

A strategy for cost-effective large language model use at health system-scale
- PMID: 39558090
- PMCID: PMC11574261
- DOI: 10.1038/s41746-024-01315-1
A strategy for cost-effective large language model use at health system-scale
Abstract
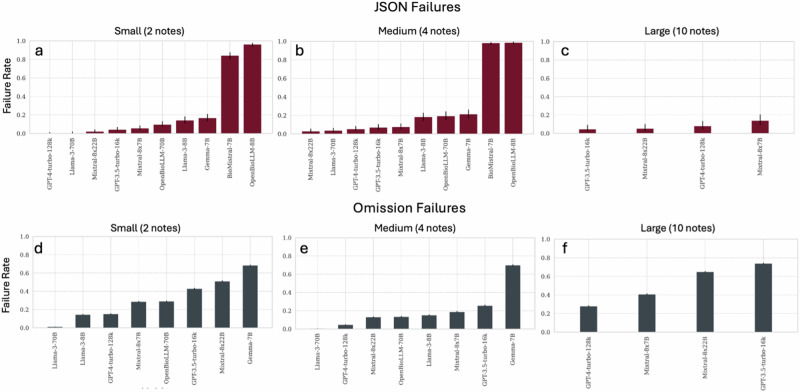
Large language models (LLMs) can optimize clinical workflows; however, the economic and computational challenges of their utilization at the health system scale are underexplored. We evaluated how concatenating queries with multiple clinical notes and tasks simultaneously affects model performance under increasing computational loads. We assessed ten LLMs of different capacities and sizes utilizing real-world patient data. We conducted >300,000 experiments of various task sizes and configurations, measuring accuracy in question-answering and the ability to properly format outputs. Performance deteriorated as the number of questions and notes increased. High-capacity models, like Llama-3-70b, had low failure rates and high accuracies. GPT-4-turbo-128k was similarly resilient across task burdens, but performance deteriorated after 50 tasks at large prompt sizes. After addressing mitigable failures, these two models can concatenate up to 50 simultaneous tasks effectively, with validation on a public medical question-answering dataset. An economic analysis demonstrated up to a 17-fold cost reduction at 50 tasks using concatenation. These results identify the limits of LLMs for effective utilization and highlight avenues for cost-efficiency at the enterprise scale.
© 2024. The Author(s).
Conflict of interest statement
Figures




References
Grants and funding
LinkOut - more resources
Full Text Sources
