P = 4.80 × 10−6, df = 130; “n-4” N = 131, statistic=3.38, P = 9.45 × 10−4, df = 130; “n-5” N = 131, statistic=4.36, P = 2.58 × 10−5, df = 130;“n-6”: N = 131, statistic=1.76, P = 0.080, df = 130; “n-7” N = 131, statistic=2.83 P = 0.005, df = 130; “n-8” N = 131, statistic=2.19 P = 0.030, df = 130; “n-9” N = 131, statistic=2.42, P = 0.017, df = 130; “n-10” N = 131, statistic=0.40, P = 0.691, df = 130. Inset: swarm plots showing distribution of regression coefficient values across groups. d) Prediction of behaviour using neurons anchored at distal points (one state away or more) from the anchor. Top: Normalised firing rates of neurons during their “bump time”: i.e. the lag at which they are active relative to the anchor. Bump time activity is not higher before visits to the neuron’s anchoring behavioural step in trial N + 1 when the anchoring behavioural step was not visited in trial N (Top left) but was higher before visits to anchoring behavioural step in trial N + 1 when the anchoring behavioural step was visited in trial N (Top right). Wilcoxon tests (two-sided): Anchoring behavioural step not visited in trial N: n = 128 tasks, statistic=2917, P = 0.004. Anchoring behavioural step visited in trial N: n = 115 tasks, statistic=2534, P = 0.025. In addition, an ANOVA on all data (N = 115 tasks) showed no main effect of Past: F = 2.43, P = 0.122, df1 = 1, df2 = 114, a main effect of Future: F = 5.74, P = 0.018, df1 = 1, df2 = 114, no Past x Future interaction: F = 0.33, P = 0.566, df1 = 1, df2 = 114. Scatter plots showing individual points of the same data are shown next to each of the bar plots. Bottom left: A logistic regression showed significantly positive coefficients for the bump time but not all other control times. T-tests (two-sided) against 0: “bump time”: N = 128 tasks, statistic=3.68, P = 0.0, df = 127; “decision time”: N = 128 tasks, statistic = −0.56, P = 0.577, df = 127; “random time”: N = 128 tasks, statistic = −0.29, P = 0.769, df = 127; “90 degree shifted time”: N = 128 tasks, statistic = −1.61, P = 0.111, df = 127; “180 degree shifted time”: N = 128 tasks, statistic = −0.61, P = 0.543, df = 127; “270 degree shifted time”: N = 128 tasks, statistic = −2.75, P = 0.007, df = 127. Bottom right: swarm plots showing distribution of regression coefficient values across groups. e) Prediction of behaviour to intermediate (non-rewarded) locations i.e. excluding choices to reward locations. Top: Normalised firing rates of neurons during their “bump time”: i.e. the lag at which they are active relative to the anchor. Bump time activity is higher before visits to the neuron’s anchoring behavioural step in trial N + 1 when the anchoring behavioural step was not visited in trial N (Top left). Wilcoxon tests (two-sided): Anchoring behavioural step not visited in trial N: n = 126 tasks, statistic=2967, P = 0.011. Anchoring behavioural step visited in trial N: n = 120 tasks, statistic=3509, P = 0.751. In addition, an ANOVA on all data (N = 120 tasks) showed no main effect of Past: F = 1.77 P = 0.186, df1 = 1, df2 = 119, no effect of Future: F = 1.37 P = 0.244, df1 = 1, df2 = 119 and no Past x Future interaction F = 0.955 P = 0.330 df1 = 1, df2 = 119. Bottom left: A logistic regression showed coefficients were not significantly positive for any times. T-tests (two-sided) against 0: “bump time”: N = 126 tasks, statistic=1.6, P = 0.112, df = 125; “decision time”: N = 126 tasks, statistic = −2.18, P = 0.031, df = 125; “random time”: N = 126 tasks, statistic = −1.76, P = 0.081, df = 125; “90 degree shifted time”: N = 126 tasks, statistic = −0.54, P = 0.593, df = 125; “180 degree shifted