

Models optimized for real-world tasks reveal the task-dependent necessity of precise temporal coding in hearing
- PMID: 39632854
- PMCID: PMC11618365
- DOI: 10.1038/s41467-024-54700-5
Models optimized for real-world tasks reveal the task-dependent necessity of precise temporal coding in hearing
Abstract
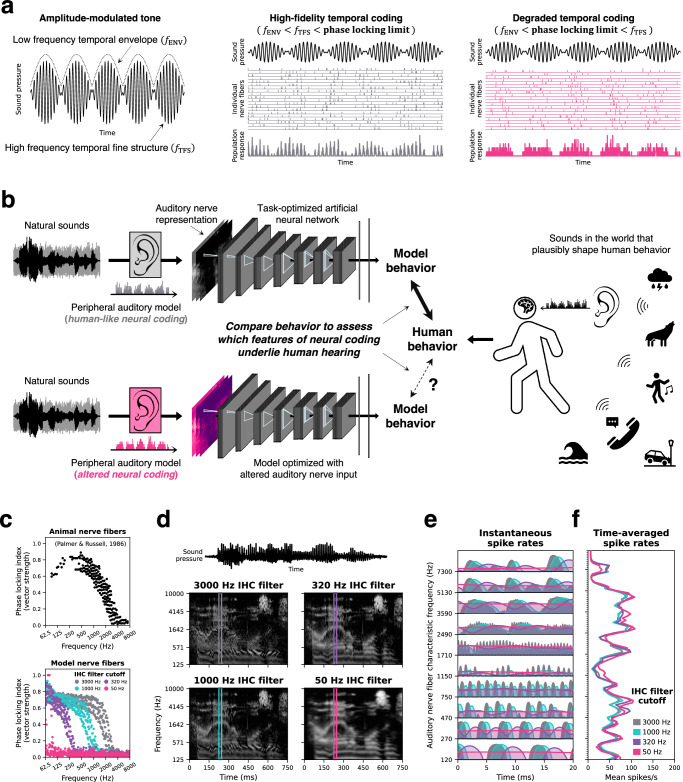
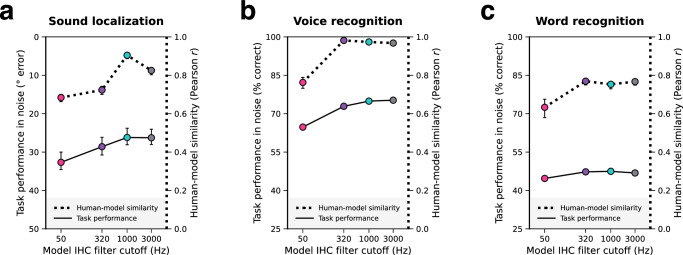
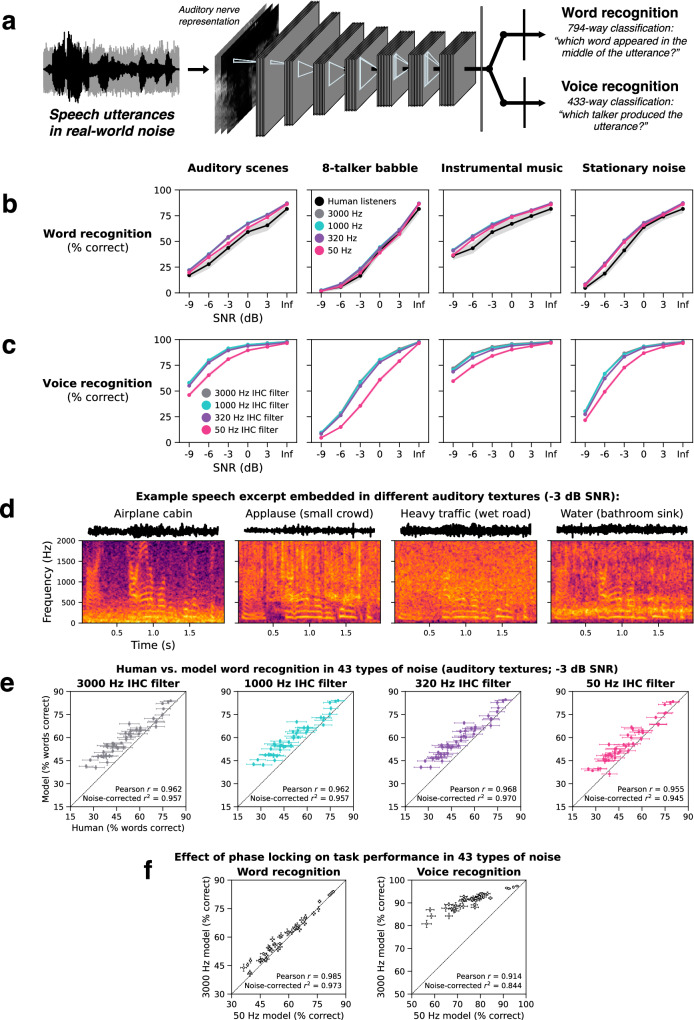
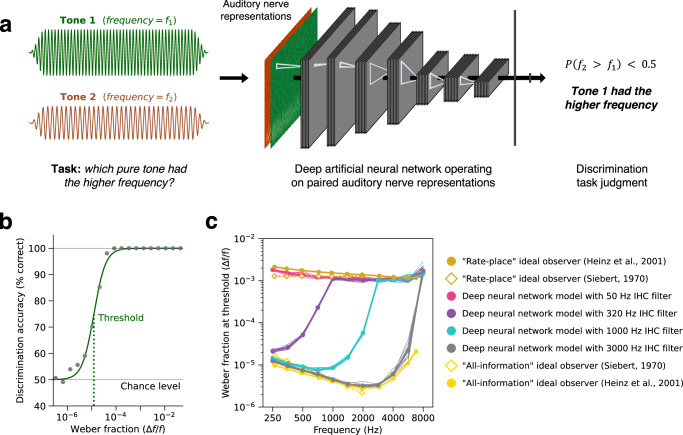
Neurons encode information in the timing of their spikes in addition to their firing rates. Spike timing is particularly precise in the auditory nerve, where action potentials phase lock to sound with sub-millisecond precision, but its behavioral relevance remains uncertain. We optimized machine learning models to perform real-world hearing tasks with simulated cochlear input, assessing the precision of auditory nerve spike timing needed to reproduce human behavior. Models with high-fidelity phase locking exhibited more human-like sound localization and speech perception than models without, consistent with an essential role in human hearing. However, the temporal precision needed to reproduce human-like behavior varied across tasks, as did the precision that benefited real-world task performance. These effects suggest that perceptual domains incorporate phase locking to different extents depending on the demands of real-world hearing. The results illustrate how optimizing models for realistic tasks can clarify the role of candidate neural codes in perception.
© 2024. The Author(s).
Conflict of interest statement
Competing interests: The authors declare no competing interests.
Figures




Update of
-
Models optimized for real-world tasks reveal the task-dependent necessity of precise temporal coding in hearing.bioRxiv [Preprint]. 2024 Sep 16:2024.04.21.590435. doi: 10.1101/2024.04.21.590435. bioRxiv. 2024. Update in: Nat Commun. 2024 Dec 4;15(1):10590. doi: 10.1038/s41467-024-54700-5. PMID: 38712054 Free PMC article. Updated. Preprint.
References
-
- Green, D. M. & Swets, J. A. Signal Detection Theory and Psychophysics Vol. 455 (John Wiley, Oxford, England, 1966).
-
- Siebert, W. M. Frequency discrimination in the auditory system: place or periodicity mechanisms? Proc. IEEE58, 723–730 (1970). - DOI
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
