

Avoiding common machine learning pitfalls
- PMID: 39569205
- PMCID: PMC11573893
- DOI: 10.1016/j.patter.2024.101046
Avoiding common machine learning pitfalls
Abstract
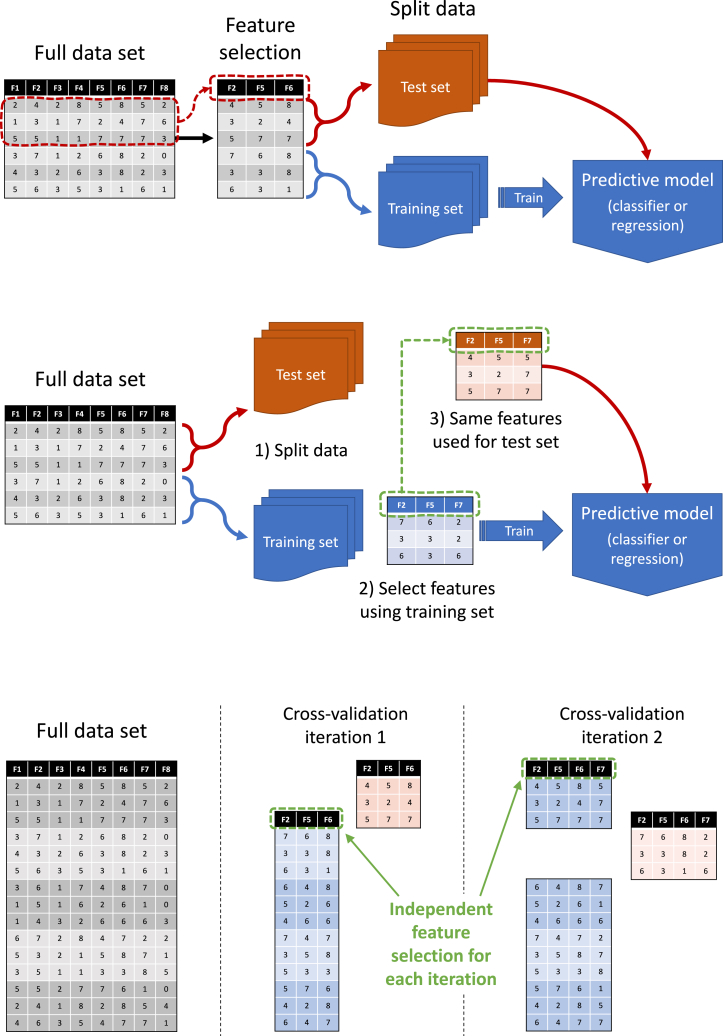
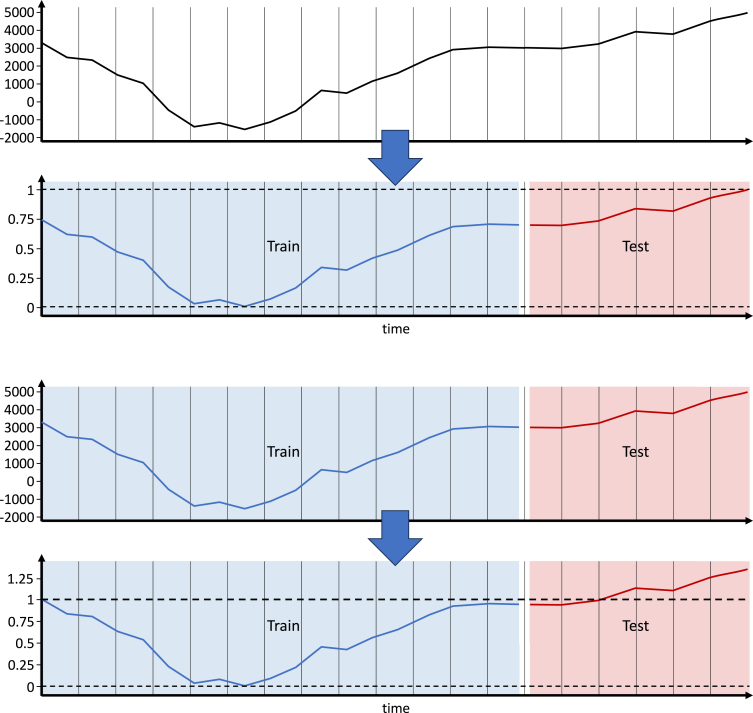
Mistakes in machine learning practice are commonplace and can result in loss of confidence in the findings and products of machine learning. This tutorial outlines common mistakes that occur when using machine learning and what can be done to avoid them. While it should be accessible to anyone with a basic understanding of machine learning techniques, it focuses on issues that are of particular concern within academic research, such as the need to make rigorous comparisons and reach valid conclusions. It covers five stages of the machine learning process: what to do before model building, how to reliably build models, how to robustly evaluate models, how to compare models fairly, and how to report results.
Keywords: guidance; machine learning; practice.
© 2024 The Author(s).
Conflict of interest statement
The author declares no competing interests.
Figures






References
-
- Liao T., Taori R., Raji I.D., Schmidt L. Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) 2021. Are we learning yet? A meta review of evaluation failures across machine learning.https://openreview.net/forum?id=mPducS1MsEK
Publication types
LinkOut - more resources
Full Text Sources