time”: N = 126 tasks, statistic = −0.6, P = 0.552, df = 125; “270 degree shifted time”: N = 126 tasks, statistic = −1.93, P = 0.056, df = 125. Bottom right: swarm plots showing distribution of regression coefficient values across groups. f) Prediction of behaviour to intermediate (non-rewarded) locations i.e. excluding choices to reward locations using Anchor x Task as Ns. Top: Normalised firing rates of neurons during their “bump time”: i.e. the lag at which they are active relative to the anchor. Bump time activity is higher before visits to the neuron’s anchor in trial N + 1 when the anchoring behavioural step was not visited in trial N (Top left) and when it is visited in trial N (Top right). Anchoring behavioural step not visited in trial N: n = 821 anchor-tasks, statistic=154018, P = 0.031. Anchoring behavioural step visited in trial N: n = 529 anchor-tasks, statistic=61812, P = 0.045. In addition, an ANOVA on all data (N = 529 anchor-tasks) showed no main effect of Past: F = 2.66, P = 0.104, df1 = 1, df2 = 526, a trend towards a main effect of Future: F = 2.92, P = 0.088, df1 = 1, df2 = 526, no Past x Future interaction: F = 0.97, P = 0.325, df1 = 1, df2 = 526. Bottom left: A logistic regression showed coefficients were significantly positive for “bump time” but not other times. T-tests (two-sided) against 0: “bump time”: N = 824 anchor-tasks, statistic=2.65, P = 0.008, df = 823; “decision time”: N = 824 anchor-tasks, statistic = −3.12, P = 0.002, df = 823; “random time”: N = 824 anchor-tasks, statistic=0.0, P = 0.998, df = 823; “90 degree shifted time”: N = 824 anchor-tasks, statistic = −3.48, P = 0.001, df = 823; “180 degree shifted time”: N = 824 anchor-tasks, statistic = −0.33, P = 0.744, df = 823; “270 degree shifted time”: N = 824 anchor-tasks, statistic = −2.47, P = 0.014, df = 823. Bottom right: Kernel density estimate plots showing distribution of regression coefficient values across groups. g) Prediction of behaviour to intermediate (non-rewarded) locations i.e. excluding choices to reward locations using all non-zero lag neurons (i.e. not only consistently anchored ones as in all other plots). Top: Normalised firing rates of neurons during their “bump time”: i.e. the lag at which they are active relative to the anchor. Bump time activity is higher before visits to the neuron’s anchoring behavioural step in trial N + 1 when the anchoring behavioural step was visited in trial N (Top right). Wilcoxon tests (two-sided): Anchoring behavioural step not visited in trial N: n = 130 tasks, statistic=3565, P = 0.108. Anchoring behavioural step visited in trial N: n = 130 tasks, statistic=3287, P = 0.024. In addition, an ANOVA on all data (N = 130 tasks) showed no main effect of Past: F = 1.99, P = 0.161, df1 = 1, df2 = 129, no main effect of Future: F = 1.88, P = 0.173, df1 = 1, df2 = 129, no Past x Future interaction: F = 2.11, P = 0.149, df1 = 1, df2 = 129. Bottom left: A logistic regression showed coefficients were significantly positive for “bump time” but not other times. T-tests (two-sided) against 0: “bump time”: N = 130 tasks, statistic=2.08, P = 0.039, df = 129; “decision time”: N = 130 tasks, statistic = −2.83, P = 0.005, df = 129; “random time”: N = 130 tasks, statistic = −0.84, P = 0.402, df = 129; “90 degree shifted time”: N = 130 tasks, statistic = −4.16, P = 5.95 × 10−5, df = 129; “180 degree shifted time”: N = 130 tasks, statistic = −0.35, P = 0.728, df = 129; “270 degree shifted time”: N = 130 tasks, statistic = −3.18, P = 0.002, df = 129. Bottom right: Swarm plots showing distribution of regression coefficient values across groups. h) Prediction of