

A functional microbiome catalogue crowdsourced from North American rivers
- PMID: 39567690
- PMCID: PMC11666465
- DOI: 10.1038/s41586-024-08240-z
A functional microbiome catalogue crowdsourced from North American rivers
Abstract
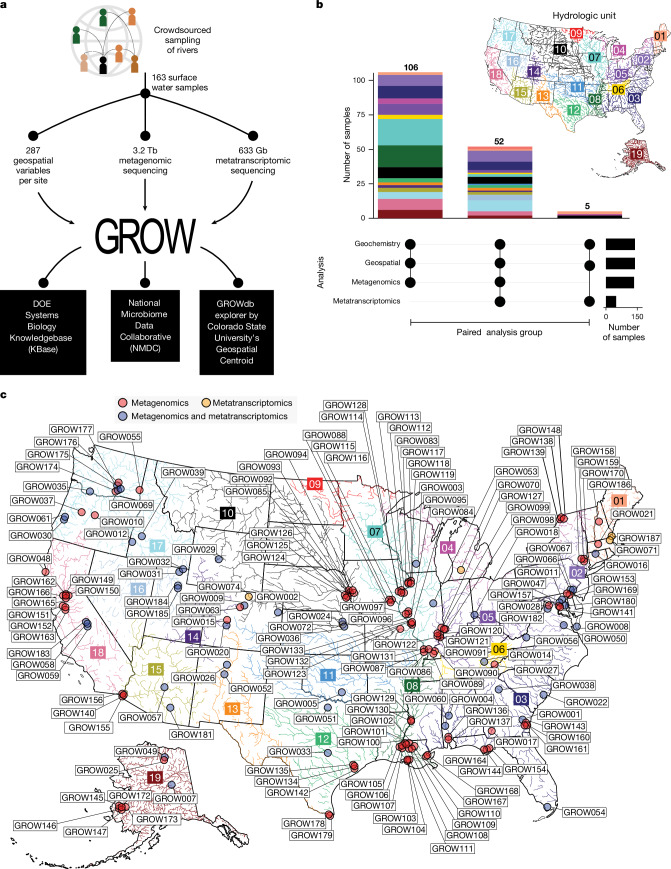
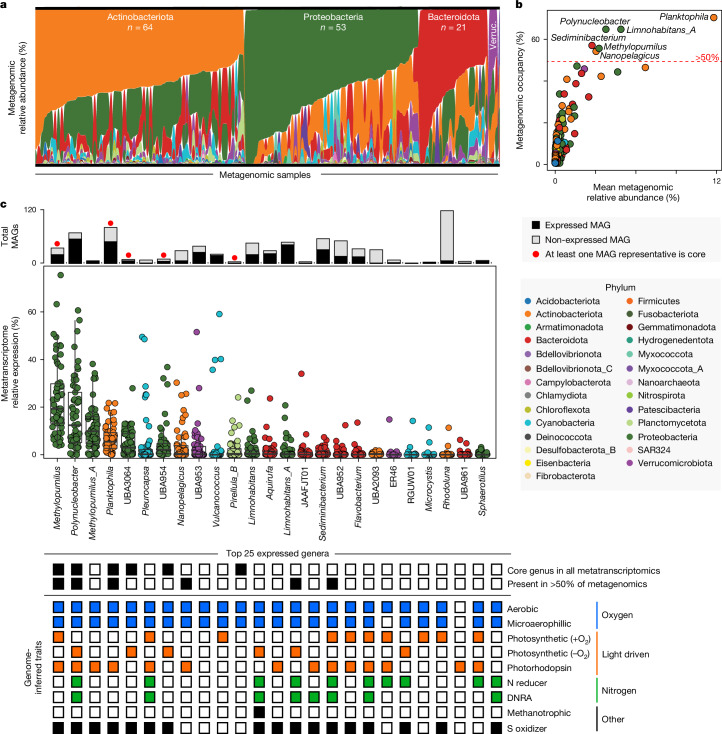
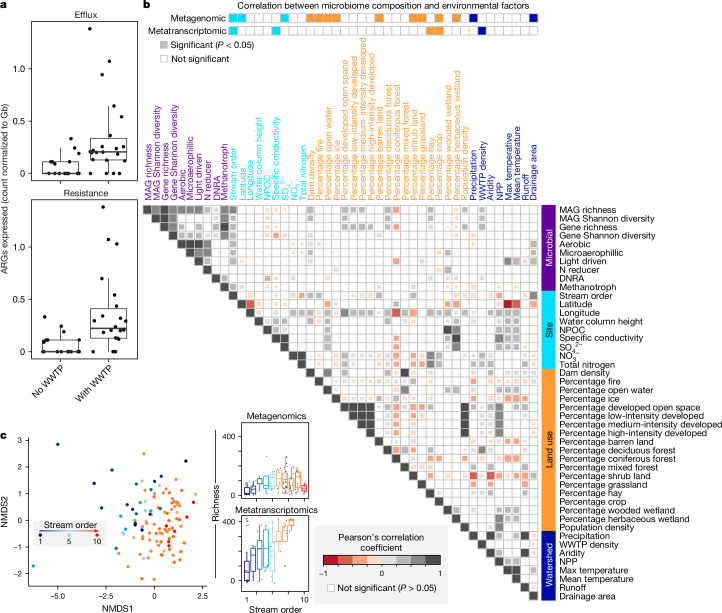
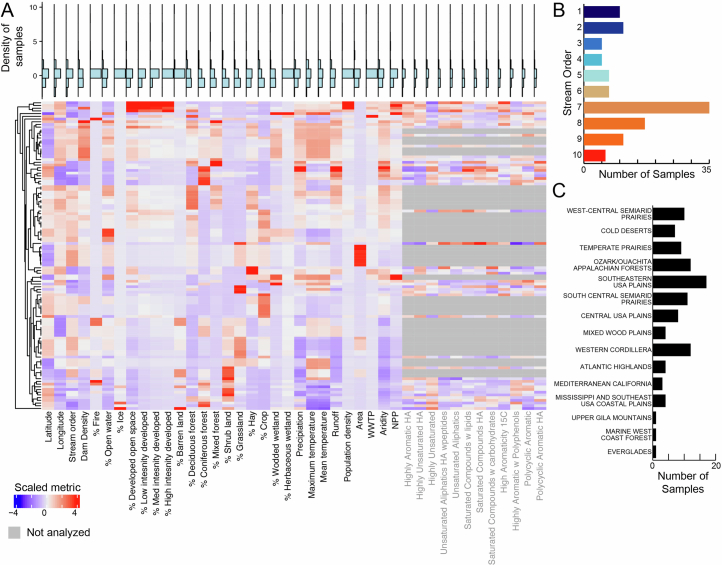
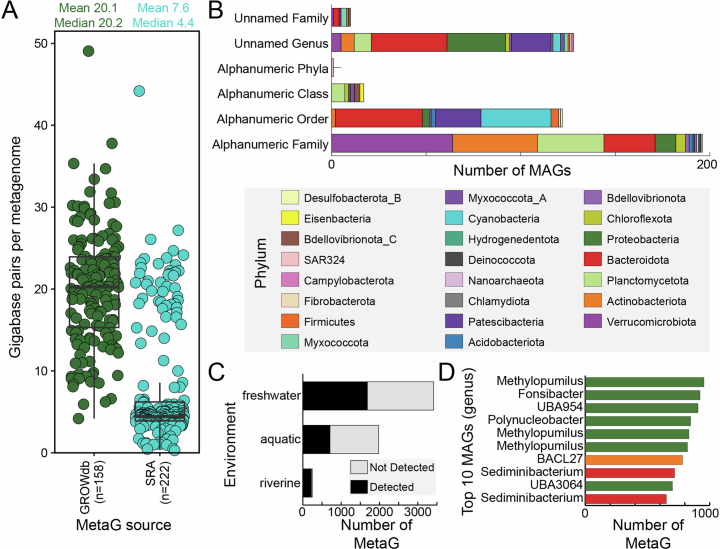
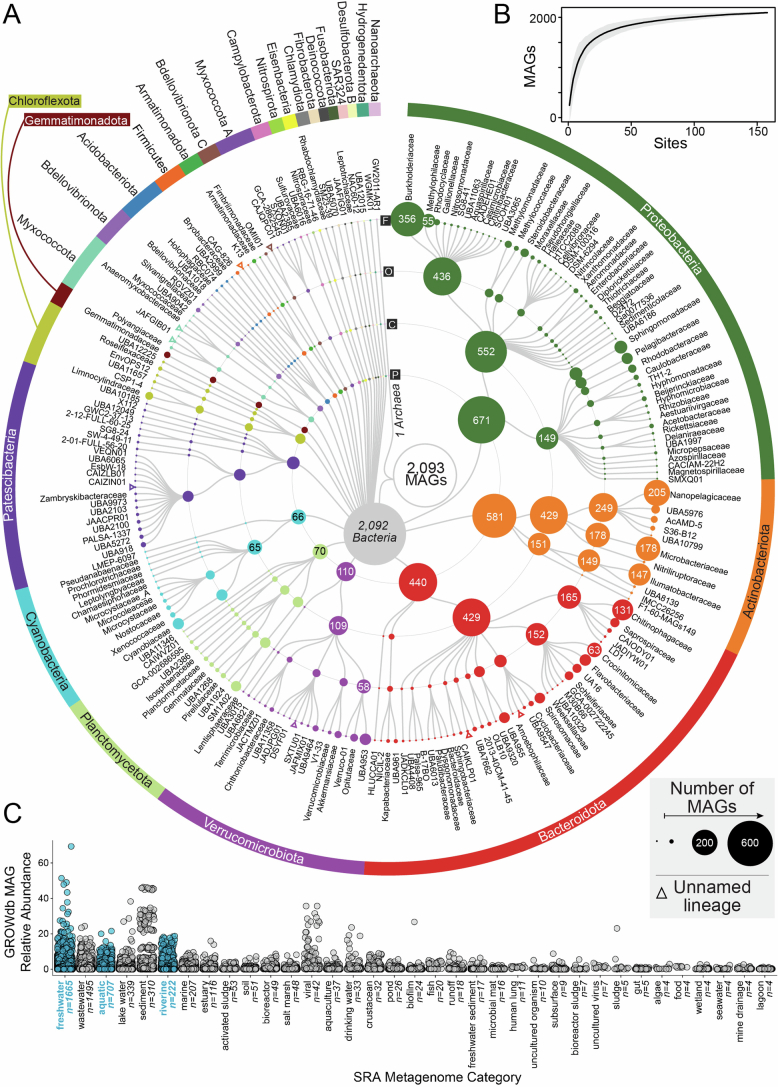
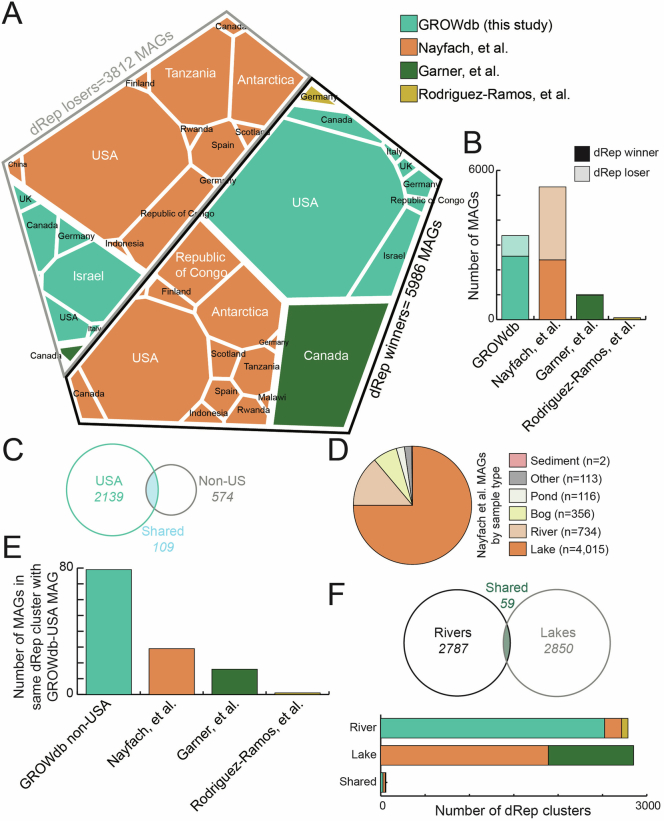
