

Innovation and application of Large Language Models (LLMs) in dentistry - a scoping review
- PMID: 39617779
- PMCID: PMC11609263
- DOI: 10.1038/s41405-024-00277-6
Innovation and application of Large Language Models (LLMs) in dentistry - a scoping review
Abstract
Objective: Large Language Models (LLMs) have revolutionized healthcare, yet their integration in dentistry remains underexplored. Therefore, this scoping review aims to systematically evaluate current literature on LLMs in dentistry.
Data sources: The search covered PubMed, Scopus, IEEE Xplore, and Google Scholar, with studies selected based on predefined criteria. Data were extracted to identify applications, evaluation metrics, prompting strategies, and deployment levels of LLMs in dental practice.
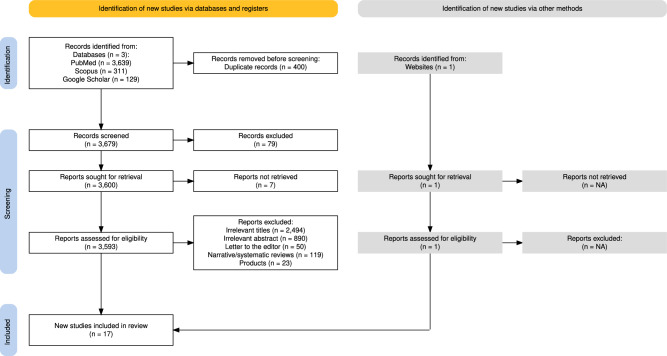
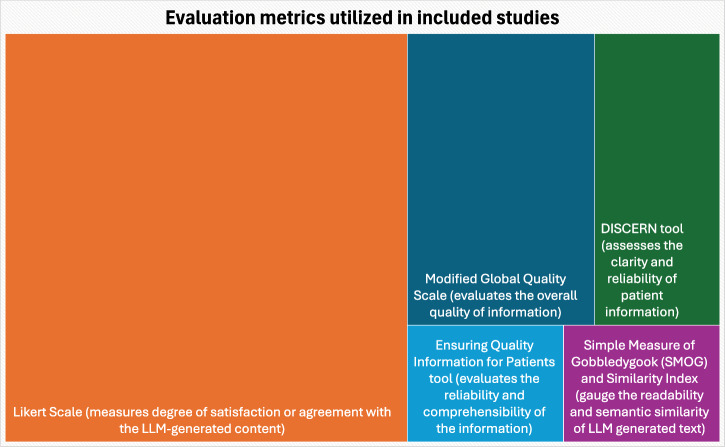
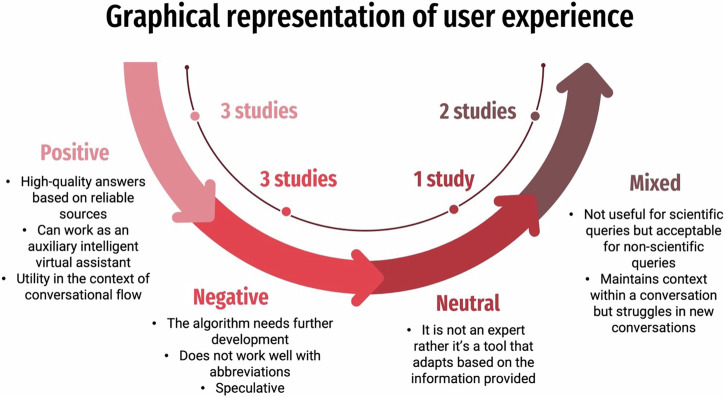
Results: From 4079 records, 17 studies met the inclusion criteria. ChatGPT was the predominant model, mainly used for post-operative patient queries. Likert scale was the most reported evaluation metric, and only two studies employed advanced prompting strategies. Most studies were at level 3 of deployment, indicating practical application but requiring refinement.
Conclusion: LLMs showed extensive applicability in dental specialties; however, reliance on ChatGPT necessitates diversified assessments across multiple LLMs. Standardizing reporting practices and employing advanced prompting techniques are crucial for transparency and reproducibility, necessitating continuous efforts to optimize LLM utility and address existing challenges.
© 2024. The Author(s).
Conflict of interest statement
Ethical approval: Ethical approval was not necessary because the scoping review utilized research data that are publicly available, and without involving human participants or identifiable personal data. Competing interests: The authors declare no competing interests.
Figures
References
-
- Topol EJ. High-performance medicine: the convergence of human and artificial intelligence. Nat Med. 2019;25:44–56. - PubMed
-
- Purushotham S, Meng C, Che Z, Liu Y. Benchmarking deep learning models on large healthcare datasets. J Biomed Inf. 2018;83:112–34. - PubMed
-
- Thirunavukarasu AJ, Ting DSJ, Elangovan K, Gutierrez L, Tan TF, Ting DSW. Large language models in medicine. Nat Med. 2023;29:1930–40. - PubMed
Publication types
LinkOut - more resources
Full Text Sources
Miscellaneous
