

Computational and Neural Evidence for Altered Fast and Slow Learning from Losses in Problem Gambling
- PMID: 39557579
- PMCID: PMC11694394
- DOI: 10.1523/JNEUROSCI.0080-24.2024
Computational and Neural Evidence for Altered Fast and Slow Learning from Losses in Problem Gambling
Abstract
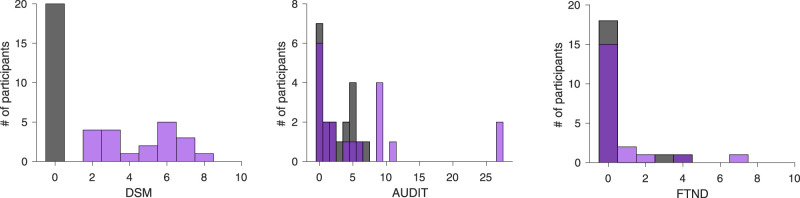
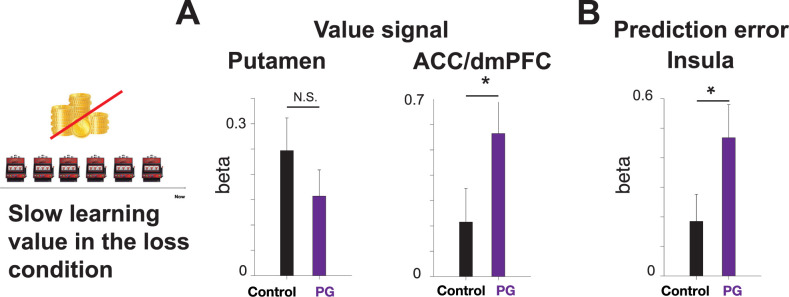
Learning occurs across multiple timescales, with fast learning crucial for adapting to sudden environmental changes, and slow learning beneficial for extracting robust knowledge from multiple events. Here, we asked if miscalibrated fast vs slow learning can lead to maladaptive decision-making in individuals with problem gambling. We recruited participants with problem gambling (PG; N = 20; 9 female and 11 male) and a recreational gambling control group without any symptoms associated with PG (N = 20; 10 female and 10 male) from the community in Los Angeles, CA. Participants performed a decision-making task involving reward-learning and loss-avoidance while being scanned with fMRI. Using computational model fitting, we found that individuals in the PG group showed evidence for an excessive dependence on slow timescales and a reduced reliance on fast timescales during learning. fMRI data implicated the putamen, an area associated with habit, and medial prefrontal cortex (PFC) in slow loss-value encoding, with significantly more robust encoding in medial PFC in the PG group compared to controls. The PG group also exhibited stronger loss prediction error encoding in the insular cortex. These findings suggest that individuals with PG have an impaired ability to adjust their predictions following losses, manifested by a stronger influence of slow value learning. This impairment could contribute to the behavioral inflexibility of problem gamblers, particularly the persistence in gambling behavior typically observed in those individuals after incurring loss outcomes.
Keywords: decision-making; fMRI; gambling; learning.
Copyright © 2024 the authors.
Figures




References
-
- Bialek W (2005) “Should You Believe that This Coin is Fair?” arXiv preprint q-bio/0508044.
-
- Choi JS, Shin YC, Jung WH, Jang JH, Kang DH, Choi CH, Choi SW, Lee JY, Hwang JY, Kwon JS (2012) Altered brain activity during reward anticipation in pathological gambling and obsessive-compulsive disorder.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous