

Database Resources of the National Genomics Data Center, China National Center for Bioinformation in 2025
- PMID: 39530327
- PMCID: PMC11701749
- DOI: 10.1093/nar/gkae978
Database Resources of the National Genomics Data Center, China National Center for Bioinformation in 2025
Abstract
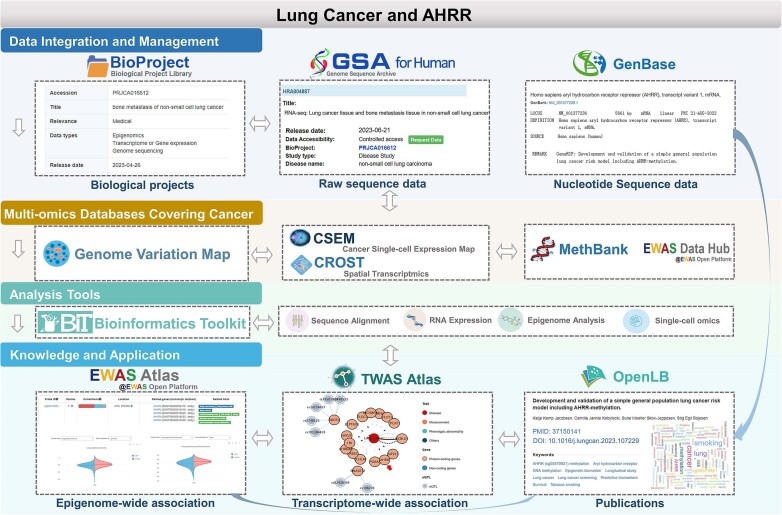
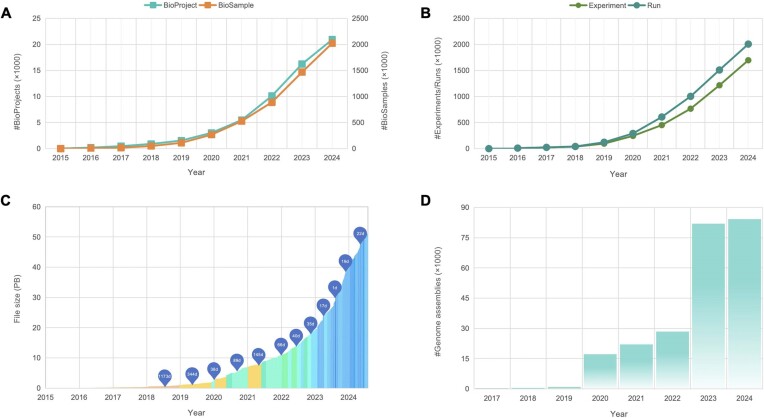
The National Genomics Data Center (NGDC), which is a part of the China National Center for Bioinformation (CNCB), offers a comprehensive suite of database resources to support the global scientific community. Amidst the unprecedented accumulation of multi-omics data, CNCB-NGDC is committed to continually evolving and updating its core database resources through big data archiving, integrative analysis and value-added curation. Over the past year, CNCB-NGDC has expanded its collaborations with international databases and established new subcenters focusing on biodiversity, traditional Chinese medicine and tumor genetics. Substantial efforts have been made toward encompassing a broad spectrum of multi-omics data, developing innovative resources and enhancing existing resources. Notably, new resources have been developed for single-cell omics (scTWAS Atlas), genome and variation (VDGE), health and disease (CVD Atlas, CPMKG, Immunosenescence Inventory, HemAtlas, Cyclicpepedia, IDeAS), biodiversity and biosynthesis (RefMetaPlant, MASH-Ocean) and research tools (CCLHunter). All resources and services are publicly accessible at https://ngdc.cncb.ac.cn.
© The Author(s) 2024. Published by Oxford University Press on behalf of Nucleic Acids Research.
Figures

References
-
- Rozenblatt-Rosen O., Stubbington M.J.T., Regev A., Teichmann S.A.. The Human Cell Atlas: from vision to reality. Nature. 2017; 550:451–453. - PubMed
MeSH terms
Grants and funding
- XDB38030200/Chinese Academy of Sciences
- 2023YFC2605700/National Key Research and Development Program of China
- T2425005/National Natural Science Foundation of China
- 2019kfyRCPY043/Fundamental Research Funds for the Central Universities
- NAF\R1\191094/UK Royal Society-Newton Advanced Fellowship
- Key Technology Talent Program
- K.C. Wong Education Foundation
- SQ2017YFSF090210/National Key R&D Program of China
- 2019M652623/China Postdoctoral Science Foundation
- The Open Biodiversity and Health Big Data Program of IUBS
- ANSO-PA-2023-07/The Alliance of National and International Science Organizations for the Belt and Road Regions
- 2018FY10080002/Funds for Basic Resources Investigation Research of the Ministry of Science and Technology
- 2019FY100102/Special Project on National Science and Technology Basic Resources Investigation
- CAS Pioneer 100-Talent Program
- KFZD-SW-219-5/Key Research Program of the Chinese Academy of Sciences
- ZJ2018-ZD-013/Zhangjiang National Innovation Demonstration Zone
- Science and Technology Service Network Initiative of Chinese Academy of Sciences
- 2018wk4001/Hunan Provincial Science and Technology Program
- B18059/111 Project
- FCC/1/1976-18-01/King Abdullah University of Science and Technology
- KFJ-BRP-017-79/Biological Resources Programme, Chinese Academy of Sciences
- 202044/Specialized Research Assistant Program of the Chinese Academy of Sciences
- 32061143024/National Natural Science Foundation of China
- 2017SHZDZX01/Shanghai Municipal Science and Technology Commission
- 2019ZT08Y464/Guangdong Province 'Pearl River Talent Plan' Innovation and Entrepreneurship Team Project
- 2020B1111170004/Guangdong Provincial Clinical Research Center for Digestive Diseases
- CAS-WX2021SF-0307/National Key Clinical Discipline and the Informatization Plan of Chinese Academy of Sciences
- 2022ZD0401701/Technological Innovation 2030
- Z211100002121006/Beijing Nova Program
- 2022FY101203/Science and Technology Fundamental Resources Investigation Program
LinkOut - more resources
Full Text Sources
Miscellaneous