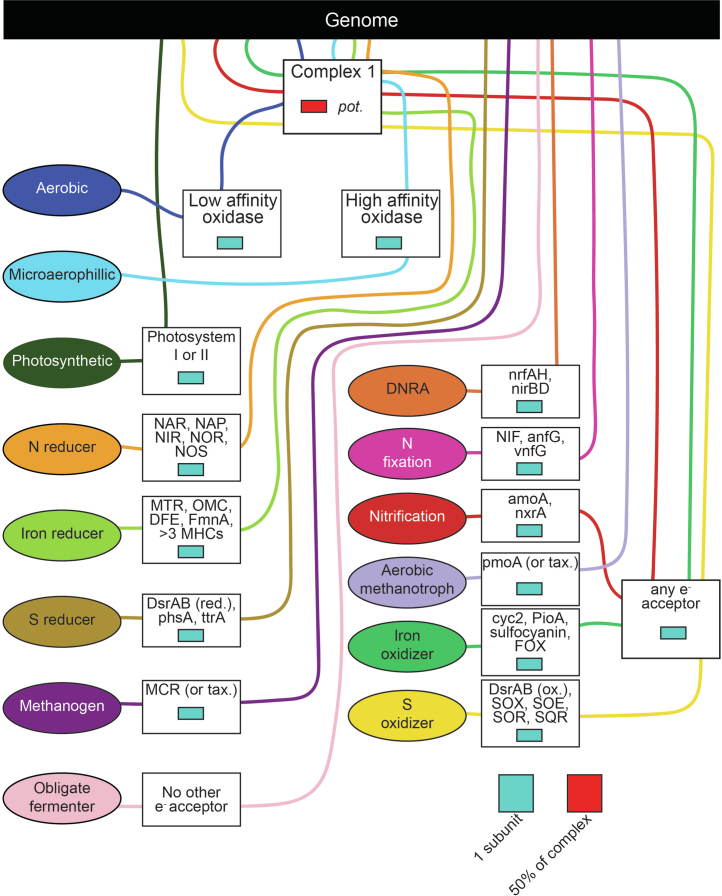
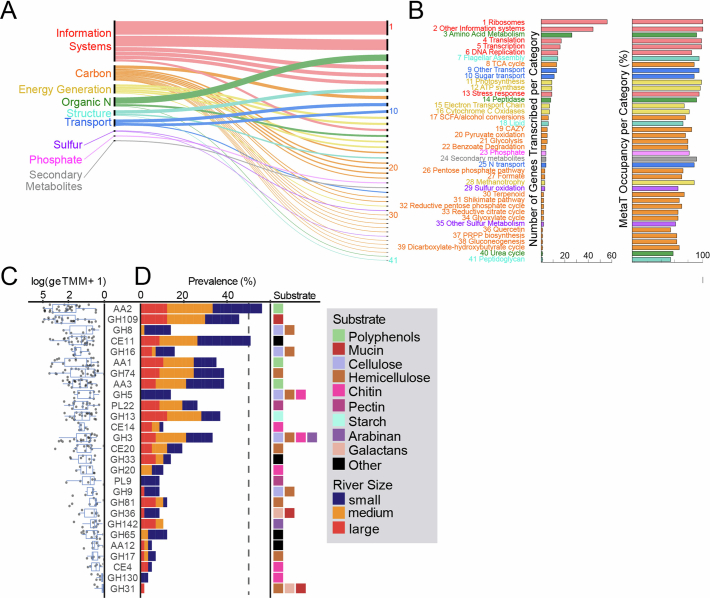
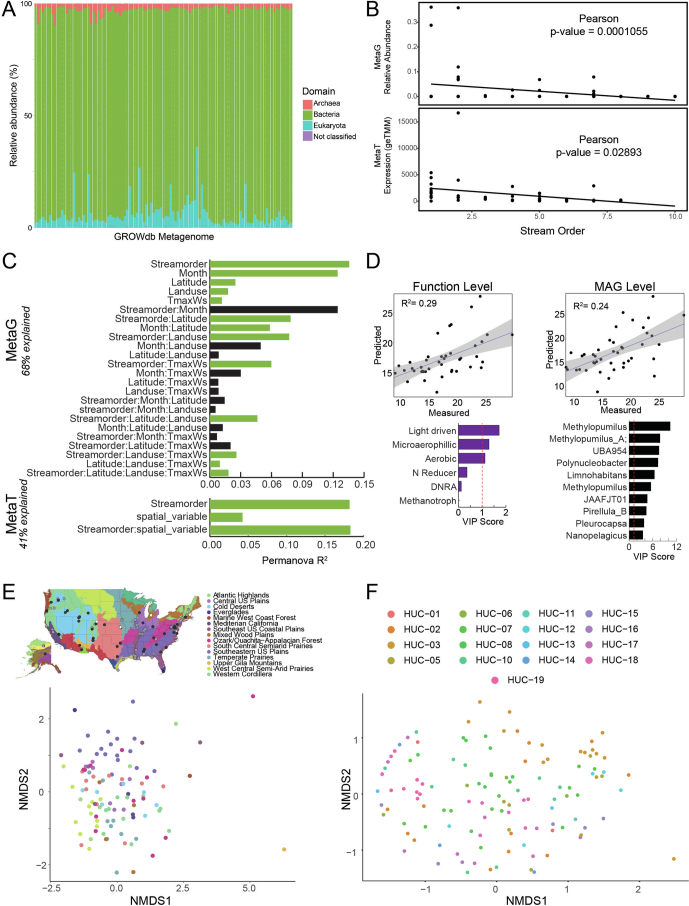
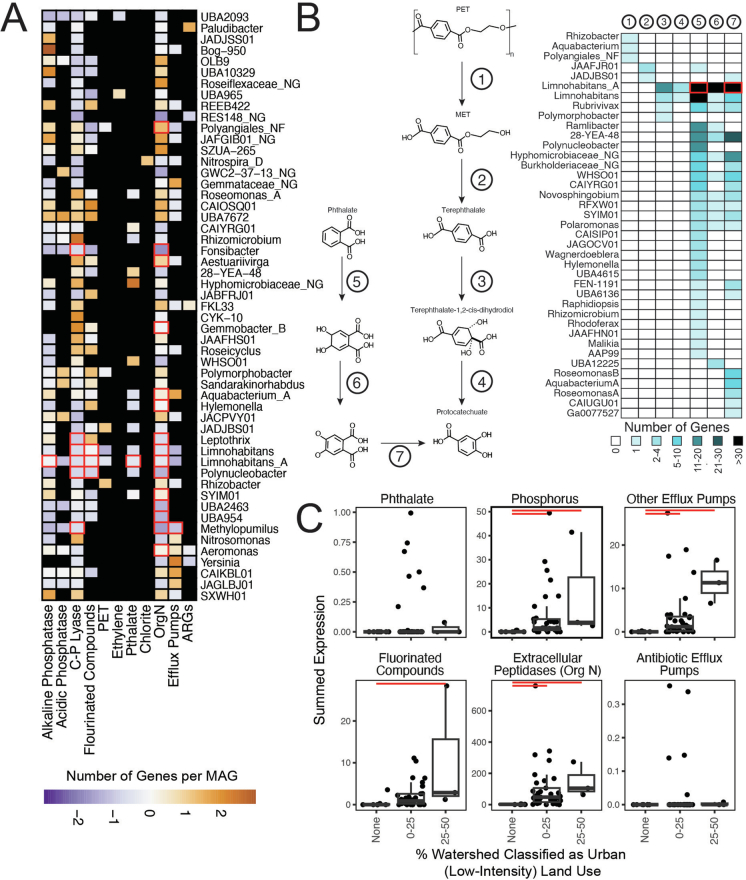
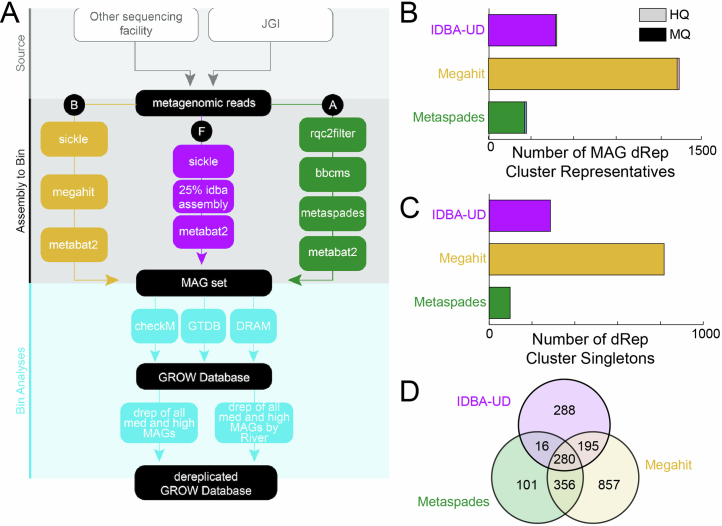
Predicting elemental cycles and maintaining water quality under increasing anthropogenic influence requires knowledge of the spatial drivers of river microbiomes. However, understanding of the core microbial processes governing river biogeochemistry is hindered by a lack of genome-resolved functional insights