

Model-averaged Bayesian t tests
- PMID: 39511109
- PMCID: PMC12092555
- DOI: 10.3758/s13423-024-02590-5
Model-averaged Bayesian t tests
Abstract
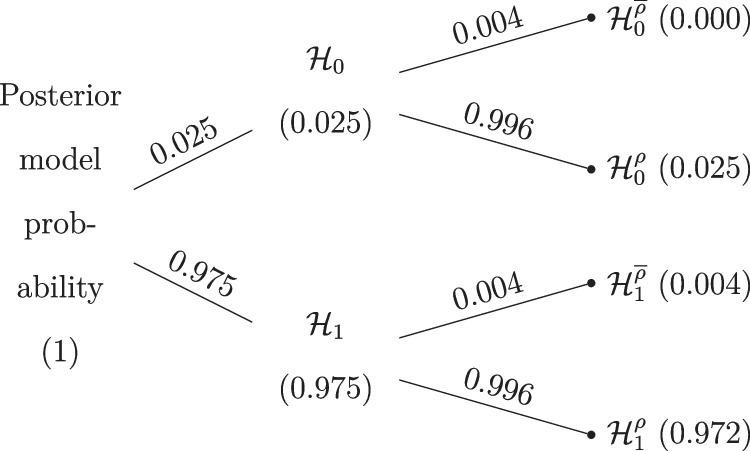
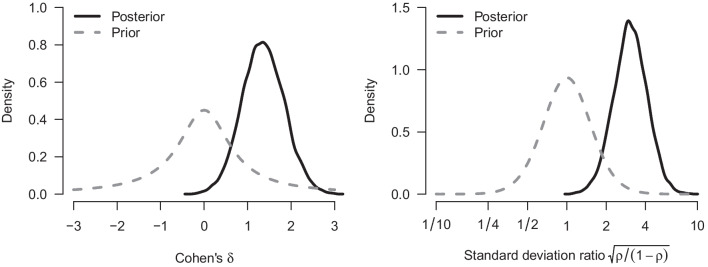
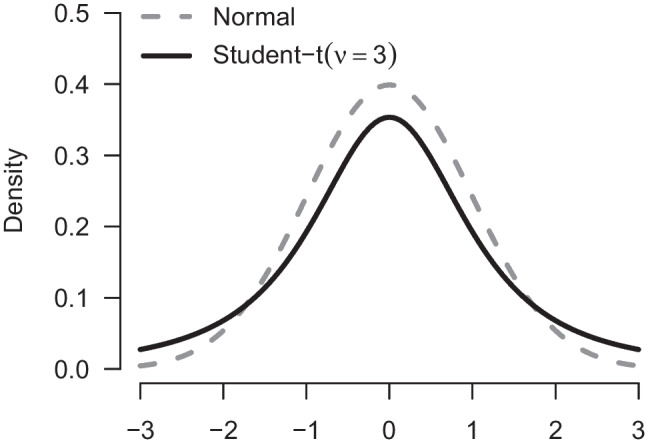
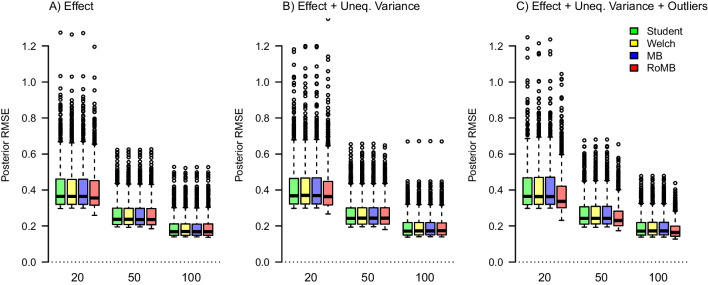
One of the most common statistical analyses in experimental psychology concerns the comparison of two means using the frequentist t test. However, frequentist t tests do not quantify evidence and require various assumption tests. Recently, popularized Bayesian t tests do quantify evidence, but these were developed for scenarios where the two populations are assumed to have the same variance. As an alternative to both methods, we outline a comprehensive t test framework based on Bayesian model averaging. This new t test framework simultaneously takes into account models that assume equal and unequal variances, and models that use t-likelihoods to improve robustness to outliers. The resulting inference is based on a weighted average across the entire model ensemble, with higher weights assigned to models that predicted the observed data well. This new t test framework provides an integrated approach to assumption checks and inference by applying a series of pertinent models to the data simultaneously rather than sequentially. The integrated Bayesian model-averaged t tests achieve robustness without having to commit to a single model following a series of assumption checks. To facilitate practical applications, we provide user-friendly implementations in JASP and via the package in . A tutorial video is available at https://www.youtube.com/watch?v=EcuzGTIcorQ.
Keywords: t-likelihood; t test; Bayes factor; Bayesian model-averaging; Robust inference; Unequal variances.
© 2024. The Author(s).
Conflict of interest statement
Declarations. Competing Interests: The authors declare no competing interests.
Figures


