

Information consumption and firm size
- PMID: 39507997
- PMCID: PMC11539792
- DOI: 10.1098/rsos.240027
Information consumption and firm size
Abstract
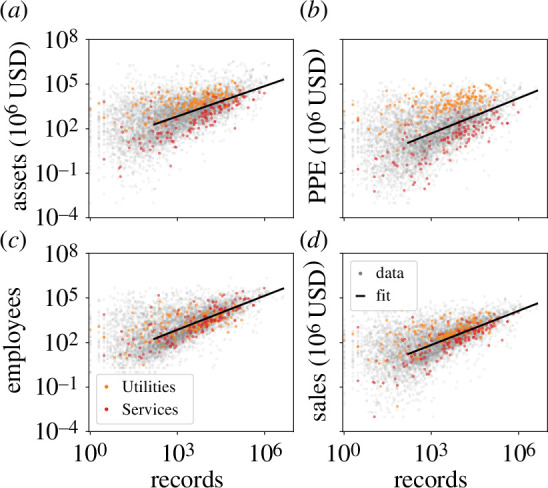
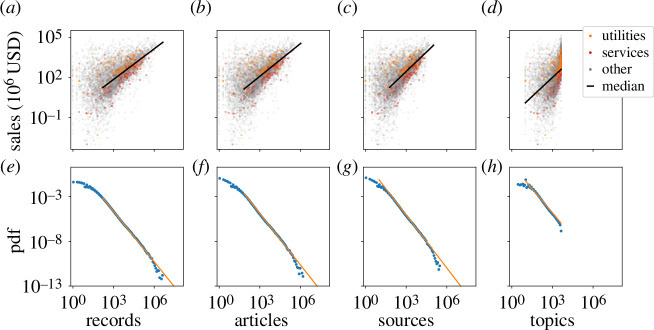
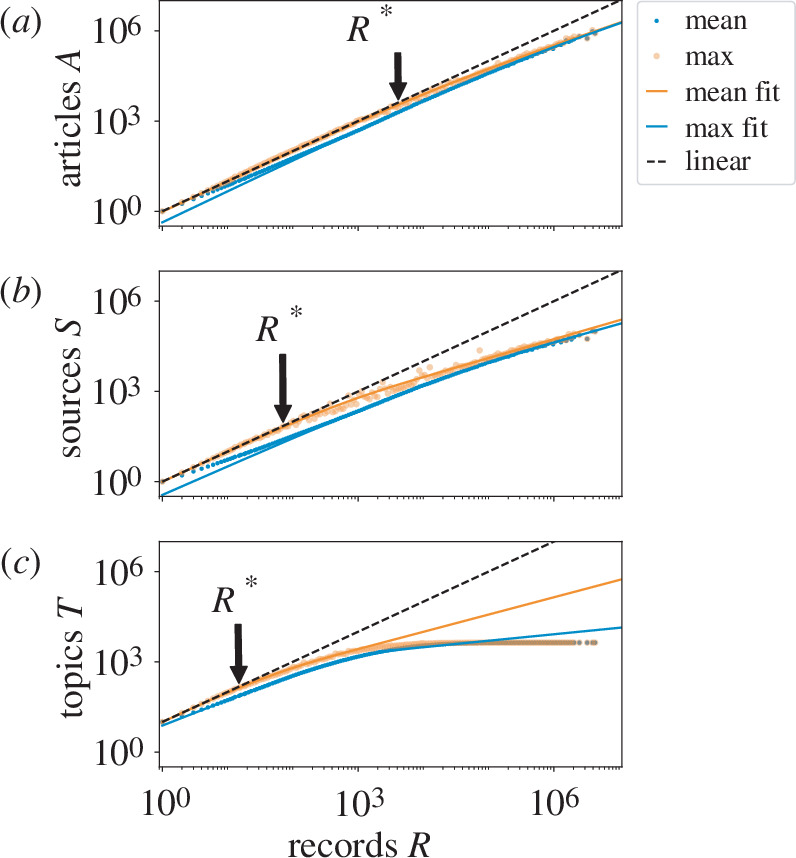
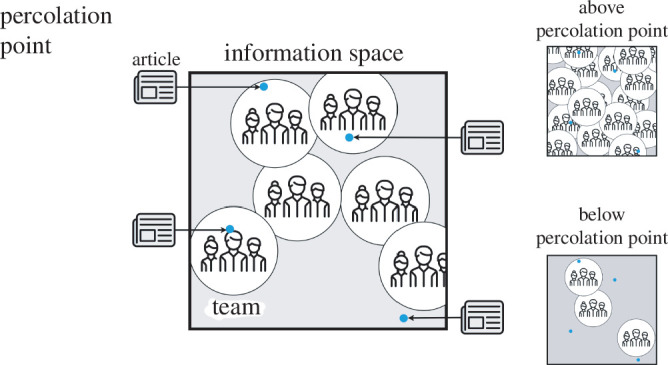
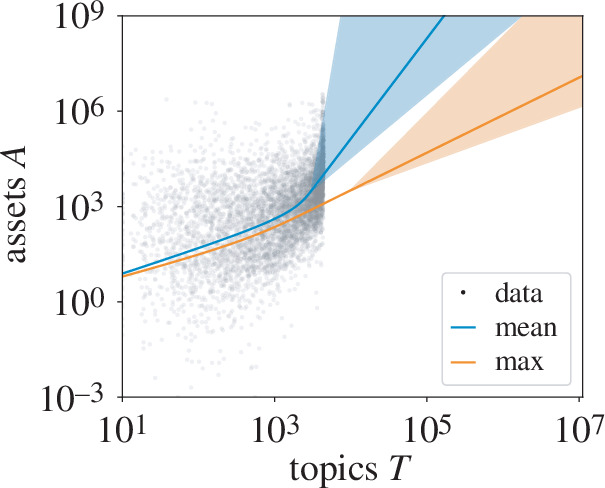
Social and biological collectives exchange information through internal networks to function. Less studied is the quantity and variety of information transmitted. We characterize the information flow into organizations, primarily business firms. We measure online reading using a large dataset of articles accessed by employees across millions of firms. We measure and relate quantitatively three aspects: reading volume, variety and firm size. We compare volume with size, showing that firm sizes grow sublinearly with reading volume. This is like an economy of scale in information consumption that exaggerates the classic Zipf's law inequality for firm economics. We connect variety and volume to show that reading variety is limited. Firms above a threshold size read repetitively, consistent with the onset of a coordination problem between teams of employees in a simple model. Finally, we relate reading variety to size. The relationship is consistent with large firms that accumulate interests as they grow. We argue that this reflects structural constraints. Taking the scaling relations as a baseline, we show that excess reading is strongly correlated with returns and valuations. The results indicate how information consumption reflects internal structure, beyond individual employees, as is likewise important for collective information processing in other systems.
Keywords: firms; information; reading; scaling.
© 2024 The Author(s).
Conflict of interest statement
We declare we have no competing interests.
Figures
References
Associated data
LinkOut - more resources
Full Text Sources