

Large language models surpass human experts in predicting neuroscience results
- PMID: 39604572
- PMCID: PMC11860209
- DOI: 10.1038/s41562-024-02046-9
Large language models surpass human experts in predicting neuroscience results
Abstract
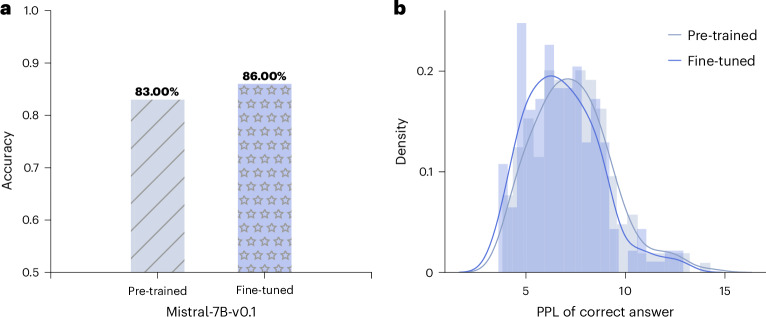
Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. Here, to evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs indicated high confidence in their predictions, their responses were more likely to be correct, which presages a future where LLMs assist humans in making discoveries. Our approach is not neuroscience specific and is transferable to other knowledge-intensive endeavours.
© 2024. The Author(s).
Conflict of interest statement
Competing interests: The authors declare no competing interests.
Figures



References
-
- Bornmann, L. & Mutz, R. Growth rates of modern science: a bibliometric analysis based on the number of publications and cited references. J. Assoc. Inf. Sci. Technol.66, 2215–2222 (2015).
-
- Zhavoronkov, A. et al. Deep learning enables rapid identification of potent DDR1 kinase inhibitors. Nat. Biotechnol.37, 1038–1040 (2019). - PubMed
-
- Tshitoyan, V. et al. Unsupervised word embeddings capture latent knowledge from materials science literature. Nature571, 95–98 (2019). - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