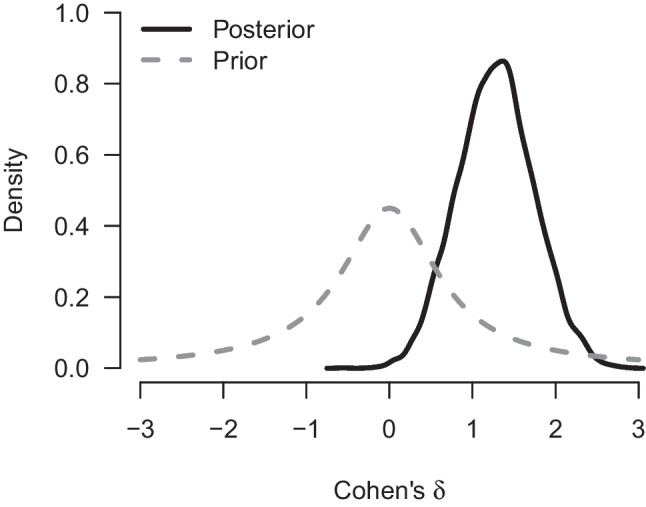
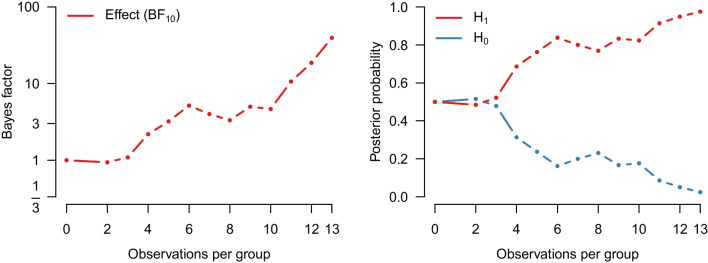
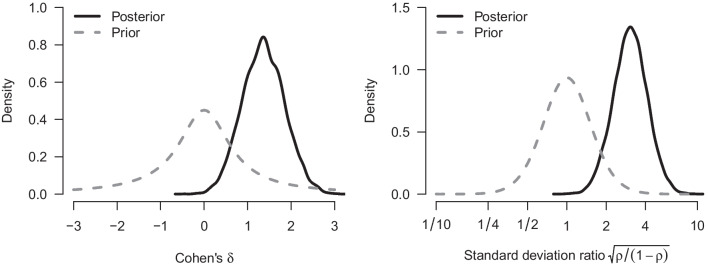
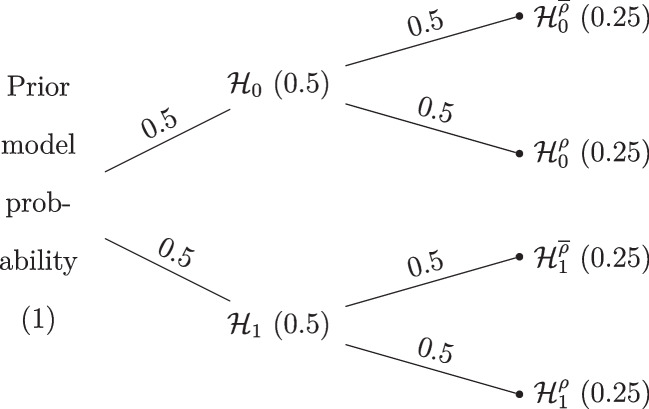











References
-
- Alipourfard, N., Arendt, B., Benjamin, D. M., Benkler, N., Bishop, M., Burstein, M., ... Clark, C., Et al. (2021). Systematizing confidence in open research and evidence (score).
-
- Barbieri, A., Marin, J. M., & Florin, K. (2016). A fully objective Bayesian approach for the Behrens-Fisher problem using historical studies. arXiv:1611.06873
-
- Bartolucci, A. A., Blanchard, P. D., Howell, W. M., & Singh, K. P. (1998). A Bayesian Behrens-Fisher solution to a problem in taxonomy. Environmental Modelling & Software,13(1), 25–29. 10.1016/S1364-8152(97)00033-9
-
- Bartoš, F., & Maier, M. (2022). RoBTT: An R package for robust Bayesian t-test.[SPACE]https://CRAN.R-project.org/package=RoBTT. (R package)
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
