

Learning high-accuracy error decoding for quantum processors
- PMID: 39567694
- PMCID: PMC11602728
- DOI: 10.1038/s41586-024-08148-8
Learning high-accuracy error decoding for quantum processors
Abstract
Building a large-scale quantum computer requires effective strategies to correct errors that inevitably arise in physical quantum systems1. Quantum error-correction codes2 present a way to reach this goal by encoding logical information redundantly into many physical qubits. A key challenge in implementing such codes is accurately decoding noisy syndrome information extracted from redundancy checks to obtain the correct encoded logical information. Here we develop a recurrent, transformer-based neural network that learns to decode the surface code, the leading quantum error-correction code3. Our decoder outperforms other state-of-the-art decoders on real-world data from Google's Sycamore quantum processor for distance-3 and distance-5 surface codes4. On distances up to 11, the decoder maintains its advantage on simulated data with realistic noise including cross-talk and leakage, utilizing soft readouts and leakage information. After training on approximate synthetic data, the decoder adapts to the more complex, but unknown, underlying error distribution by training on a limited budget of experimental samples. Our work illustrates the ability of machine learning to go beyond human-designed algorithms by learning from data directly, highlighting machine learning as a strong contender for decoding in quantum computers.
© 2024. The Author(s).
Conflict of interest statement
Competing interests: Author-affiliated entities have filed US and international patent applications related to quantum error-correction using neural networks and to use of in-phase and quadrature information in decoding, including US18/237,204, PCT/US2024/036110, US18/237,323, PCT/US2024/036120, US18/237,331, PCT/US2024/036167, US18/758,727 and PCT/US2024/036173.
Figures
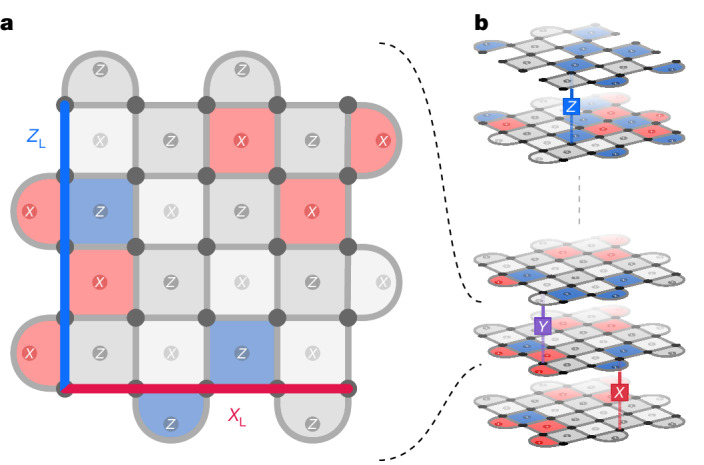


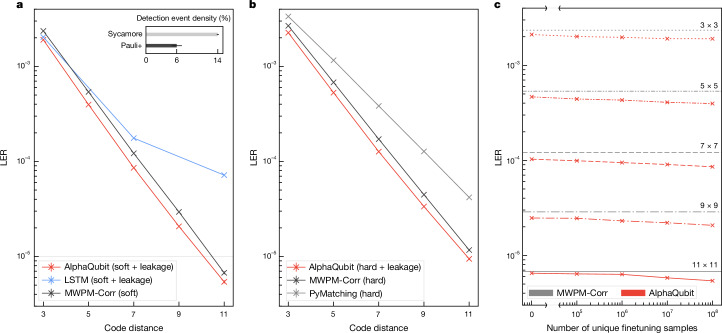











References
-
- Shor, P. W. Scheme for reducing decoherence in quantum computer memory. Phys. Rev. A52, R2493–R2496 (1995). - PubMed
-
- Gottesman, D. E. Stabilizer Codes and Quantum Error Correction. PhD thesis, California Institute of Technology (1997).
-
- Fowler, A. G., Mariantoni, M., Martinis, J. M. & Cleland, A. N. Surface codes: towards practical large-scale quantum computation. Phys. Rev. A86, 032324 (2012).
-
- Feynman, R. P. Simulating physics with computers. Int. J. Theor. Phys.21, 467–488 (1982).
LinkOut - more resources
Full Text Sources