behaviour to intermediate (non-rewarded) locations i.e. excluding choices to reward locations using all non-zero lag neurons (i.e. not only consistently anchored ones as in all other plots) and using Anchor x Task as Ns. Top: Normalised firing rates of neurons during their “bump time”: i.e. the lag at which they are active relative to the anchor. Bump time activity is higher before visits to the neuron’s anchoring behavioural step in trial N + 1 when the anchoring behavioural step was visited in trial N (Top right) and showed a trend towards being higher when the anchor wasn’t visited in trial N (Top left). Anchoring behavioural step not visited in trial N: n = 1273 anchor-tasks, statistic=380465, P = 0.063. Anchoring behavioural step visited in trial N: n = 826 anchor-tasks, statistic=141977, P = 8.36 × 10−5. In addition, an ANOVA on all data (N = 826 anchor-tasks) showed a main effect of Past: F = 4.66, P = 0.031, df1 = 1, df2 = 821, a main effect of Future: F = 6.65, P = 0.010, df1 = 1, df2 = 821, a Past x Future interaction: F = 5.38, P = 0.021, df1 = 1, df2 = 821. Bottom left: A logistic regression showed coefficients were significantly positive for “bump time” but not other times. T-tests (two-sided) against 0: “bump time”: N = 1278 anchor-tasks, statistic=3.23, P = 0.001, df = 1277; “decision time”: N = 1278 anchor-tasks, statistic = −3.52, P = 4.39 × 10−4, df = 1277; “random time”: N = 1278 anchor-tasks, statistic = −1.79, P = 0.073, df = 1277; “90 degree shifted time”: N = 1278 anchor-tasks, statistic = −5.16, P = 2.92 × 10−7, df = 1277; “180 degree shifted time”: N = 1278 anchor-tasks, statistic = −0.37, P = 0.709, df = 1277; “270 degree shifted time”: N = 1278 anchor-tasks, statistic = −4.37, P = 1.36 × 10−5, df = 1277. Bottom right: Kernel density estimate plots showing distribution of regression coefficient values across groups. i) Prediction of behaviour in the ABCDE tasks. Top: Normalised firing rates of neurons during their “bump time”: i.e. the lag at which they are active relative to the anchor. Bump time activity is higher before visits to the neuron’s anchor in trial N + 1 when the anchoring behavioural step was not visited in trial N (Top left) and also higher before visits to anchoring behavioural step in trial N + 1 when the anchoring behavioural step was visited in trial N (Top right). Wilcoxon tests (two-sided): Anchoring behavioural step not visited in trial N: n = 24 tasks, statistic=73, P = 0.027. Anchoring behavioural step visited in trial N: n = 24 tasks, statistic=48, P = 0.003. In addition, an ANOVA on all data (N = 24 tasks) showed a main effect of Past: F = 18.57, P = 2.61 × 10−4, df1 = 1, df2 = 23, a main effect of Future: F = 19.9, P = 1.78 × 10−4, df1 = 1, df2 = 23, a Past x Future interaction: F = 5.84, P = 0.024, df1 = 1, df2 = 23. Bottom left: A logistic regression showed coefficients were positive for the bump time but not all other control times. T-tests (two-sided) against 0: “bump time”: N = 24 tasks, statistic=2.91, P = 0.008, df = 23; “decision time”: N = 24 tasks, statistic = −1.17, P = 0.252, df = 23; “random time”: N = 24 tasks, statistic = −1.33, P = 0.197, df = 23; “72 degree shifted time”: N = 24 tasks, statistic = −1.97, P = 0.061, df = 23; “144 degree shifted time”: N = 24 tasks, statistic = −0.8, P = 0.43, df = 23; “216 degree shifted time”: N = 24 tasks, statistic = −0.83, P = 0.417, df = 23; “288 degree shifted time”: N = 24 tasks, statistic = −0.88, P = 0.390, df = 23. Bottom right: Swarm plots showing distribution of regression coefficient values across groups. All error bars represent the standard error of the mean.