

Large language models improve clinical decision making of medical students through patient simulation and structured feedback: a randomized controlled trial
- PMID: 39609823
- PMCID: PMC11605890
- DOI: 10.1186/s12909-024-06399-7
Large language models improve clinical decision making of medical students through patient simulation and structured feedback: a randomized controlled trial
Abstract
Background: Clinical decision-making (CDM) refers to physicians' ability to gather, evaluate, and interpret relevant diagnostic information. An integral component of CDM is the medical history conversation, traditionally practiced on real or simulated patients. In this study, we explored the potential of using Large Language Models (LLM) to simulate patient-doctor interactions and provide structured feedback.
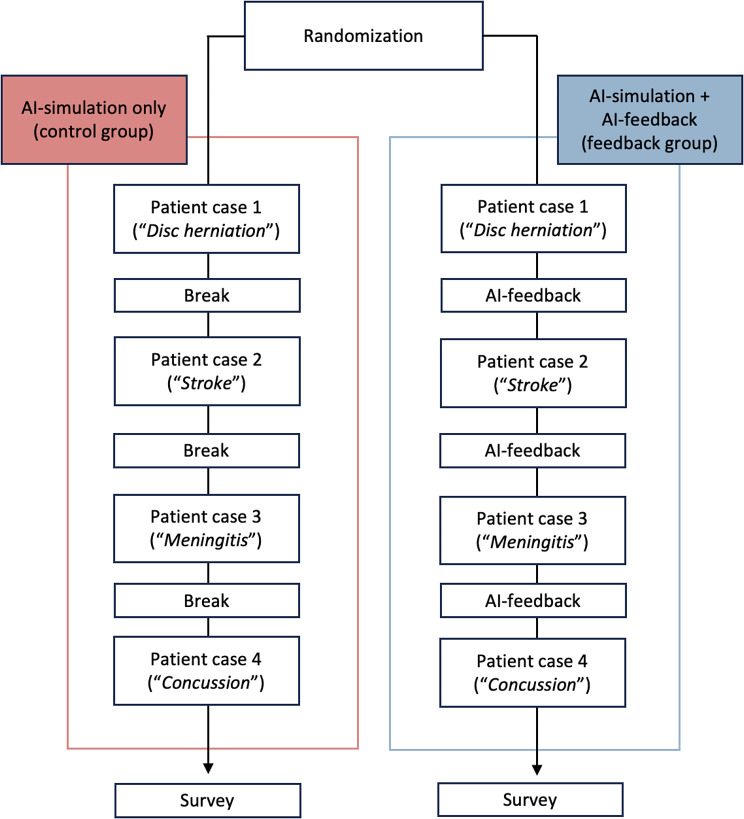
Methods: We developed AI prompts to simulate patients with different symptoms, engaging in realistic medical history conversations. In our double-blind randomized design, the control group participated in simulated medical history conversations with AI patients (control group), while the intervention group, in addition to simulated conversations, also received AI-generated feedback on their performances (feedback group). We examined the influence of feedback based on their CDM performance, which was evaluated by two raters (ICC = 0.924) using the Clinical Reasoning Indicator - History Taking Inventory (CRI-HTI). The data was analyzed using an ANOVA for repeated measures.
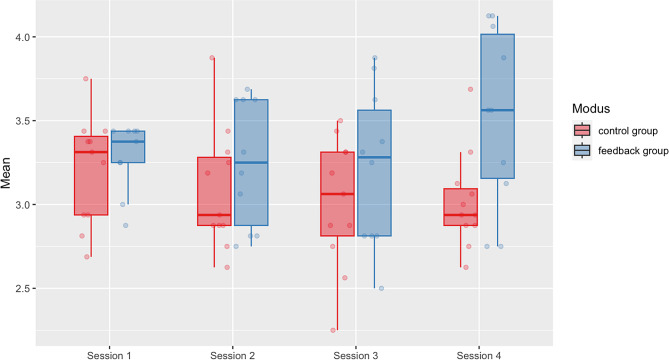
Results: Our final sample included 21 medical students (agemean = 22.10 years, semestermean = 4, 14 females). At baseline, the feedback group (mean = 3.28 ± 0.09 [standard deviation]) and the control group (3.21 ± 0.08) achieved similar CRI-HTI scores, indicating successful randomization. After only four training sessions, the feedback group (3.60 ± 0.13) outperformed the control group (3.02 ± 0.12), F (1,18) = 4.44, p = .049 with a strong effect size, partial η2 = 0.198. Specifically, the feedback group showed improvements in the subdomains of CDM of creating context (p = .046) and securing information (p = .018), while their ability to focus questions did not improve significantly (p = .265).
Conclusion: The results suggest that AI-simulated medical history conversations can support CDM training, especially when combined with structured feedback. Such training format may serve as a cost-effective supplement to existing training methods, better preparing students for real medical history conversations.
Keywords: Clinical decision making; Large language models; Medical students education; Patient simulation training; Structured feedback.
© 2024. The Author(s).
Conflict of interest statement
Declarations. Ethics approval and consent to participate: Ethics approval was obtained from the ethics board (“Ethik-Kommission Westfalen-Lippe”) under the reference 2023-438-f-N. Informed consent was obtained from all participants. Consent for publication: Not applicable. Competing interests: The authors declare no competing interests.
Figures


References
-
- Macauley K, Brudvig T, Kadakia M, Bonneville M. Systematic review of assessments that evaluate clinical decision making, clinical reasoning, and critical thinking changes after simulation participation. J Phys Ther Educ. 2017;31(4):64–75. 10.1097/JTE.0000000000000011. - DOI
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
