

ULTRA-effective labeling of tandem repeats in genomic sequence
- PMID: 39575229
- PMCID: PMC11580682
- DOI: 10.1093/bioadv/vbae149
ULTRA-effective labeling of tandem repeats in genomic sequence
Abstract
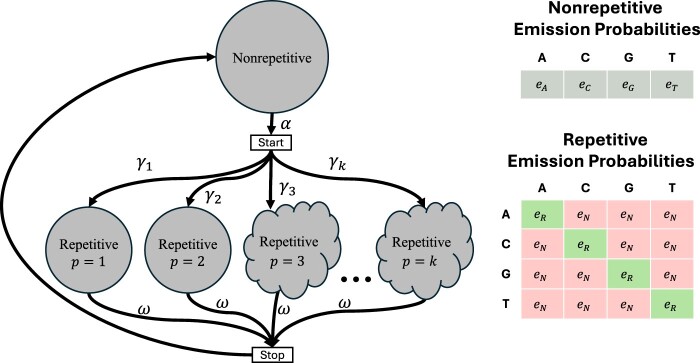
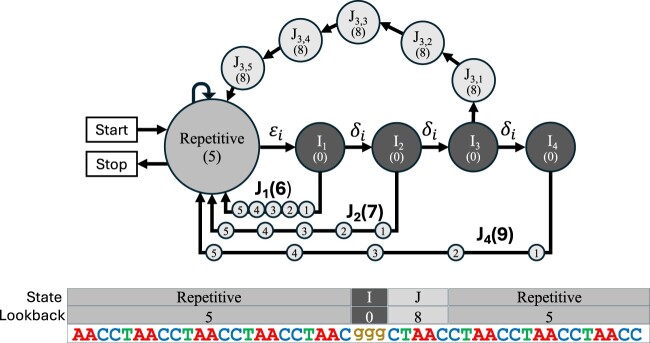
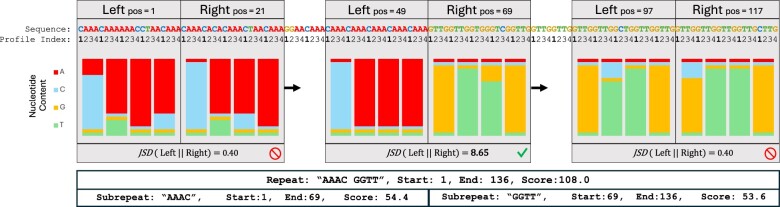
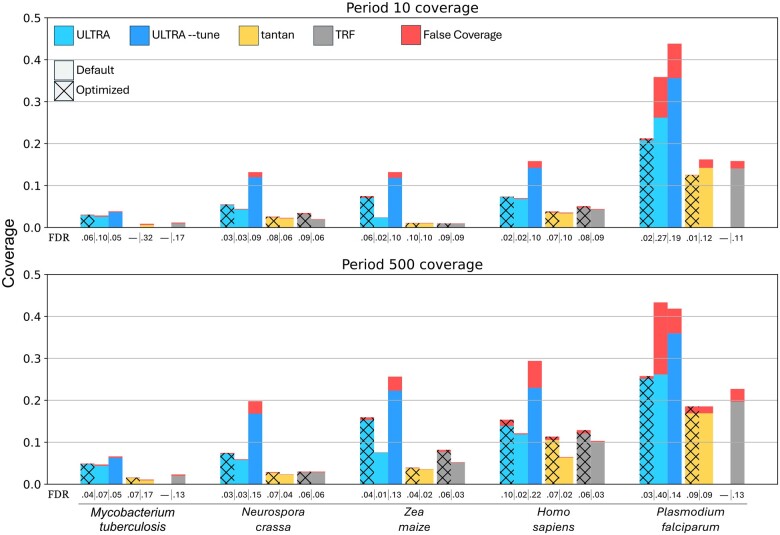
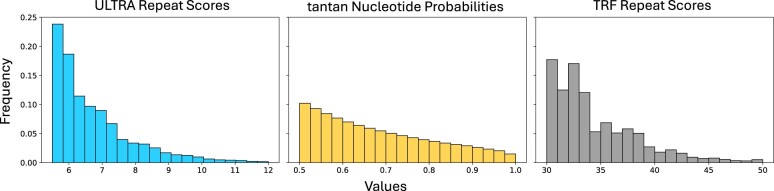
In the age of long read sequencing, genomics researchers now have access to accurate repetitive DNA sequence (including satellites) that, due to the limitations of short read-sequencing, could previously be observed only as unmappable fragments. Tools that annotate repetitive sequence are now more important than ever, so that we can better understand newly uncovered repetitive sequences, and also so that we can mitigate errors in bioinformatic software caused by those repetitive sequences. To that end, we introduce the 1.0 release of our tool for identifying and annotating locally repetitive sequence, ULTRA Locates Tandemly Repetitive Areas (ULTRA). ULTRA is fast enough to use as part of an efficient annotation pipeline, produces state-of-the-art reliable coverage of repetitive regions containing many mutations, and provides interpretable statistics and labels for repetitive regions.
Availability and implementation: ULTRA is released under an open source license, and is available for download at https://github.com/TravisWheelerLab/ULTRA.
© The Author(s) 2024. Published by Oxford University Press.
Conflict of interest statement
None declared.
Figures
Update of
-
ULTRA-Effective Labeling of Repetitive Genomic Sequence.bioRxiv [Preprint]. 2024 Jun 4:2024.06.03.597269. doi: 10.1101/2024.06.03.597269. bioRxiv. 2024. Update in: Bioinform Adv. 2024 Oct 09;4(1):vbae149. doi: 10.1093/bioadv/vbae149. PMID: 38895435 Free PMC article. Updated. Preprint.
References
-
- Altschul SF, Gish W, Miller W. et al. Basic local alignment search tool. J Mol Biol 1990;215:403–10. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