and sampling across multiple rivers. Here we used a community science effort to accelerate the sampling, sequencing and genome-resolved analyses of river microbiomes to create the Genome Resolved Open Watersheds database (GROWdb). GROWdb profiles the identity, distribution, function and expression of microbial genomes across river surface waters covering 90% of United States watersheds. Specifically, GROWdb encompasses microbial lineages from 27 phyla, including novel members from 10 families and 128 genera, and defines the core river microbiome at the genome level. GROWdb analyses coupled to extensive geospatial information reveals local and regional drivers of microbial community structuring, while also presenting foundational hypotheses about ecosystem function. Building on the previously conceived River Continuum Concept1, we layer on microbial functional trait expression, which suggests that the structure and function of river microbiomes is predictable. We make GROWdb available through various collaborative cyberinfrastructures2,3, so that it can be widely accessed across disciplines for watershed predictive modelling and microbiome-based management practices.
© 2024. The Author(s).
Conflict of interest statement
Competing interests: The authors declare no competing interests.
Figures

Update of
-
A functional microbiome catalog crowdsourced from North American rivers.bioRxiv [Preprint]. 2023 Jul 26:2023.07.22.550117. doi: 10.1101/2023.07.22.550117. bioRxiv. 2023. Update in: Nature. 2025 Jan;637(8044):103-112. doi: 10.1038/s41586-024-08240-z. PMID: 37502915 Free PMC article. Updated. Preprint.
References
-
- Vannote, R. L., Minshall, G. W., Cummins, K. W., Sedell, J. R. & Cushing, C. E. The river continuum concept. Can. J. Fish. Aquat. Sci.37, 130–137 (1980).
-
- Wood-Charlson, E. M. et al. The National Microbiome Data Collaborative: enabling microbiome science. Nat. Rev. Microbiol.18, 313–314 (2020). - PubMed
-
- Hutchins, D. A. & Fu, F. Microorganisms and ocean global change. Nat. Microbiol.2, 17058 (2017). - PubMed
