

Simulated synapse loss induces depression-like behaviors in deep reinforcement learning
- PMID: 39569353
- PMCID: PMC11576168
- DOI: 10.3389/fncom.2024.1466364
Simulated synapse loss induces depression-like behaviors in deep reinforcement learning
Abstract
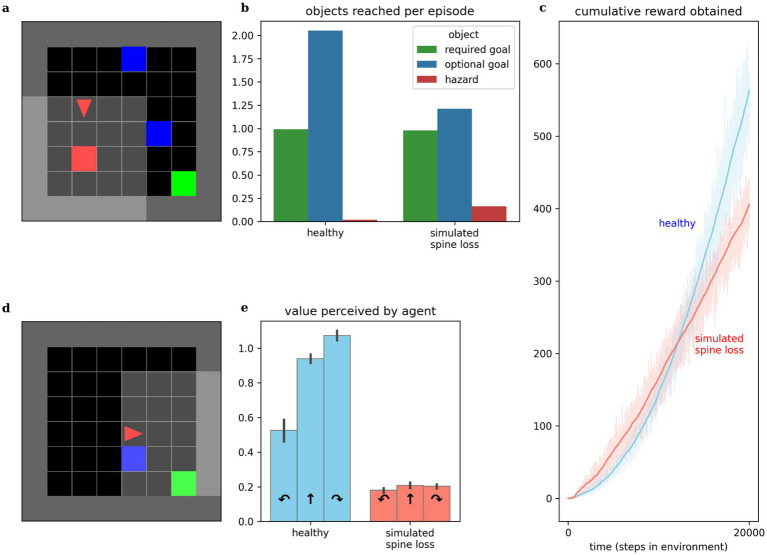
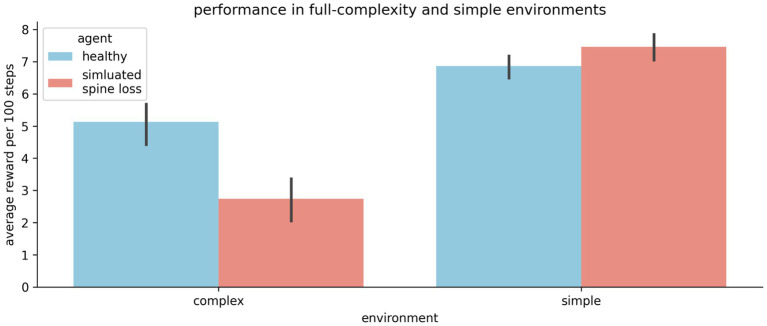
Deep Reinforcement Learning is a branch of artificial intelligence that uses artificial neural networks to model reward-based learning as it occurs in biological agents. Here we modify a Deep Reinforcement Learning approach by imposing a suppressive effect on the connections between neurons in the artificial network-simulating the effect of dendritic spine loss as observed in major depressive disorder (MDD). Surprisingly, this simulated spine loss is sufficient to induce a variety of MDD-like behaviors in the artificially intelligent agent, including anhedonia, increased temporal discounting, avoidance, and an altered exploration/exploitation balance. Furthermore, simulating alternative and longstanding reward-processing-centric conceptions of MDD (dysfunction of the dopamine system, altered reward discounting, context-dependent learning rates, increased exploration) does not produce the same range of MDD-like behaviors. These results support a conceptual model of MDD as a reduction of brain connectivity (and thus information-processing capacity) rather than an imbalance in monoamines-though the computational model suggests a possible explanation for the dysfunction of dopamine systems in MDD. Reversing the spine-loss effect in our computational MDD model can lead to rescue of rewarding behavior under some conditions. This supports the search for treatments that increase plasticity and synaptogenesis, and the model suggests some implications for their effective administration.
Keywords: major depressive disorder; monoamine hypothesis; neuroplasticity; psychedelics; reinforcement learning; reward prediction error.
Copyright © 2024 Chalmers, Duarte, Al-Hejji, Devoe, Gruber and McDonald.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures






References
-
- American Psychiatric Association (2022). Diagnostic and statistical manual of mental disorders. DSM-5-TR. Edn. Washington, DC: American Psychiatric Association Publishing.
-
- Andriushchenko M., D’Angelo F., Varre A., Flammarion N., (2023). Why do we need weight decay in modern deep learning? doi: 10.48550/arXiv.2310.04415 - DOI
LinkOut - more resources
Full Text Sources